這兩年開始畢業設計和畢業答辯的要求和難度不斷提升,傳統的畢設題目缺少創新和亮點,往往達不到畢業答辯的要求,這兩年不斷有學弟學妹告訴學長自己做的項目系統達不到老師的要求。
為了大家能夠順利以及最少的精力通過畢設,學長分享優質畢業設計項目,今天要分享的是
基於深度學習的動物識別算法研究與實現
學長這裡給一個題目綜合評分(每項滿分5分)
🧿 選題指導, 項目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
學長實現的動態檢測效果,精度還是非常高的!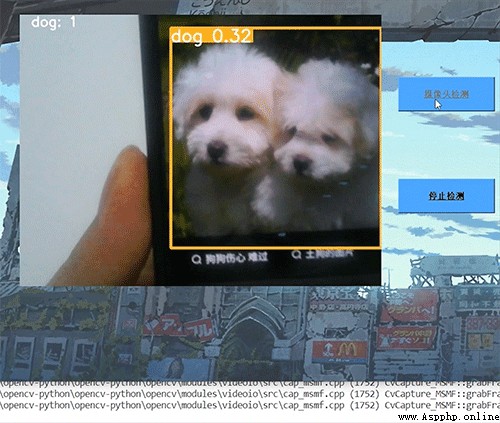
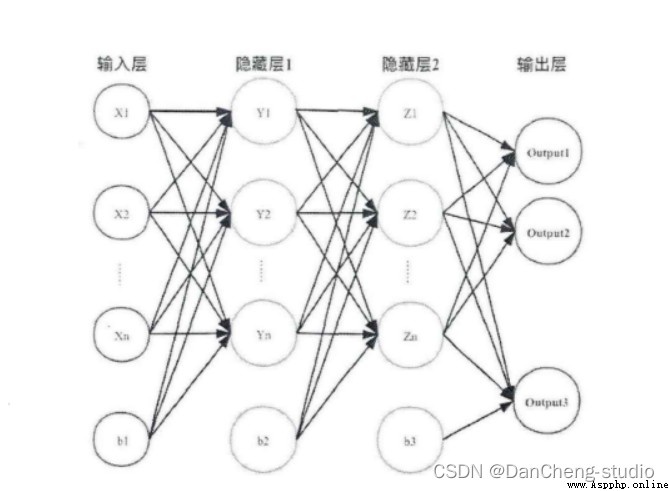
受到人類大腦神經突觸結構相互連接的模式啟發,神經網絡作為人工智能領域的重要組成部分,通過分布式的方法處理信息,可以解決復雜的非線性問題,從構造方面來看,主要包括輸入層、隱藏層、輸出層三大組成結構。每一個節點被稱為一個神經元,存在著對應的權重參數,部分神經元存在偏置,當輸入數據x進入後,對於經過的神經元都會進行類似於:y=w*x+b的線性函數的計算,其中w為該位置神經元的權值,b則為偏置函數。通過每一層神經元的邏輯運算,將結果輸入至最後一層的激活函數,最後得到輸出output。
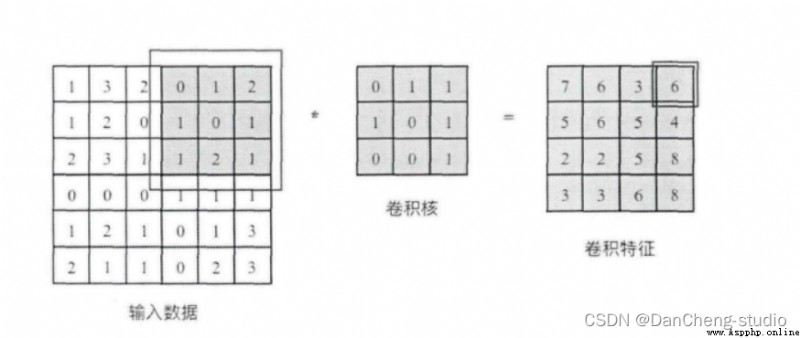
卷積核相當於一個滑動窗口,示意圖中3x3大小的卷積核依次劃過6x6大小的輸入數據中的對應區域,並與卷積核滑過區域做矩陣點乘,將所得結果依次填入對應位置即可得到右側4x4尺寸的卷積特征圖,例如劃到右上角3x3所圈區域時,將進行0x0+1x1+2x1+1x1+0x0+1x1+1x0+2x0x1x1=6的計算操作,並將得到的數值填充到卷積特征的右上角。
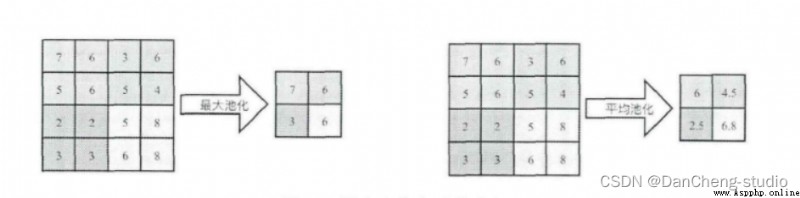
池化操作又稱為降采樣,提取網絡主要特征可以在達到空間不變性的效果同時,有效地減少網絡參數,因而簡化網絡計算復雜度,防止過擬合現象的出現。在實際操作中經常使用最大池化或平均池化兩種方式,如下圖所示。雖然池化操作可以有效的降低參數數量,但過度池化也會導致一些圖片細節的丟失,因此在搭建網絡時要根據實際情況來調整池化操作。
激活函數大致分為兩種,在卷積神經網絡的發展前期,使用較為傳統的飽和激活函數,主要包括sigmoid函數、tanh函數等;隨著神經網絡的發展,研宄者們發現了飽和激活函數的弱點,並針對其存在的潛在問題,研宄了非飽和激活函數,其主要含有ReLU函數及其函數變體
在整個網絡結構中起到“分類器”的作用,經過前面卷積層、池化層、激活函數層之後,網絡己經對輸入圖片的原始數據進行特征提取,並將其映射到隱藏特征空間,全連接層將負責將學習到的特征從隱藏特征空間映射到樣本標記空間,一般包括提取到的特征在圖片上的位置信息以及特征所屬類別概率等。將隱藏特征空間的信息具象化,也是圖像處理當中的重要一環。
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷積層神經元(卷積核)數目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函數
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
我們選擇當下YOLO最新的卷積神經網絡YOLOv5來進行火焰識別檢測。6月9日,Ultralytics公司開源了YOLOv5,離上一次YOLOv4發布不到50天。而且這一次的YOLOv5是完全基於PyTorch實現的!在我們還對YOLOv4的各種高端操作、豐富的實驗對比驚歎不已時,YOLOv5又帶來了更強實時目標檢測技術。按照官方給出的數目,現版本的YOLOv5每個圖像的推理時間最快0.007秒,即每秒140幀(FPS),但YOLOv5的權重文件大小只有YOLOv4的1/9。
目標檢測架構分為兩種,一種是two-stage,一種是one-stage,區別就在於 two-stage 有region proposal過程,類似於一種海選過程,網絡會根據候選區域生成位置和類別,而one-stage直接從圖片生成位置和類別。今天提到的 YOLO就是一種 one-stage方法。YOLO是You Only Look Once的縮寫,意思是神經網絡只需要看一次圖片,就能輸出結果。YOLO 一共發布了五個版本,其中 YOLOv1 奠定了整個系列的基礎,後面的系列就是在第一版基礎上的改進,為的是提升性能。
YOLOv5有4個版本性能如圖所示:
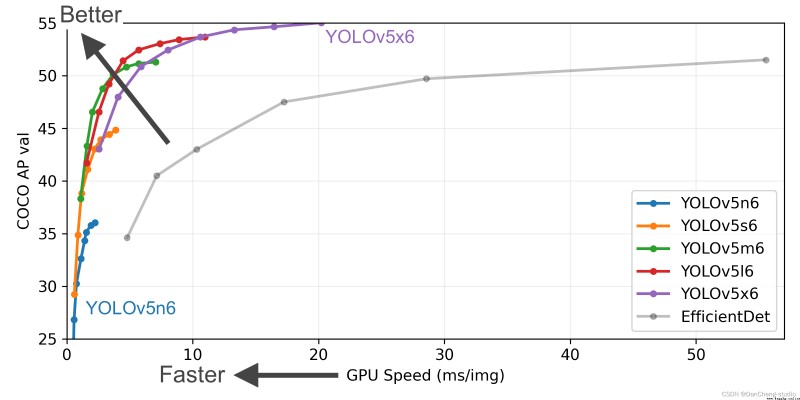
YOLOv5是一種單階段目標檢測算法,該算法在YOLOv4的基礎上添加了一些新的改進思路,使其速度與精度都得到了極大的性能提升。主要的改進思路如下所示:
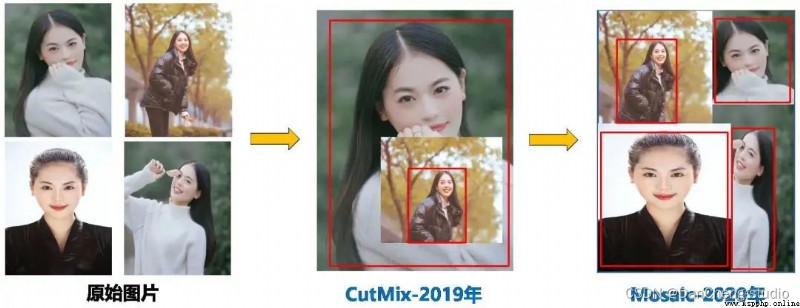
在模型訓練階段,提出了一些改進思路,主要包括Mosaic數據增強、自適應錨框計算、自適應圖片縮放;
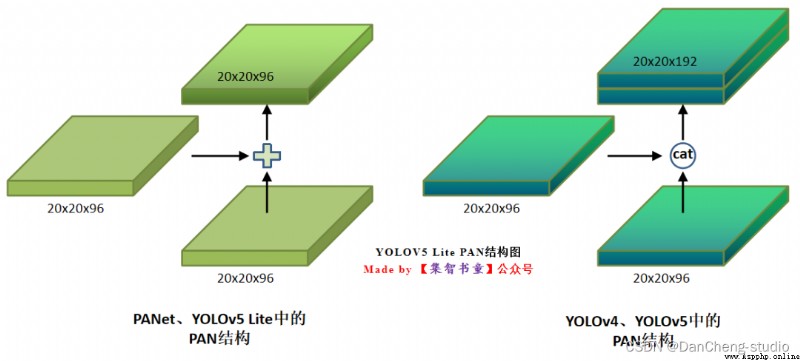
融合其它檢測算法中的一些新思路,主要包括:Focus結構與CSP結構;
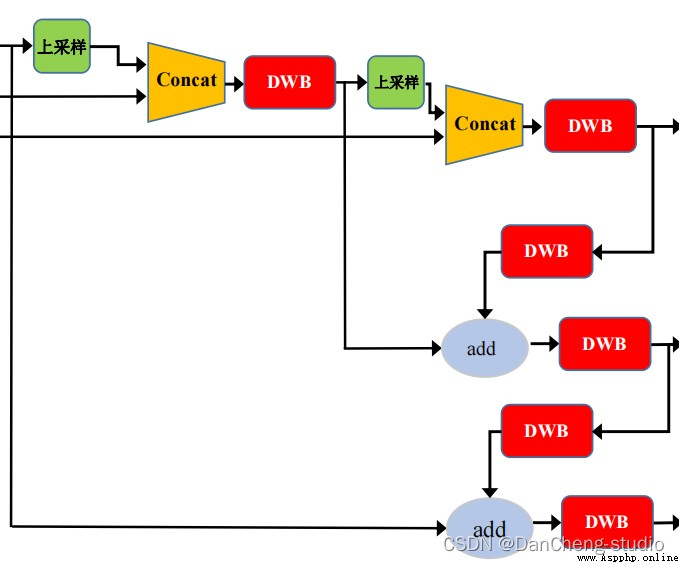
在目標檢測領域,為了更好的提取融合特征,通常在Backbone和輸出層,會插入一些層,這個部分稱為Neck。Yolov5中添加了FPN+PAN結構,相當於目標檢測網絡的頸部,也是非常關鍵的。
FPN+PAN的結構
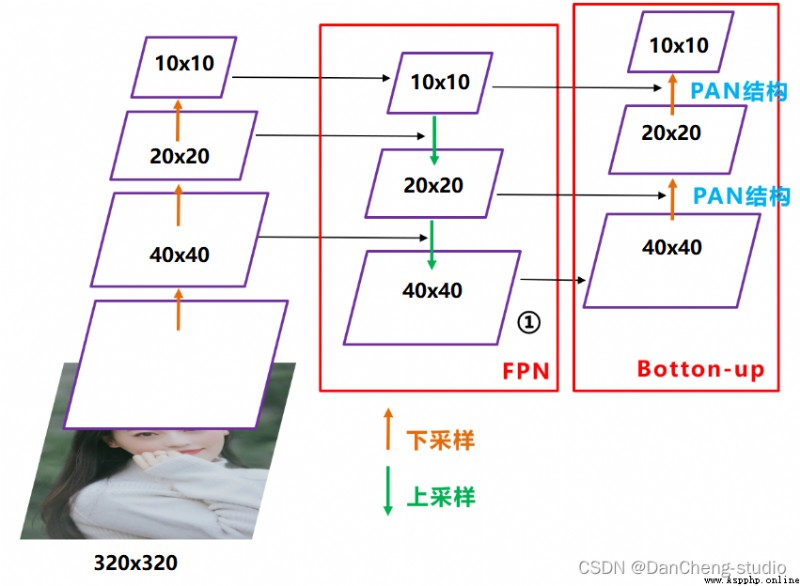
這樣結合操作,FPN層自頂向下傳達強語義特征(High-Level特征),而特征金字塔則自底向上傳達強定位特征(Low-Level特征),兩兩聯手,從不同的主干層對不同的檢測層進行特征聚合。
FPN+PAN借鑒的是18年CVPR的PANet,當時主要應用於圖像分割領域,但Alexey將其拆分應用到Yolov4中,進一步提高特征提取的能力。
輸出層的錨框機制與YOLOv4相同,主要改進的是訓練時的損失函數GIOU_Loss,以及預測框篩選的DIOU_nms。
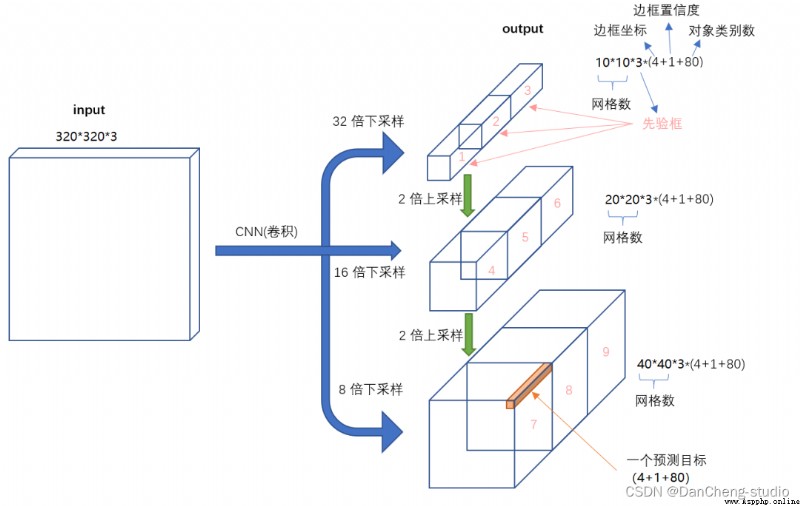
對於Head部分,可以看到三個紫色箭頭處的特征圖是40×40、20×20、10×10。以及最後Prediction中用於預測的3個特征圖:
①==>40×40×255
②==>20×20×255
③==>10×10×255
相關代碼
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')
else:
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
由於目前針對多源場景下的火焰數據並沒有現成的數據集,我們使用使用Python爬蟲利用關鍵字在互聯網上獲得的圖片數據,爬取數據包含室內場景下的火焰、寫字樓和房屋燃燒、森林火災和車輛燃燒等場景下的火焰圖片。經過篩選後留下3000張質量較好的圖片制作成VOC格式的實驗數據集。
深度學習圖像標注軟件眾多,按照不同分類標准有多中類型,本文使用LabelImg單機標注軟件進行標注。LabelImg是基於角點的標注方式產生邊界框,對圖片進行標注得到xml格式的標注文件,由於邊界框對檢測精度的影響較大因此采用手動標注,並沒有使用自動標注軟件。
考慮到有的朋友時間不足,博主提供了標注好的數據集和訓練好的模型,需要請聯系。
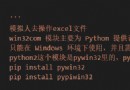
通過pip指令即可安裝
pip install labelimg
在命令行中輸入labelimg即可打開
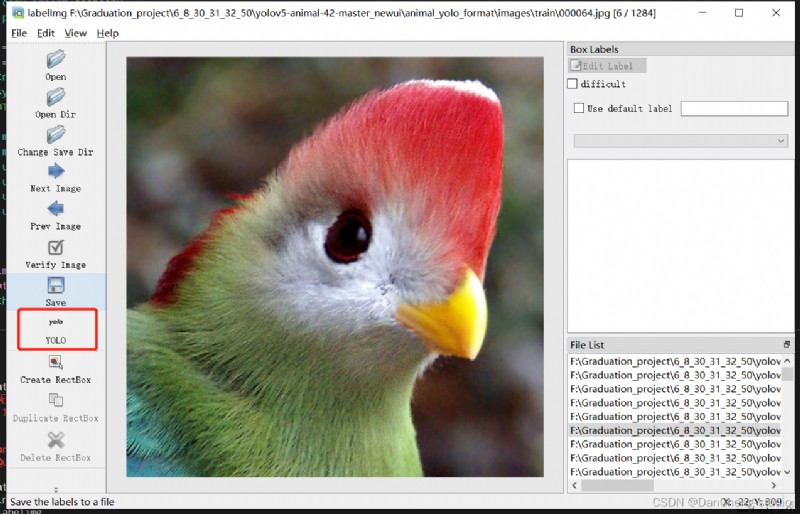
打開你所需要進行標注的文件夾,點擊紅色框區域進行標注格式切換,我們需要yolo格式,因此切換到yolo
點擊Create RectBo -> 拖拽鼠標框選目標 -> 給上標簽 -> 點擊ok
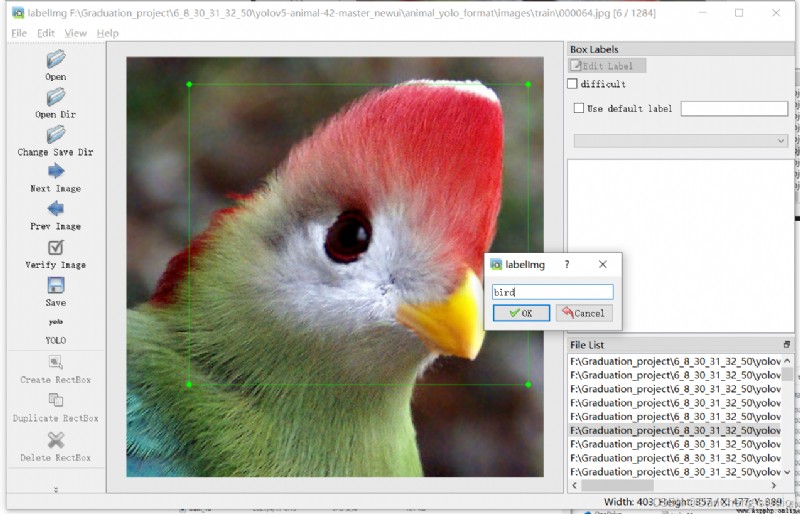
點擊save,保存txt。
打開具體的標注文件,你將會看到下面的內容,txt文件中每一行表示一個目標,以空格進行區分,分別表示目標的類別id,歸一化處理之後的中心點x坐標、y坐標、目標框的w和h。

預訓練模型和數據集都准備好了,就可以開始訓練自己的yolov5目標檢測模型了,訓練目標檢測模型需要修改兩個yaml文件中的參數。一個是data目錄下的相應的yaml文件,一個是model目錄文件下的相應的yaml文件。
修改data目錄下的相應的yaml文件。找到目錄下的voc.yaml文件,將該文件復制一份,將復制的文件重命名,最好和項目相關,這樣方便後面操作。我這裡修改為animal_data.yaml。
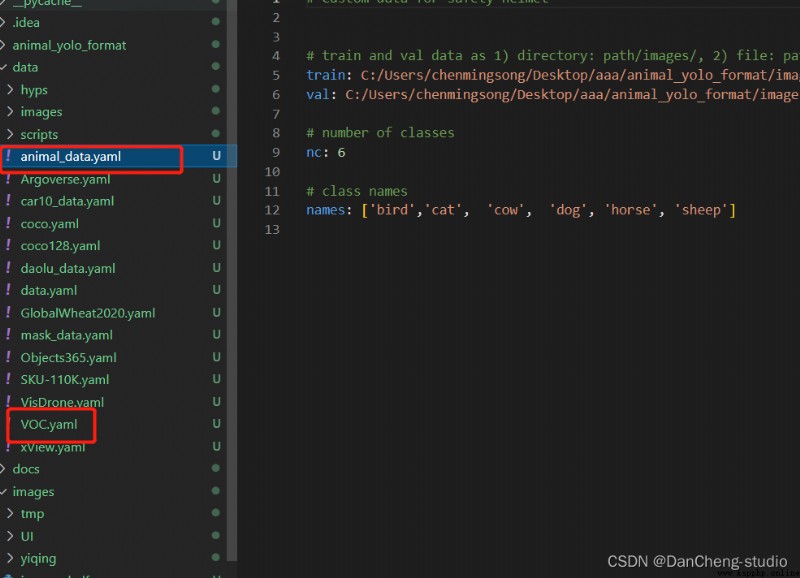
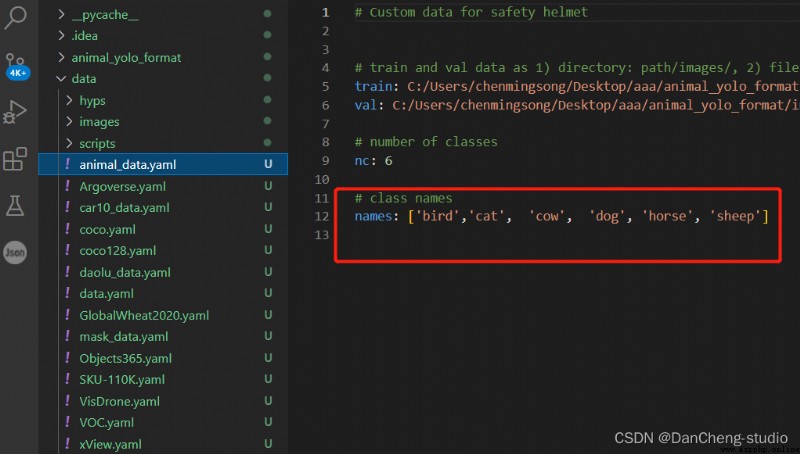
打開這個文件夾修改其中的參數,需要檢測的類別數,這裡識別有6種動物,所以這裡填寫6;最後填寫需要識別的類別的名字(必須是英文,否則會亂碼識別不出來)。到這裡和data目錄下的yaml文件就修改好了。
由於該項目使用的是yolov5s.pt這個預訓練權重,所以要使用models目錄下的yolov5s.yaml文件中的相應參數(因為不同的預訓練權重對應著不同的網絡層數,所以用錯預訓練權重會報錯)。同上修改data目錄下的yaml文件一樣,我們最好將yolov5s.yaml文件復制一份,然後將其重命名
打開yolov5s.yaml文件,主要是進去後修改nc這個參數來進行類別的修改,修改如圖中的數字就好了,這裡是識別兩個類別。
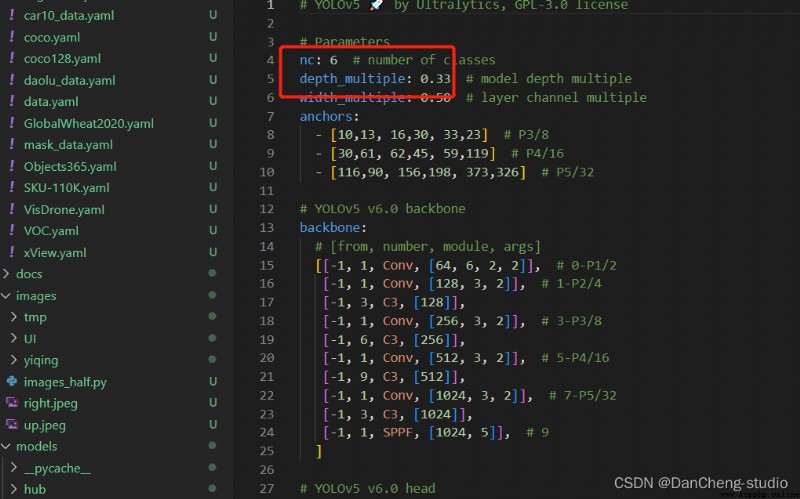
至此,相應的配置參數就修改好了。
目前支持的模型種類如下所示:
如果上面的數據集和兩個yaml文件的參數都修改好了的話,就可以開始yolov5的訓練了。首先我們找到train.py這個py文件。
然後找到主函數的入口,這裡面有模型的主要參數。修改train.py中的weights、cfg、data、epochs、batch_size、imgsz、device、workers等參數
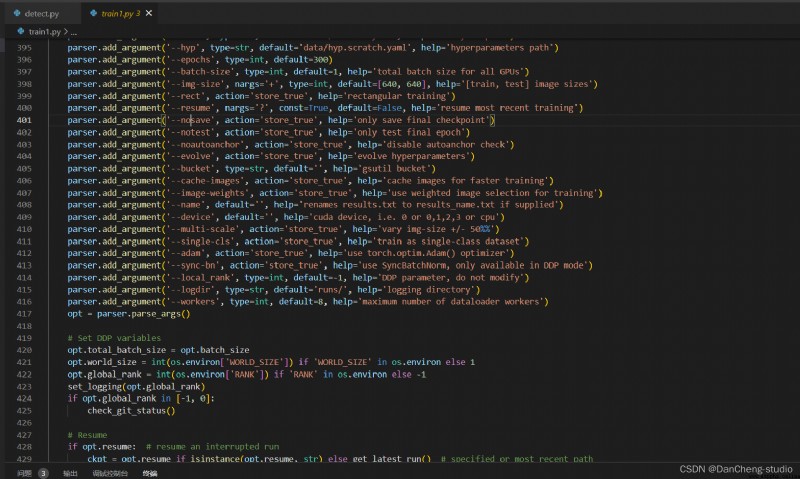
至此,就可以運行train.py函數訓練自己的模型了。
訓練代碼成功執行之後會在命令行中輸出下列信息,接下來就是安心等待模型訓練結束即可。

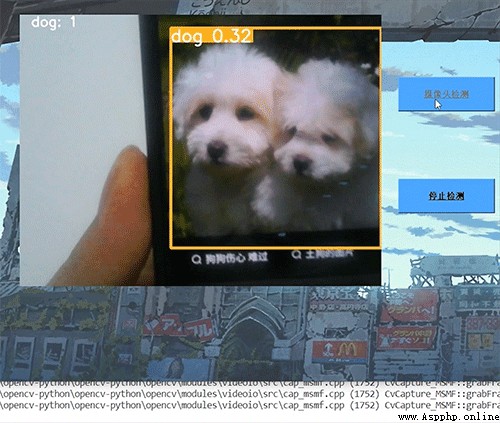
我們實現了圖片檢測,視頻檢測和攝像頭實時檢測接口,用Pyqt自制了簡單UI
#部分代碼
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_Win_animal(object):
def setupUi(self, Win_animal):
Win_animal.setObjectName("Win_animal")
Win_animal.resize(1107, 868)
Win_animal.setStyleSheet("QString qstrStylesheet = \"background-color:rgb(43, 43, 255)\";\n"
"ui.pushButton->setStyleSheet(qstrStylesheet);")
self.frame = QtWidgets.QFrame(Win_animal)
self.frame.setGeometry(QtCore.QRect(10, 140, 201, 701))
self.frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.frame.setObjectName("frame")
self.pushButton = QtWidgets.QPushButton(self.frame)
self.pushButton.setGeometry(QtCore.QRect(10, 40, 161, 51))
font = QtGui.QFont()
font.setBold(True)
font.setUnderline(True)
font.setWeight(75)
self.pushButton.setFont(font)
self.pushButton.setStyleSheet("QPushButton{background-color:rgb(151, 191, 255);}")
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(self.frame)
self.pushButton_2.setGeometry(QtCore.QRect(10, 280, 161, 51))
font = QtGui.QFont()
font.setBold(True)
font.setUnderline(True)
font.setWeight(75)
self.pushButton_2.setFont(font)
self.pushButton_2.setStyleSheet("QPushButton{background-color:rgb(151, 191, 255);}")
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_3 = QtWidgets.QPushButton(self.frame)
self.pushButton_3.setGeometry(QtCore.QRect(10, 500, 161, 51))
QtCore.QMetaObject.connectSlotsByName(Win_animal)


🧿 選題指導, 項目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md