《Python 快速入門(第3版)》娜奧米·賽德
4.3 變量和賦值
Python中的變量不是容器,而是指向Python對象的標簽,對象位於解釋器的命名空間中。任意數量的標簽(或變量)可以指向同一個對象。當對象發生變化時,所有指向它的變量的值都會改變。
新的賦值操作會覆蓋之前所有的賦值,del語句則會刪除變量。如果在刪除變量之後設法輸出該變量的內容,將會引發錯誤,效果就像從未創建過該變量一樣:
>>> x = 5
>>> print(x)
5
>>> del x
>>> print(x)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'x' is not defined
>>>
4.7 None值
檢測None是否存在十分簡單,因為在整個Python系統中只有1個None的實例,所有對None的引用都指向同一個對象,None只等價於它自身。
4.8 獲取用戶輸入
利用input()函數可以獲取用戶的輸入。input()函數可以帶一個字符串參數,作為顯示給用戶的提示信息。
用戶輸入是以字符串的形式獲得的,所以要想用作數字,必須用int()或float()函數進行轉換。
4.10 基本的Python編碼風格
A.3.2 代碼布局
1.縮進
每級縮進采用4個空格
3.最大行長
所有行都應限制在79個字符以內。
對於連續的大段文字(文檔字符串或注釋),建議將行長限制在72個字符以內。
長行進行換行的首選方案,是利用Python隱含的行連接特性,在圓括號、方括號和大括號內部進行斷行。必要時可以在表達式外面多加一對圓括號,不過有時候用反斜槓會更好看些。請確保對後續行進行適當的縮進。打斷二元運算符的首選位置是在運算符之後。
4.空行
頂級函數和類定義之間,請用兩個空行分隔。
類內部的各個方法定義之間,請用1個空行分隔。
5.
導入語句通常應單獨成行,例如
import os
import sys不過下面的寫法沒有問題:
from subprocess import Popen, PIPE導入語句應按照以下順序進行分組。
(1)標准庫的導入。
(2)相關第三方庫的導入。
(3)本地應用程序/庫——特定庫的導入。
每組導入語句之間請加入1個空行。
任何對應的__all__聲明都應位於導入語句之後。
非常不推薦對內部包的導入使用相對導入語法。請始終對所有導入都使用絕對包路徑。
6.表達式和語句內的空白符
以下場合應避免使用多余的空白符。
緊靠小括號、中括號或大括號內部。
緊挨著逗號、分號或冒號之前。
7.其它建議
始終在以下二元操作符兩側各放1個空格:賦值(=)、增量賦值(+=,-=等)、比較(==、<、>、!=、<>、<=、>=、in、not、in、is、is not)、布爾(and、or、not)。>> 在數學運算符兩側放置空格。
i = i + 1
submitted += 1
x = x * 2-1
hypot2 = x * x + y * y
c = (a + b) * (a - b)在用於指定關鍵字參數或默認參數值時,請勿在=兩邊使用空格。
def complex(real, imag=0.0):
return magic(r=real, i=imag)
通常不鼓勵使用復合語句,也就是在同一行放置多條語句。
5.2 列表的索引機制
如果第二個索引給出一個第一個索引之前的位置,會返回空列表;提供步長為-1可以逆序截取
>>> x = ["first","second","third","fourth"]
>>> x[-1:2]
[]
>>> x[-1:2:-1]
['fourth']
>>>如果兩個索引都省略了,可實現列表復制。對該列表副本修改不會影響原列表
>>> x
['first', 'second', 'third', 'fourth']
>>>
>>> y = x[:]
>>> y[0] = '1st'
>>> y
['1st', 'second', 'third', 'fourth']
>>> x
['first', 'second', 'third', 'fourth']
>>>5.3 修改列表
切片語法也可以這樣使用。類似lista[index1:index2]=listb的寫法,會導致lista在index1和index2之間的所有元素都被listb的元素替換掉。listb的元素數量可以多於或少於lista中被移除的元素數,這時lista的長度會自動做出調整。
利用切片賦值操作,可以實現很多功能,例如
(1)在列表末尾追加列表
>>> x = [1, 2, 3, 4]
>>> x[len(x):] = [5, 6, 7]
>>> x
[1, 2, 3, 4, 5, 6, 7]
>>>(2)在列表開頭插入列表
>>> x[:0] = [-1, 0]
>>> x
[-1, 0, 1, 2, 3, 4, 5, 6, 7]
>>>(3)移除列表元素
>>> x[2:-2] = []
>>> x
[-1, 0, 6, 7]
>>>extend方法和append方法類似,但是它能夠將列表追加到另一個列表之後
>>> y
['1st', 'second', 'third', 'fourth']
>>> x.extend(y)
>>> x
[-1, 0, 6, 7, '1st', 'second', 'third', 'fourth']
>>>進行了如下嘗試
x.extend(1) --> 會報錯,需要iterable的數據類型
x.extend('1') --> OK
x.extend([1]) --> OK
x.append('1') --> OK
x.append(1) --> OK
>>> x.extend(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>>大多數情況下,可將list.insert(n, elem)簡單地理解為,在列表的第n個元素之前插入elem。
當n是非負值時,list.insert(n, elem)與list[n:n] = [elem]的效果是一樣的。
刪除列表數據項或切片的推薦方法是使用del語句。
通常,del list[n]的功能與list[n:n+1] = []是一樣的,而del list[m:n]的功能則與list[m:n] = []相同。
remove則會先在列表中查找給定值的第一個實例,然後將該值從列表中刪除;
如果remove找不到要刪除的的值,就會引發錯誤。
列表的reverse方法是一種較為專業的列表修改方法,可以高效地將列表逆序
動手題:將列表最後3個數據項從列表的末尾移到開頭,並保持順序不變
>>> x
[-1, 0, 6, 7, '1st', 'second', 'third', 'fourth']
>>>
>>> x[:0] = x[-3:]
>>> x
['second', 'third', 'fourth', -1, 0, 6, 7, '1st', 'second', 'third', 'fourth']
>>> x[-3:] = []
>>> x
['second', 'third', 'fourth', -1, 0, 6, 7, '1st']
>>>5.4 對列表排序
sort方法會按排序修改列表。如果排序時不想修改原列表,可以有兩種做法:
一種是使用內置的sorted()函數;另一種是先建立列表的副本,再對副本進行排序
>>> x = [2, 4, 1, 3]
>>> y = x[:]
>>> y.sort()
>>> y
[1, 2, 3, 4]
>>> x
[2, 4, 1, 3]
>>> sorted(x)
[1, 2, 3, 4]
>>> x
[2, 4, 1, 3]
>>>sort方法可以帶有可選的reverse參數,當reverse=True時可以實現逆向排序
>>> y.sort(reverse=True)
>>> y
[4, 3, 2, 1]
>>>sort方法還可以用自定義的鍵函數來決定列表元素的順序
>>> def compare_num_of_chars(string1):
... return len(string1)
...
>>> word_list = ['Python', 'Java', 'PHP', 'Go', 'C++']
>>> word_list.sort()
>>> word_list
['C++', 'Go', 'Java', 'PHP', 'Python']
>>> word_list.sort(key=compare_num_of_chars)
>>> word_list
['Go', 'C++', 'PHP', 'Java', 'Python']
>>>動手題:列表排序假設有個列表的元素也都是列表:[[1, 2, 3], [2, 1, 3], [4, 0, 1]]。如果要按每個子列表的第二個元素對列表排序,結果應該為[[4, 0, 1], [2, 1, 3], [1, 2, 3]],那麼該如何為sort()方法的key參數編寫函數呢?
>>> def compare_2nd_ele(list1):
... return list1[1]
...
>>> testlist = [[1, 2, 3],[2, 1, 3],[4, 0, 11]]
>>> testlist.sort(key=compare_2nd_ele)
>>> testlist
[[4, 0, 11], [2, 1, 3], [1, 2, 3]]
>>>5.5 其他常用的列表操作
用*操作符初始化列表
>>> z = [None] * 4
>>> z
[None, None, None, None]
>>>用index方法搜索列表;在調用index方法之前,用in對列表進行測試。
>>> x
[2, 4, 1, 3]
>>>
>>> x.index(4)
1
>>> x.index(5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 5 is not in list
>>>
>>> 5 in x
False
>>> 4 in x
True
>>>
用count方法對匹配項計數
count也會遍歷列表並查找給定值,但返回的是在列表中找到該值的次數
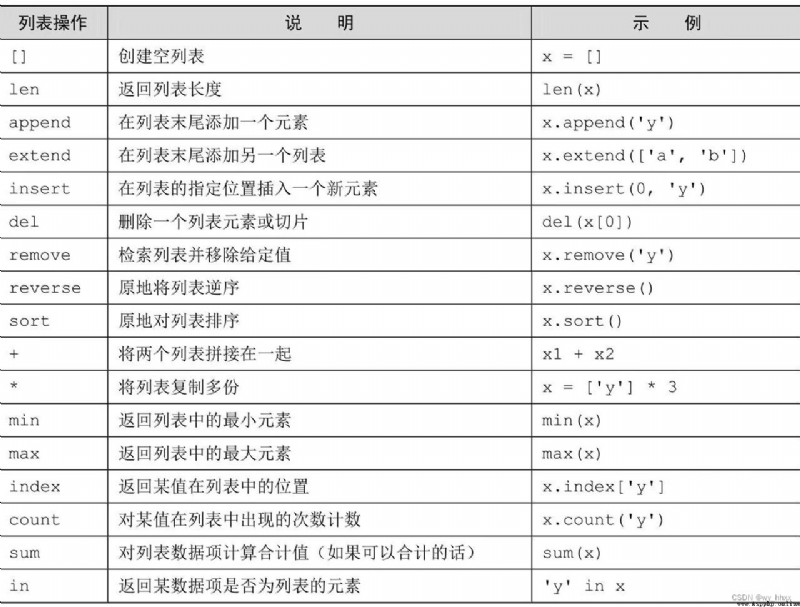
5.6 嵌套列表和深復制
通過全切片(即x[:])可以得到列表的副本,用+或*操作符(如x+[]或x*1)也可以得到列表的副本。但它們的效率略低於使用切片的方法。這3種方法都會創建所謂的淺副本(shallow copy)
如果列表中有嵌套列表,那就可能需要深副本(deep copy)。深副本可以通過copy模塊的deepcopy函數來得到,深副本完全與原變量無關,其變化對原列表沒有影響。
>>> original = [[0],1]
>>> shallow = original[:]
>>>
>>> import copy
>>> deep = copy.deepcopy(original)
>>>
>>> shallow[1] = 2
>>> shallow
[[0], 2]
>>>
>>> original
[[0], 1]
>>> shallow[0][0] = 'zero'
>>> original
[['zero'], 1]
>>>
>>> deep[0][0] = 5
>>> deep
[[5], 1]
>>>
>>> original
[['zero'], 1]
>>>5.7 元組
元組副本的創建方式,與列表完全相同:
交換兩個變量的值
var1, var2 = var2, var1
>>> a = 1
>>> b = 2
>>> a, b = b, a
>>> a
2
>>> b
1
>>>列表和元組的相互轉換
>>> x
[2, 4, 1, 3]
>>> y
[1, 2, 3, 4]
>>>
>>>
>>> x
[2, 4, 1, 3]
>>> tuple(x)
(2, 4, 1, 3)
>>>
>>> x
[2, 4, 1, 3]
>>> y=tuple(x)
>>>
>>> list(y)
[2, 4, 1, 3]
>>>
用list,很容易就能將字符串拆分為字符
>>> list('Kubernetes')
['K', 'u', 'b', 'e', 'r', 'n', 'e', 't', 'e', 's']
>>>
5.8 集合
集合中的項必須是不可變的、可散列的。這就表示,整數、浮點數、字符串和元組可以作為集合的成員,但列表、字典和集合本身不可以。
通過對序列(如列表)調用set函數,可以創建集合,重復的元素將會被移除。
用set函數創建集合後,可以用add和remove修改集合中的元素。
關鍵字in可用於檢查對象是否為集合的成員。
用操作符“|”可獲得兩個集合的並集;
用操作符“&”可獲得交集;
用操作符“^”則可以求得對稱差(symmetric difference),對稱差是指,屬於其中一個但不同時屬於兩個集合的元素。
集合類型frozenset,是不可變的、可散列的,因此可以作為其他集合的成員
6.4 字符串方法
6.4.1 字符串的split和join方法
>>> "::".join(["Separated", "with", "colons"])
'Separated::with::colons'
>>>
>>> 'Separated::with::colons'.split(":")
['Separated', '', 'with', '', 'colons']
>>> 'Separated::with::colons'.split("::")
['Separated', 'with', 'colons']
>>>
>>>
>>> '123 4 5 7 8 /t 999'.split()
['123', '4', '5', '7', '8', '/t', '999']
>>>
>>> '123 4 /n 5 7/n 8/t 999'.split()
['123', '4', '/n', '5', '7/n', '8/t', '999']
>>>可以用空字符串""來拼接字符串列表的元素:
>>> "".join(["Separated", "by", "nothing"])
'Separatedbynothing'
>>>通過給split方法傳入第二個可選參數來指定生成結果時執行拆分的次數。假設指定要拆分n次,則split方法會對輸入字符串從頭開始拆分,要麼執行n次後停止拆分(此時生成的列表中包含n+1個子字符串)
如果既要用到第二個參數,又要按照空白符進行拆分,請將第一個參數設為None。
>>> x
[2, 4, 1, 3]
>>>
>>> x = 'a b c d'
>>> x.split(' ',2)
['a', 'b', 'c d']
>>> x.split(None,2)
['a', 'b', 'c d']
>>>6.4.3 去除多余的空白符
>>> x = " Hello, World\t \t "
>>> x
' Hello, World\t \t '
>>> x.strip()
'Hello, World'
>>> x
' Hello, World\t \t '
>>>
>>> x.lstrip()
'Hello, World\t \t '
>>> x.rstrip()
' Hello, World'
>>>strip、rstrip和lstrip方法還可以附帶一個參數,這個參數包含了需要移除的字符。是從外向內匹配刪除,直到首/尾不再包含任意指定的字符。
>>> x = "asdf Hello, World RRR"
>>> x.strip('R')
'asdf Hello, World '
>>> x.lstrip('sdfaR')
' Hello, World RRR'
>>> x.rstrip('sdfaR ')
'asdf Hello, Worl'
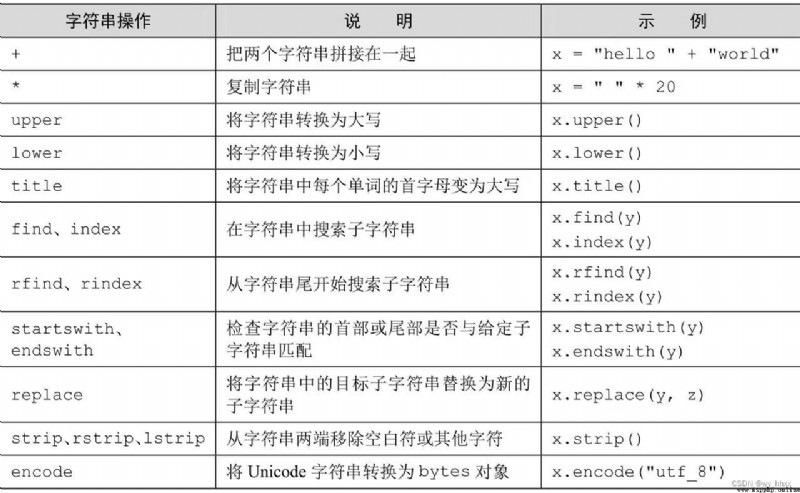
>>>6.4.4 字符串搜索
基礎的字符串搜索方法有4個,即find、rfind、index和rindex,它們比較類似。
find方法將會返回子字符串第一個實例的首字符在調用字符串對象中的位置,如果未找到子串則返回-1
find方法還可以帶一或兩個可選參數。第一個可選參數(如果存在)start是個整數,會讓find在搜索子字符串時忽略字符串中位置start之前的所有字符。第二個可選參數(如果存在)end也是整數,會讓find忽略位置end之後(含)的字符:
rfind方法的功能與find方法幾乎完全相同,但是從字符串的末尾開始搜索,返回的是子字符串在字符串中最後一次出現時的首字符位置
當index或rindex方法(功能分別與find和rfind相同)在字符串中找不到子字符串時,不會返回-1,而是會引發ValueError。
startswith和endswith方法可以一次搜索多個子字符串。如果參數是個字符串元組,那麼這兩個方法就會對元組中的所有字符串進行檢測,只要有一個字符串匹配就會返回True
>>> x = "Mississippi"
>>> x.startswith('Miss')
True
>>> x.startswith('miss')
False
>>> x.startswith(('miss','Miss'))
True
>>>
6.4.5 字符串修改
用replace方法可以將字符串中的子字符串(第一個參數)全部替換為另一個字符串(第二個參數)。
>>> x.replace('ss','++')
'Mi++i++ippi'
>>>
函數string.maketrans和string.translate可以配合起來使用,將字符串中的多個字符轉換為其他字符。
>>> x = "~x ^ (y % z)"
>>> table = x.maketrans("~^()", "!&[]")
>>> x.translate(table)
'!x & [y % z]'
>>>
第二行代碼用maketrans構建了翻譯對照表,數據來自其兩個字符串參數。這兩個參數的字符數必須相同。然後maketrans生成的對照表傳給了translate方法。
判斷字符串是否為數字、字母等
>>> x = "123"
>>> x.isalpha()
False
>>> x.isdigit()
True
>>>
>>> y = "ZH"
>>> y.islower()
False
>>> y.isupper()
True
>>>
動手題:字符串操作假設有一個字符串列表x,其中有一些字符串(不一定是全部)是以雙引號開頭和結尾的:x = ['"abc"', 'def', '"ghi"', '"klm"', 'nop'] ,該用什麼代碼遍歷所有元素並只把雙引號去除呢?
>>> x
['"abc"', 'def', '"ghi"', '"klm"', 'nop']
>>>
>>>
>>> y = []
>>> for i in x:
... i = i.strip('"')
... y.append(i)
...
>>> y
['abc', 'def', 'ghi', 'klm', 'nop']
>>>如何查找"Mississippi"中最後一個字母p的位置?找到後又該如何只去除該字母呢?
方法一:
>>> if x.rfind('p') != -1:
... y = list(x)
... y.pop(x.rfind('p'))
... x = "".join(y)
...
'p'
>>> x
'Mississipi'
>>>方法二:
>>> x = 'Mississippi'
>>> loc = x.rfind('p')
>>> if loc != -1:
... x = x[:loc] + x[loc+1:]
...
>>> x
'Mississipi'
>>>
方法三(只回答了第二問):
>>> x
'Mississippi'
>>>
>>> x_reverse = x[::-1]
>>> x_reverse
'ippississiM'
>>>
>>> x_reverse_list = x_reverse.split('p',1)
>>> x_reverse_list
['i', 'pississiM']
>>>
>>> x = (''.join(x_reverse_list))[::-1]
>>> x
'Mississipi'
>>>
6.5 將對象轉換為字符串
用到Python面向對象的特性之前,repr和str沒有區別。為了維持良好的編程風格,請漸漸習慣用str而不是repr來創建用於顯示的字符串信息。
>>> repr(len)
'<built-in function len>'
>>> repr([1,2,3,4])
'[1, 2, 3, 4]'
>>>
>>> str(len)
'<built-in function len>'
>>> str([1,2,3,4])
'[1, 2, 3, 4]'
>>>
6.6 使用format方法
format方法用了兩個參數,同時給出了包含被替換字段的格式字符串,以及替換後的值。這裡的被替換字段是用{}標識的。如果要在字符串中包含字符“{”或“}”,請用“{ {”或“}}”來表示。
6.6.1 format方法和位置參數
用被替換字段的編號,分別對應傳入的參數
>>> "{0} is {1} of {2}".format("Today","28th","June")
'Today is 28th of June'
>>>6.6.2 format方法和命名參數
>>> "Today is {day} of {month}".format(month="June",day="28th")
'Today is 28th of June'
>>>
同時使用位置參數和命名參數也是允許的,甚至可以訪問參數中的屬性和元素
>>> "{0} is {day} of {month[5]} ({1})".format("Today","Tuesday",day="28th",month=["Jan","Feb","Mar","Apr","May","June","July"])
'Today is 28th of June (Tuesday)'
>>>注意:位置參數要寫在命名參數前面,否則會報錯
>>> "{0} is {day} of {month[5]} ({1})".format("Today",day="28th",month=["Jan","Feb","Mar","Apr","May","June","July"],"Tuesday")
File "<stdin>", line 1
"{0} is {day} of {month[5]} ({1})".format("Today",day="28th",month=["Jan","Feb","Mar","Apr","May","June","July"],"Tuesday")
^
SyntaxError: positional argument follows keyword argument
>>>
6.6.3 格式描述符
>>> "{0:10} is {1} of {2}".format("Today","28th","June")
'Today is 28th of June'
>>>
>>> "{0:{3}} is {1} of {2}".format("Today","28th","June",10)
'Today is 28th of June'
>>>
>>> "{0:{width}} is {1} of {2}".format("Today","28th","June",width=10)
'Today is 28th of June'
>>> "{0:>10} is {1} of {2}".format("Today","28th","June")
' Today is 28th of June'
>>> "{0:#>10} is {1} of {2}".format("Today","28th","June")
'#####Today is 28th of June'
>>> "{0:#<10} is {1} of {2}".format("Today","28th","June")
'Today##### is 28th of June'
>>>
描述符“:10”設置該字段寬度為10個字符,不足部分用空格填充。
描述符“:{1}”表示字段寬度由第二個參數定義。
描述符“:>10”強制字段右對齊,不足部分用空格填充。
描述符“:&>10”強制右對齊,不足部分不用空格而是用“&”字符填充。
6.7 用%格式化字符串
字符串取模操作符%由兩部分組成:左側是字符串,右側是元組。字符串取模操作符將會掃描左側的字符串,查找特定的格式化序列(formatting sequence),並按順序將其替換為右側的值而生成新的字符串。
>>> "%s is %s of %s" % ("Today","28th","June")
'Today is 28th of June'
>>>
6.7.1 使用格式化序列
>>> "Pi is <%-6.2f>" % 3.14159
'Pi is <3.14 >'
>>> "Pi is <%6.2f>" % 3.14159
'Pi is < 3.14>'
>>>
>>> "Pi is <%3.2f>" % 3.14159
'Pi is <3.14>'
>>>
%-6.2f 字符總數6,小數點後2位,左對齊
6.7.2 命名參數和格式化序列
>>> num_dict = {'e': 2.718, 'pi': 3.14159}
>>> print("%(pi).2f - %(pi).4f - %(e).2f" % num_dict)
3.14 - 3.1416 - 2.72
>>>
用print函數控制輸出
控制分隔符和每行的結束符
>>> print("a","b","c",sep=" | ")
a | b | c
>>>
>>> print("a","b","c",end="\n\n")
a b c
>>>
print函數還可以將結果輸出到文件
>>> print("a","b","c",file=open("testfile.txt","w"))
>>>
# cat testfile.txt
a b c
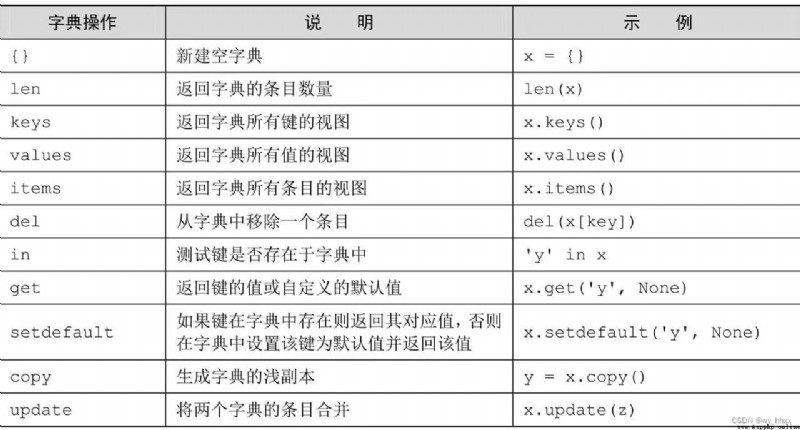
7.2 字典的其他操作
keys方法獲取字典中的所有鍵
values方法獲取到存儲在字典中的所有值
items方法將所有鍵及其關聯值以元組序列的形式返回
>>> english_to_french = {'red': 'rouge', 'blue': 'bleu', 'green': 'vert'}
>>> list(english_to_french.keys())
['red', 'blue', 'green']
>>> list(english_to_french.values())
['rouge', 'bleu', 'vert']
>>> list(english_to_french.items())
[('red', 'rouge'), ('blue', 'bleu'), ('green', 'vert')]
>>>
del語句可用於移除字典中的條目,即鍵值對
>>> del english_to_french['green']
>>> english_to_french
{'red': 'rouge', 'blue': 'bleu'}
>>>
keys、values和items方法的返回結果都不是列表,而是視圖(view)。
>>> english_to_french.items()
dict_items([('red', 'rouge'), ('blue', 'bleu')])
>>>
如果要訪問的鍵在字典中不存在,則會被Python視為出錯。這時可以用in關鍵字先檢測一下字典中是否存在該鍵。
或者還可以用get函數進行檢測。
>>> english_to_french.get('blue', 'No translation')
'bleu'
>>> english_to_french.get('chartreuse', 'No translation')
'No translation'
>>> english_to_french
{'red': 'rouge', 'blue': 'bleu', 'green': 'vert'}
>>>
get和setdefault方法的區別在於,以上setdefault調用完畢後,會在字典中生成鍵'chartreuse'和對應的值'No translation'。
>>> english_to_french.setdefault('chartreuse', 'No translation')
'No translation'
>>> english_to_french
{'red': 'rouge', 'blue': 'bleu', 'green': 'vert', 'chartreuse': 'No translation'}
>>>
copy方法會生成字典的淺副本,大多數情況下應該能滿足需要了。如果字典值中包含了可修改對象,如列表或其他字典,那就可能需要用到copy.deepcopy函數生成深副本。
>>> x = {0: 'zero', 1: 'one'}
>>> y = x.copy()
>>> y
{0: 'zero', 1: 'one'}
>>>
字典的update方法會用第二個字典(即參數)的所有鍵/值對更新第一個字典(即調用者)。
>>> x
{0: 'zero', 1: 'one'}
>>>
>>> z = {1: 'ONE', 2: 'TWO'}
>>> x.update(z)
>>> x
{0: 'zero', 1: 'ONE', 2: 'TWO'}
>>>
7.3 單詞計數
>>> sample_string = "To be or not to be"
>>> occurrences = {}
>>> for word in sample_string.split():
... occurrences[word] = occurrences.get(word,0) + 1
...
>>> occurrences
{'To': 1, 'be': 2, 'or': 1, 'not': 1, 'to': 1}
>>>
以上已被標准化為Counter類,內置於collections模塊中
>>> from collections import Counter
>>> sample_string = "To be or not to be"
>>> count_result = Counter(sample_string.split())
>>> print(count_result)
Counter({'be': 2, 'To': 1, 'or': 1, 'not': 1, 'to': 1})
>>>7.4 可用作字典鍵的對象
上面的例子用了字符串作為字典鍵。但是不僅是字符串,任何不可變(immutable)且可散列(hashable)的Python對象,都可被用作字典的鍵。
對於元組,只有不包含任何可變嵌套對象的元組才是可散列的,可有效地用作字典的鍵。