python解析器
IDE:集成工具的縮寫
作用:運行文件
- ipython:是一種交互式的解析器,可以實現變量自動保存、自動縮進
- cpython:c語言開發的官方解析器,應用廣泛
- 其他解析器
兩種方式
# 單行注釋
"""多行注釋(三個雙引號) """
'''多行注釋(三個單引號)'''
# 快捷鍵:ctrl+/
在程序中,數據都是臨時存儲在內存中,而變量就是一個存儲數據的時候當前數據的內存地址的名字而已。
變量名=值 #這裡沒有說一定要指明變量的類型
變量名要符合標識符命名規則:
- 由數字、字母、下劃線組成
- 不能是數字開頭
- 不能使用內置關鍵字
- 嚴格區分大小寫
命名習慣:
- 見名知意
- 大駝峰
- 小駝峰
- 下劃線
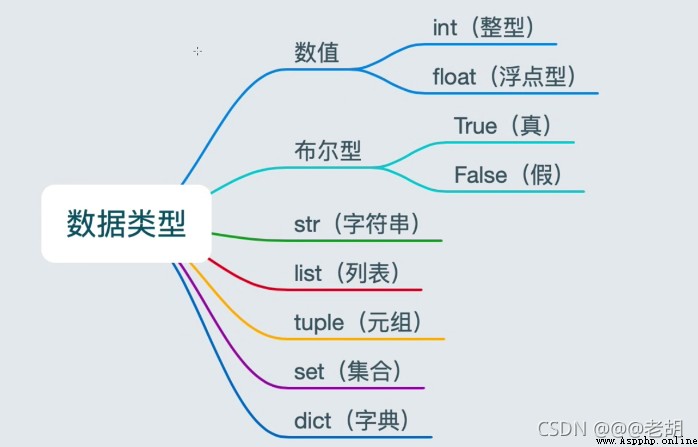
字符串:String
元組型:數組
列表型:list類
字典型:map類
集合:set
布爾型:
代表False,數字代表0的,各種括號都是空的,這裡的只有兩個值,一個是True,一個是False檢測數據類型:type(數據)
a=3+2j
print(a)
b=complex(3,4)
print(b)
(3+2j)
(3+4j)
a=3+2j
print(a)
print(a.real)
print(a.imag)
(3+2j)
3.0
2.0
這裡普通的輸出,輸出有三種方式
x =input('請輸入一個整數')
print(x)
name='aabbcc'
age=20
str='我叫{},我今年{}歲'
print(str.format(name,age))
name='aabbcc'
age=20
print(f'我叫{
name},今年{
age}歲')
這裡使用一個format函數,很靈活
s="今天在{}上課,上的是{}課"
print(s.format("6棟","python"))
今天在6棟上課,上的是python課
比較運算符
==表示字符相同而且對應的地址也要相同,equal表示字符相同就可以了。
from string import Template
string =Template("祝你${x}快樂")
string.substitute(x='生日')
# 這個的好處就是可以隨時改變x的數據類型以及數據
import datetime
name = str(input("請輸入您的姓名:"))
birthday =int(input("請輸入您的出生年份:"))
age = datetime.date.today().year -birthday
print("%s您好! 您今年%d歲。"%(name,age))
這裡是格式化輸出
%s:字符串
%d:十進制整數
%f:浮點數
%c:字符
\n:換行
\t:制表符
輸入
x =input('請輸入一個整數')
print(x)
轉換數據類型常見的函數
int()
float()
str()
list()
tuple() # 元組
eval() # 轉換成原本的類型
/表示帶小數除法//:表示整除in、not in表示在這個序列內就返回true,如果不是就返回falsefor i in (1,23)
#for(int i=1;i<23;i++)
# 講一個運算邏輯
d=10
d*=1+2
print(d)
# 結果是30,首先算賦值運算右邊的,再算左邊的
if……elif ……else
執行流程:當某一個代碼符合條件就可以開始執行,而其他後面的代碼都不會執行
age=50
if age < 18:
print(f'你的年齡是{
age},你是童工')
elif (age>=18)and (age<=60):
print(f'你的年齡是{
age},你是合法勞動人民')
else:
print(f'你的年齡是{
age},你是退休工')
化簡寫法
elif 18<=age<=60
age=50
if age < 18:
print(f'你的年齡是{
age},你是童工')
elif 18<=age<=60:
print(f'你的年齡是{
age},你是合法勞動人民')
else:
print(f'你的年齡是{
age},你是退休工')
隨機數
random類
import random
x=random.randint(1,20)
print(x)
三目運算符
c=a if a>b else b
a=1
b=2
c=a if a>b else b
print(c)
while語法
i=0;
while True:
if i==9:
break;
print(i)
i+=1 # 這裡值得注意的是,i++是不存在的
break:終止循環
continu:終止當前的執行,循環的其他執行不受影響
for循環
for a in [1,10]:
print(a)
1
10
for i in range(1,10):# 這裡值得注意的是,要使用range()函數
print(i)
while…else
循環正常結束之後才執行代碼,不正常執行完不能執行代碼
這是因為循環和else後面的內容有一定的依賴關系
# 正常結束的案例
i=0
while i<=5:
print(i)
i+=1
else:
print('end')
1
2
3
4
5
end
# break提前結束的案例
i=1
while i<=5:
if i==3:
print('發生錯誤')
break
print(i)
i+=1
else:
print('end')
1
2
發生錯誤
# continue提前結束的案例
i=0
while i<=5:
i+=1
if i==5:
print('發生錯誤')
break
print(i)
else:
print('end')
1
2
3
4
發生錯誤
for…else
和while一樣,也是需要在程序正常結束的時候才會執行,如果程序不是正常結束的,else之後的東西是不會執行的.
for a in (1,10):
print(a)
else:
print('循環結束,打印響應')
name1='cch1'
name2="cch2"
name3='''cch3'''
name=input('輸入你的名字:')
print('我的名字是'+name)
print('我的名字是%s'%name)
print(f'我的名字是{name}')
[下標]
name[0]
序列[開始位置的下表:結束位置的下表:步長]
注意的是:
str1='0123456'
print(str1[2:5:2])
# 結果是24
# 如果不寫開始,默認從0開始
str1='0123456'
print(str1[:5:1])
# 結果是01234
# 如果不寫結尾,默認選取到最後一個,而且包含最後一個
str1='0123456'
print(str1[3:])
# 結果是3456
# 如果步長為負數,表示倒序數數
str1='0123456'
print(str1[::-1])
# 結果是6543210
# 前面兩個為負數
str1='0123456'
print(str1[-4:-1])
# 結果是345,因為不包含-1位置上的數,也就是不包含最後一個數字
# 三個數都是負數
str1='0123456'
print(str1[-4:-1:-1])
# 不能選取數據,因為兩個方向互斥,從-4到-1是從左到右選取,但是-1步長表示從右向左選取
# 三個數都是負數
str1='0123456'
print(str1[-1:-4:-1])
# 543,因為選取的方向是一致的
查找子串在字符串的位置或者出現的次數
find():檢查某一個字串是否包含在字符串中,如果存在就返回到這個字串開始位置的下表,否則返回-1
注意:開始位置和結束位置可以省略,表示在整個字符串序列中查找
下面的是語法:
字符串序列.find(字串,開始位置下標,結束位置的下標)
# 這裡可以省略開始和結束的位置的下標,
string='asdffgghfj'
print(string.find('sdf',2))
# 返回-1,因為從2位置開始的字串中沒有包含我們要求的字串‘sdf’
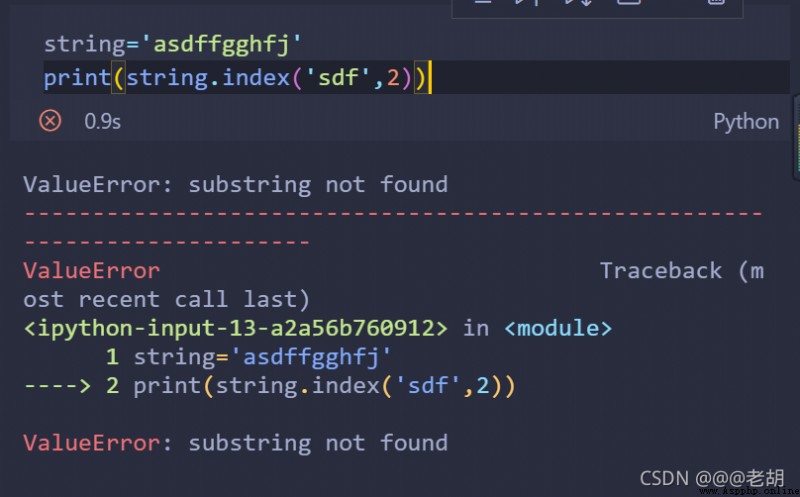
字符串序列.index(字串,開始位置下標,結束位置的下標)
# 這裡可以省略開始和結束的位置的下標,
string='asdffgghfj'
print(string.index('sdf',2))
字符串序列.count(字串,開始位置下標,結束位置的下標)
# 這裡可以省略開始和結束的位置的下標,
string='asdffgghfj'
print(string.count('sdf',2))
# 這裡的結果是0
下面的功能和上面的對應功能是類似的,但是查找的方向是從右側開始查找的,下表還是從左往右開始的
字符串序列.replace(舊字符,新字符,替換次數)
# 替換次數可以不寫,不寫表示全部替換;如果替換次數>字串出現次數,表示全部替換,但是不會報錯
string='asdffgghfj'
print(string.replace('f',' False '))
# 結果:asd False False ggh False j
string.split(分割的字符,num)
# num表示分割字符出現的次數,也就是返回的數據個數為num+1個
string='asd False False ggh False j'
print(string.split('False'))
# 輸出結果:['asd ', ' ', ' ggh ', ' j'],這裡可以看到,全部都分割了,而且False本身就已經去掉了
string='asd False False ggh False j'
print(string.split('False',2))
# 這裡的結果是:['asd ', ' ', ' ggh False j'],這裡可以看到,這裡會返回2+1 個數據,也就是只分割前面的2個數據
字符或者子串.join(多字串組成的序列)
# 字符或者子串 表示你想要用什麼方法來連接這個序列裡面的內容
list=['aa','bb','cc']
string='...'.join(list)
print(string)
# 結果是:aa...bb...cc
字符串.capitalize()
string='asd False False ggh False j'
print(string.capitalize())
# Asd false false ggh false j
字符串.title()
string='asd False False ggh False j'
print(string.title())
# Asd False False Ggh False J
這裡還要說一次:字符串的函數不會對字符串本身進行修改,而是會有一個返回值,修改後的結果就在返回值中。
刪除字符串的空白字符
lstrip():刪除左邊的空白字符
rstrip():刪除右邊的空白字符
strip():刪除左邊和右邊的空白字符
string=' asd False False ggh False j '
print(string.rstrip())
# asd False False ggh False j
string.ljust(長度,填充字符)
string="aabbcc"
print(string.ljust(10,'*'))
# aabbcc****
string="aabbcc"
print(string.rjust(10,'*'))
# ****aabbcc
string="aabbcc"
print(string.center(10,'*'))
# **aabbcc**
string="aabbcc"
print(string.center(9,'*'))
# **aabbcc*
如果中間對齊,出現到填充字符字符為奇數的時候,是做不到絕對對齊的
判斷函數返回的結果為False或者是True
判斷開頭結尾
startswith():檢查字串是否在指定的范圍內以指定字串開頭,是就返回True,否則返回False
語法:
string.startswith(子串,開始位置下標,結束位置下標)
# 後面兩個參數可省略
string.endswith(子串,開始位置下標,結束位置下標)
# 後面兩個參數可省略
string='asd False False ggh False'
print(string.endswith('false'))
# False
這裡值得注意的是,這裡是嚴格區分大小寫的
string1='hello'
string2='hello123'
string3='Hello'
string4='123'
print(string1.isalpha())
print(string2.isalpha())
print(string3.isalpha())
print(string4.isdigit())
# True
# False
# True
# True
這個不論大小寫
string1=' '
string2='hello123'
print(string1.isspace())# True
print(string2.isalnum())# True
存儲多個數據,並且數據是可以被修改的就是列表。
[數據1,數據2,數據3……]
列表可以存儲很多的數據,也可以存儲不同數據類型的數據,但是在實際業務中,我們一般都是同一個列表存儲同一種數據類型
name=['aaa','bbb','ccc']
print(name[0])
# aaa
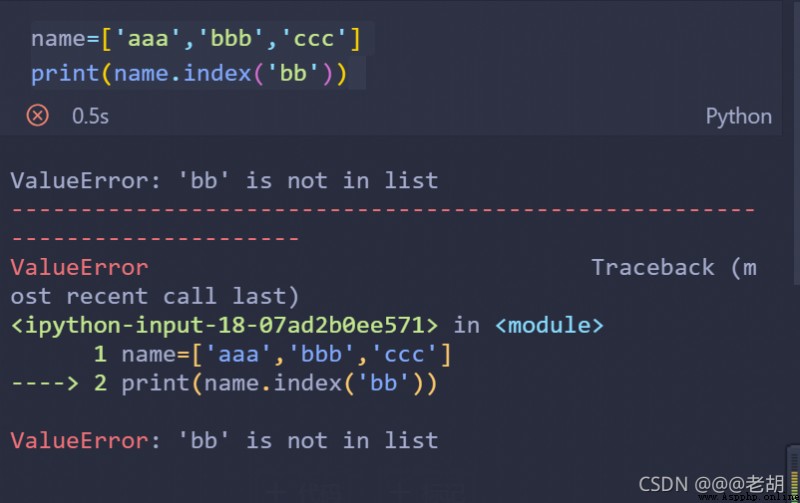
list.index()
name=['aaa','bbb','ccc']
print(name.index('bb'))
list.count()
len(list_name)
# 返回一個數字
name=['aaa','bbb','ccc']
print(len(name))
print(type(len(name)))
# 3
# <class 'int'>
返回值位True或者False
數據 in list_name
shuju1 not in list_name
name=['aaa','bbb','ccc']
print('aaa' in name)
print('aa' in name)
print('aa' not in name)
# True
# False
# True
增加指定數據到列表
list.append(數據)
name=['aaa','bbb','ccc']
name.append('ddd')
print(name)
# ['aaa', 'bbb', 'ccc', 'ddd']
可以追加列表序列
name=['aaa','bbb','ccc']
name.append([11,22])
print(name)
# ['aaa', 'bbb', 'ccc', [11, 22]]
注意的是,一次只能追加一個數據,不能同時追加多個數據
list.extend(數據)
這裡和上面不同的是,這裡追加序列的時候,會把序列拆開
name=['aaa','bbb','ccc']
name.extend('ddd')
print(name)
# ['aaa', 'bbb', 'ccc', 'd', 'd', 'd']
# 這裡的‘ddd’也算是一個序列,所以要拆開
name=['aaa','bbb','ccc',12]
name.extend([10,13])
print(name)
# ['aaa', 'bbb', 'ccc', 12, 10, 13]
name=['aaa','bbb','ccc',12]
name.extend(10)
print(name)
# TypeError: 'int' object is not iterable
# int不是可以迭代的類型,不能直接extend
name=['aaa','bbb','ccc',12]
name.extend(range(1,2))
print(name)
# ['aaa', 'bbb', 'ccc', 12, 1]
list.insert(下標,數據)
name=['aaa','bbb','ccc',12]
name.insert(2,'ddd')
print(name)
# ['aaa', 'bbb', 'ddd', 'ccc', 12]
我們要注意的是,增加的這一部分其實是在列表本身中增加的,已經是修改了列表本身的數據了,這一點和str類型不一樣
del 目標
del(目標)
# 刪除指定位置的數據
del list[下標]
name=['aaa','bbb','ccc',12]
del name
print(name)
# NameError: name 'name' is not defined
name=['aaa','bbb','ccc',12]del name[0]print(name)# ['bbb', 'ccc', 12]
list.pop(下標)
name=['aaa','bbb','ccc',12]a=name.pop()print(name)print(a)# ['aaa', 'bbb', 'ccc']# 12
這個方法不能刪除多個數據
list.remove(指定的數據)
name=['aaa','bbb','ccc',12]name.remove(12)print(name)# ['aaa', 'bbb', 'ccc']
list.clear()
name=['aaa','bbb','ccc',12]name.clear()print(name)# []
刪除數據也是在列表本身刪除的
name=['aaa','bbb','ccc',12]name[0]='gdhhhr'print(name)# ['gdhhhr', 'bbb', 'ccc', 12]
name=['aaa','bbb','ccc',12]name.reverse()print(name)# [12, 'ccc', 'bbb', 'aaa']
list.sort(key=None,reverse=False)# key是在字典中按照字典某一個值來排序,reverse=False表示升序,reverse=True表示降序
name=[1,2,3,4,6,7,5]name.sort()print(name)# [1, 2, 3, 4, 5, 6, 7]
name=[1,2,3,4,6,7,5]name.sort(reverse=True)print(name)# [7, 6, 5, 4, 3, 2, 1]
copy():復制函數有返回值,是復制之後的數據,一般用來保留源數據
語法:
list.copy()
i=0name=[1,2,3,4,6,7,5]while i<len(name): print(name[i] ,end=' ') i+=1# 1 2 3 4 6 7 5
name=[1,2,3,4,6,7,5]for i in name: print(i,end=' ')# 1 2 3 4 6 7 5
name=[[1,2,3],[23,34,45],[234,456,789]]for i in name: print(i,end=' ')# [1, 2, 3] [23, 34, 45] [234, 456, 789]
name=[[1,2,3],[23,34,45],[234,456,789]]for i in name: for j in i: print(j,end=' ')# 1 2 3 23 34 45 234 456 789
存儲多個數據,數據不能被修改的,用小括號
獲取某一個下標的數據:tuple[i]
使用小括號
name=(10,20)
這裡要注意的是,如果定義的元組只有一個數據,這個數據後面也要添加逗號,不然這個數據的類型會為唯一的數據的數據類型
name=(10)name1=(10,)print(type(name))print(type(name1))# <class 'int'># <class 'tuple'>
因為元組不支持修改操作,只支持查找操作,所以這裡的操作都是查找操作
tuple.index(e,start,end)
a=(11,22,33,44)print(a.index(11))
count()
語法:
tuple.count()
tuple.len()
修改
元組中嵌套列表,這個列表內容是支持修改的
a={
'name':'Tom','age':20,'gender':'男'}a=dict()a={
}
字典是可變類型,也就是對字典的修改是在字典本身的數據上修改的,這一年和list一樣
寫法:dictName[key]=value
如果key存在就修改value,如果不存在就新增這個鍵值對
a={
'name':'ccc','age':20}a['name']='cch'print(a)# {'name': 'cch', 'age': 20}
a={
'name':'ccc','age':20}a['id']=1print(a)# {'name': 'ccc', 'age': 20, 'id': 1}
a={
'name':'ccc','age':20}del(a)print(a)# NameError: name 'a' is not defined
a={
'name':'ccc','age':20}del a['name']print(a)# {'age': 20}# 如果不存在就會報錯
a={
'name':'ccc','age':20}a.clear()print(a)# {}
寫法:字典序列[key]=value,其實和增加麼有區別
a={
'name':'ccc','age':20}a['name']='cch'print(a)# {'name': 'cch', 'age': 20}
a={
'name':'ccc','age':20}print(a['name'])# ccc
字典序列.get(key,默認值)
a={
'name':'ccc','age':20}
print(a.get('id',1))
# 1
a={
'name':'ccc','age':20}
print(a.keys())
# dict_keys(['name', 'age'])
a={
'name':'ccc','age':20}
print(a.values())
# dict_values(['ccc', 20])
a={
'name':'ccc','age':20}
print(a.items())
# dict_items([('name', 'ccc'), ('age', 20)])
這裡我解析的是拆包
a={
'name':'ccc','age':20}
for key,value in a.items():
print(f'{
key}={
value}')
# name=ccc
# age=20
{}或者set(),但是如果要創建一個空的集合只能使用set(),因為{}用來創建一個空的字典set1={
12,10,28,28,28}
print(set1)
# {10, 12, 28}
set2=set()
print(set2)
# set()
set1={
'abcfdhdjfdj'}
print(set1)
# {'abcfdhdjfdj'}
set2=set('qwert')
print(set2)
# {'q', 't', 'w', 'r', 'e'}
# 這裡沒有按照順序來輸出
set1={
12,23,45,2}
set1.add(10)
print(set1)
# {2, 10, 12, 45, 23}
set1={
12,23,45,2}
set1.add(10,11)
print(set1)
# TypeError: add() takes exactly one argument (2 given)
set1={
12,23,45,2}
set1.update([10,11])
print(set1)
# {2, 10, 11, 12, 45, 23}
set1={
12,23,45,2}
set1.remove(12)
print(set1)
# {2, 45, 23}
set1={
12,23,45,2}
set1.discard(10)
print(set1)
# {2, 12, 45, 23}
set1={
12,23,45,2}
num=set1.pop()
print(set1)
print(num)
# {12, 45, 23}
# 2
set1={
12,23,45,2}
print(10 in set1)
print(10 not in set1)
# False
# True

for i in range(10):
print(i)
# 0 1 2 3 4 5 6 7 8 9
enumerate(可遍歷對象,start=0)
# start參數是用來設置數據的下標起始值,默認是0
list1=[1,2,3,4,5,6]
for i in enumerate(list1):
print(i,end=" ")
# (0, 1) (1, 2) (2, 3) (3, 4) (4, 5) (5, 6)
list1=[1,2,3,4,5,6]
for i in enumerate(list1,1):
print(i,end=" ")
# (1, 1) (2, 2) (3, 3) (4, 4) (5, 5) (6, 6)
tuple():將數據轉變成元組
list():將數據轉變成列表
set():將數據轉變成集合,可以去重
在python中,只有列表、字典、集合才有推導式
推導式又叫生成式
推導式是為了化簡代碼來使用的。
=作用:用一個表達式創建一個有規律的列表或者控制一個有規律的列表。=
這裡特別值得注意的是,這裡的有規律說的是列表的內容是有規律的。
列表推導式又叫列表生成式
需求:生成一個有規律的列表
這裡是常規的寫法
list1=[]
i=0
while i<10:
list1.append(i)
i+=1
print(list1)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
這裡演示一個推導式的實現
list1=[i for i in range(10)]
print(list1)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
需求:創建0-10的偶數列表
list1=[i for i in range(0,10,2)]
print(list1)
# [0, 2, 4, 6, 8]
list1=[i for i in range(0,10) if i%2==0]
print(list1)
# [0, 2, 4, 6, 8]
需求:創建一個如下的列表:
[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
list2=[]
for i in range(1,3):
for j in range(3):
list2.append((i,j))
print(list2)
list1=[(i,j) for i in range(1,3) for j in range(3)]
print(list1)
字典推導式的作用:將兩個列表快速合並成為一個字典
dict1={
i:i**2 for i in range(1,5)}
print(dict1)
# {1: 1, 2: 4, 3: 9, 4: 16}
list1=[1,2,3]
list2=[1,4,9]
dict2={
list1[i]:list2[i] for i in range(len(list1))}
print(dict2)
# {1: 1, 2: 4, 3: 9}
list1=[1,2,3]list2=[1,4]dict2={
list1[i]:list2[i] for i in range(len(list1))}print(dict2)
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-14-96a775aca203> in <module>
1 list1=[1,2,3]
2 list2=[1,4]
----> 3 dict2={list1[i]:list2[i] for i in range(len(list1))}
4 print(dict2)
<ipython-input-14-96a775aca203> in <dictcomp>(.0)
1 list1=[1,2,3]
2 list2=[1,4]
----> 3 dict2={list1[i]:list2[i] for i in range(len(list1))}
4 print(dict2)
IndexError: list index out of range
所以我們在這裡應該要注意到,如果兩個列表的長度是相同的,可以隨意取list1或者list2的長度,結果都是一樣的,但是如果長度不一致,就要取長度比較短的那個列表的數據的長度,否則會出現報錯
正常解題思路:
counts={
'MBP':258,'HP':20,'LENOVO':199}
count1={
}
for key,value in counts.items():
if value>100:
count1[key]=value
print(count1)
推導式:
counts={
'MBP':258,'HP':20,'LENOVO':199}count1={
key:value for key,value in counts.items() if value>100}print(count1)
結果:
{'MBP': 258, 'LENOVO': 199}
需求:創建一個集合,數據位列表數據的2次方,這裡要注意的是,set是有去重效果的
list1=[1,1,2]set1={
i**2 for i in list1}print(set1)# {1,4}
python中,函數必須是先定義再使用
格式
def 函數名(參數):
代碼1
代碼2
...
函數的返回值在python中是不用在函數名字前面寫返回值的,直接return就可以了
查看函數說明文檔
help(函數名字)
定義說明文檔:當且僅當只能在函數的第一行縮進用多行注釋的方式寫才可以被當做說明文檔
def delSameListElement(List1,temp):
""" 定義一個函數,表示刪除一個列表中的重復數據。 它使用了一個temp來把list的的非重復數據挑出來。 """
for i in List1:
if i in temp:
continue
else:
temp.append(i)
return 0;
temp=[]
List1 = [0, 1, 2, 3, 4, 1,1]
delSameListElement(List1,temp)
print(temp)
help(delSameListElement)
[0, 1, 2, 3, 4]Help on function delSameListElement in module __main__:delSameListElement(List1, temp) 定義一個函數,表示刪除一個列表中的重復數據。 它使用了一個temp來把list的的非重復數據挑出來。
這裡講的函數的返回值是針對函數有多個返回值的情況。
如果有多個return的值,返回的是一個元組,return也可以返回列表、元組、字典等
def return_num(): return 1,2num1=return_num()print(num1)# (1, 2)
和我們正常的參數基本沒有區別,也就是函數的調用的時候,參數的順序要和函數本身的順序是一致的,不然就會報錯
函數的調用,通過”鍵=值“的形式加以指定,可以使得函數更加清晰,而且更加容易使用,也能清除參數的順序的需求
def return_num(name,age,gender): print(f'名字:{
name},年齡:{
age},性別:{
gender}')return_num('Rose',gender='女',age=20)#名字:Rose,年齡:20,性別:女
函數調用的時候,如果有位置參數,位置參數必須在關鍵字參數的見面,但是關鍵字參數之間不存在先後順序
缺省參數也叫默認參數,用來定義函數,為函數提供默認值,函數調用的時候可以不傳默認參數的值(注意:所有位置參數也必須要出現在默認參數值的前面,包括函數的定義和調用)
def return_num(name,age,gender='男'): print(f'名字:{
name},年齡:{
age},性別:{
gender}')return_num('Tom',age=20)return_num('Rose',age=20,gender='女')
名字:Tom,年齡:20,性別:男名字:Rose,年齡:20,性別:女
函數調用的時候,如果缺省就會直接調用默認值
也叫可變參數,用於不確定調用的時候需要傳遞多少個參數,這個時候可以用包裹(packing)位置參數,或者包裹關鍵字參數,來進行參數傳遞,會顯得非常方便。
*argsdef return_num(*args): print(args)return_num('Tom',10)return_num('Rose',20,'女')
('Tom', 10)('Rose', 20, '女')
傳入的參數都會被args變量收集,它會根據傳進的參數的位置合並為一個元組,這就是包裹位置傳遞
def return_num(**kwargs):
print(kwargs)
return_num(name='Tom',age=10)
{'name': 'Tom', 'age': 10}
最後返回的是一個字典類型
無論是包裹位子傳遞還是包裹關鍵字傳遞,都是一個組包的過程
def return_num():
return 100,200 #這裡返回的是一個元組
num1,num2=return_num()
print(num1)
print(num2)
100
200
dict1={
'name':'Tom','age':10}
a,b=dict1 #取出來的是keys
print(a)
print(b)
print(dict1[a])
print(dict1[b])
nameageTom10
a,b=1,20
a,b=b,a
print(a,b)
# 20 1
在python中,值都是靠引用來傳遞的
我們可以用id()來判斷兩個變量是否是同一個值的引用,我們可以講id理解為那塊內存的地址的標識
a=1
b=a
print(id(a))
print(id(b))
a=2
print(b)#說明int類型是不可變的數據
print(id(a))
print(id(b))
140712497063728
140712497063728
1
140712497063760
140712497063728
我們可這樣理解,我們每定義一個數據,就會開辟一個內存,變量是對這個數據的地址的引用。
int類型的數據是不可變數據
aa=[11,22]bb=aaprint(id(aa))print(id(bb))aa.append(33)print(id(aa))print(id(bb))
2325297783432
2325297783432
2325297783432
2325297783432
就是正常把變量傳入到函數調用這邊
學過省略
和java的一樣,當一個函數有一個返回值,並且只有一句代碼,可以使用lambda
表達式
這裡值得注意的是:
lambda 參數列表:表達式
def fn1():
return 200
print(fn1)
print(fn1())
fn2=lambda:100
print(fn2)
print(fn2())
<function fn1 at 0x00000229F25F4280>
200
<function <lambda> at 0x00000229F1A14F70>
100
def fn1(a,b): return a+bprint(fn1(1,2))fn2=lambda a,b:a+bprint(fn2(1,2))
33
def fn1(a,b,c=100): return a+b+cprint(fn1(1,2))fn2=lambda a,b,c=100:a+b+cprint(fn2(1,2))
103103
def fn1(*args):
return args
print(fn1(1,2))
fn2=lambda *args:args
print(fn2(1,2))
(1, 2)
(1, 2)
def func(a,*b):
for item in b:
a += item# 拆包
return a
m = 0
print(func(m,1,1,2,3,5,7,12,21,33))
# 85
def fn1(**kwargs):
return kwargs
dict1=fn1(name='Tom',age=20)
print(dict1)
fn2=lambda **kwargs:kwargs
print(fn2(name='Rose',age=10))
{'name': 'Tom', 'age': 20}{'name': 'Rose', 'age': 10}
fn1=lambda a,b:a if a>b else bprint(fn1(1,290))# 290
students=[{
'name':'Tom','age':10},{
'name':'Rose','age':20},{
'name':'Jack','age':30}]#按照name值升序排序students.sort(key=lambda x:x['name'])print(students)#按照name降序排序students.sort(key=lambda x:x['name'],reverse=True)print(students)
[{'name': 'Jack', 'age': 30}, {'name': 'Rose', 'age': 20}, {'name': 'Tom', 'age': 10}][{'name': 'Tom', 'age': 10}, {'name': 'Rose', 'age': 20}, {'name': 'Jack', 'age': 30}]
把函數作為參數傳入,這樣的函數叫做高階函數,高階函數是函數式編程的體現。
對數字求絕對值
對函數進行四捨五入
print(round(1.5))# 2
# 這個的功能是把列表中的數據都變成它的平方值def f(x): return x*xprint(list(map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])))# [1, 4, 9, 10, 25, 36, 49, 64, 81]
注意:
- 由於list包含的元素可以是任何類型,因此,map() 不僅僅可以處理只包含數值的 list,事實上它可以處理包含任意類型的 list,只要傳入的函數f可以處理這種數據類型。
reduce(func,list)其中func必須要有兩個參數,每一次func的計算結果繼續和序列的下一個元素做累計運算import functools
list1=[1,2,3,4]
def fun(a,b):
return a+b
result=functools.reduce(fun,list1)
print(result)
# 10
import functools
list1=[1,2,3,4]
def fun(a,b):
return a-b
result=functools.reduce(fun,list1)
print(result)
# -8
filter(func,list)函數用來過濾掉不符合條件的元素,返回一個filter對象,這裡對象可以轉換成其他的數據類型比如listlist1=[1,2,3,4,5,6,79.7]
def fun(x):
return x%2==0
result=filter(fun,list1)
print(result)
print(list(result))
<filter object at 0x000002011BE270A0>[2, 4, 6]
函數原型:zip(*iterables),可以傳入不定長的參數
該函數以一系列列表作為參數,將列表中對應的元素打包成一個個元組,然後返回由這些元組組成的列表。
eval(<字符串>) 能夠以Python表達式的方式解析並執行字符串,並將返回結果輸出。
eval函數的作用是將輸入的字符串轉為Python語句,並執行該語句
使用open函數,可以打開一個已經存在的文件,或者如果這個文件不存在可以創建一個新的文件
對象=open(name,mode)
name:是要打開的目標文件名的字符串(可以包含文件所在的具體路徑)
mode:設置打開文件的模式(訪問模式):只讀、寫入、追加等
f=open('test.txt','w')f.write('cch')f.close()
r:只讀,如果文件不存在就會報錯,r也不支持寫,因為r代表只讀
w:寫,如果文件不存在,就會新建一個文件;如果文件存在,就會從頭開始編輯,也就是原來的內容會被覆蓋
a:追加,如果文件存在就追加,如果文件不存在就會新建並且寫入
如果訪問模式省略,表示文件只讀(r)
帶有b的:表示二進制文件形式
帶有+的:表示可讀可寫模式
前綴的理解:後面的追加都是基於前綴的模式來進行拓展,都要滿足前綴要求的條件
文件指針:r和w都是在文件開頭,a是在文件結尾

f=open('test.txt','r')a=f.read()print(a)f.close()
cch
f=open('test.txt','a')f.write('cch')f.close()# cchcch
文件對象.read(num)# num表示從文件中讀取數據的長度(單位是字節),如果沒有傳入num,表示讀取全部內容
#txt中的內容I can't conceivable that the number of suicies has reached 30-year high in American
f=open('test.txt','r')a=f.read(10)print(a)f.close()#I can't co#這裡值得注意的是,空格也是占用了一個字節的
可以按照行的方式把整一個文件中的內容進行一次性讀取,並且返回的是一個列表,其中每一行的數據為一個元素,並且把換行符號一起返回打印出來
f=open('test.txt','r')a=f.readlines()print(a)f.close()
["I can't conceivable that the number of suicies has reached 30-year high in American\n", 'brilliance\n', 'universal\n', 'ultimate']
默認第一次讀第一行內容,第二次讀第二行內容,以此類推
f=open('test.txt','r')a=f.readline()print(a)a=f.readline()print(a)f.close()
I can't conceivable that the number of suicies has reached 30-year high in Americanbrilliance
作用:用來移動文件指針
文件對象.seek(偏移量,起始位置)
起始位置:
- 0:文件開頭
- 1:當前位置
- 2:文件結尾
f=open('test.txt','r')
f.seek(2,0)
a=f.read()
print(a)
f.close()
這個例子代表的是,從開頭位置開始,偏移2位也就是開頭兩個不能要,其他的都可以讀取
can't conceivable that the number of suicies has reached 30-year high in American
brilliance
universal
ultimate
f=open('test.txt','r')
f.seek(0,2)
a=f.read()
print(a)
f.close()
面向對象就是將編程當做一個事務,對於外界來講,事務是直接使用的,不用去管他內部的情況,編程就是設置事務能做什麼事情
類名遵循大駝峰的命名習慣
class 類名:
...
class 類名(object):
...
對象名=類名()
# 定義一個類
class Wahser():
def wash(self):
print('洗衣服ing...')
# 定義一個對象
haier=Wahser()
haier.wash()
# 洗衣服ing...
self是指調用這個函數的對象
# 定義一個類
class Wahser():
def wash(self):
print('洗衣服ing...')
print(self)
# 定義一個對象
haier=Wahser()
print(haier)
haier.wash()
<__main__.Wahser object at 0x00000204C2298D00>
洗衣服ing...
<__main__.Wahser object at 0x00000204C2298D00>
對象的屬性既可以在類外面添加獲取,也可以在類裡面添加獲取
#添加
對象名.屬性名=值
#獲取
對象名.屬性名
# 定義一個類
class Wahser():
def wash(s):
print('洗衣服ing...')
# 定義一個對象
haier=Wahser()
haier.width=500
haier.higth=600
print(f'寬度{
haier.width},高度{
haier.higth}')
haier.wash()
寬度500,高度600
洗衣服ing...
這裡一定要注意的是,這裡的屬性一定要先定義好再調用
self.屬性名
# 定義一個類
class Wahser():
def wash(self):
print('洗衣服ing...')
print(f'寬度{
self.width},高度{
self.higth}')
# 定義一個對象
haier=Wahser()
haier.width=500
haier.higth=600
haier.wash()
洗衣服ing...
寬度500,高度600
在python中,_xx_()的函數被叫做魔法方法,指的是具有特殊功能的函數
—init—()方法在創建一個對象的時候是默認被調用的,不需要手動調用—init—(self)中的self的參數,不需要開發者傳遞,python解釋器會自動把當前的對象傳遞過去# 定義一個類
class Wahser():
def __init__(self) :
self.width=500
self.height=800
def info(self):
print(f'寬度{
self.width},高度{
self.height}')
def wash(self):
print('洗衣服ing...')
# 定義一個對象
haier=Wahser()
haier.info()
haier.wash()
寬度500,高度800
洗衣服ing...
# 定義一個類
class Wahser():
def __init__(self,width,height) :
self.width=width
self.height=height
def info(self):
print(f'寬度{
self.width},高度{
self.height}')
def wash(self):
print('洗衣服ing...')
# 定義一個對象,因為在創建對象的時候就已經調用了__init__方法
haier=Wahser(100,200)
haier.info()
haier.wash()
寬度100,高度200
洗衣服ing...
當print對選哪個的時候,我們默認會打印出內存地址,但是類定義了這個方法就會打印出這個方法中return的數據
# 定義一個類
class Wahser():
def __init__(self,width,height) :
self.width=width
self.height=height
def __str__(self) -> str:
return '這裡是郵箱的說明書。。。'
def info(self):
print(f'寬度{
self.width},高度{
self.height}')
def wash(self):
print('洗衣服ing...')
# 定義一個對象
haier=Wahser(100,200)
print(haier)
haier.info()
haier.wash()
這裡是郵箱的說明書。。。
寬度100,高度200
洗衣服ing...
當刪除對象的時候,python自動調用這個方法
# 定義一個類
class Wahser():
def __init__(self,width,height) :
self.width=width
self.height=height
def __str__(self) -> str:
return '這裡是郵箱的說明書。。。'
def __del__(self):
print('對象被刪除了')
def info(self):
print(f'寬度{
self.width},高度{
self.height}')
def wash(self):
print('洗衣服ing...')
# 定義一個對象
haier=Wahser(100,200)
print(haier)
haier.info()
haier.wash()
del haier
這裡是郵箱的說明書。。。
寬度100,高度200
洗衣服ing...
對象被刪除了
# 定義一個父類animal
class animal():
def __init__(self,name) :
self.name=name# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
# 定義一個子類
class dogs(animal):
pass
dog=dogs('dog')
dog.info()
#這個是dog

# 定義一個父類animal
class Animals():
def __init__(self) :
self.name='動物'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
# 定義一個子類
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
def make_Dogs(self):
# 如果先調用父類屬性和方法,父類屬性會覆蓋掉子類的屬性,所以在調用屬性之前,要先調用自己的子類進行初始化
self.__init__()
self.info()
def make_Animals(self):
# 調用父類方法,但是為了保證調用到的屬性也是父類的屬性,所以必須在調用的方法之前調用到父類的初始化
Animals.__init__(self)
Animals.info(self)
dog=Dogs()
dog.make_Dogs()
dog.make_Animals()
#這個是狗
#這個是動物
允許多層繼承,只要有繼承關系,子類就可以調用到所有父類的方法和屬性
類名.__mro__
print(dogs.__mro__)
#(<class '__main__.dogs'>, <class '__main__.animal'>, <class 'object'>)
#有參數
super(當前所在類的類名,self).同名方法
#無參數
super().同名方法
這裡演示的是有參數的
# 定義一個父類animal
class Animals():
def __init__(self) :
self.name='動物'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
# 定義一個子類
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
def make_Dogs(self):
super(Dogs,self).__init__()
super(Dogs,self).info()
# def make_Dogs(self):
# # 如果先調用父類屬性和方法,父類屬性會覆蓋掉子類的屬性,所以在調用屬性之前,要先調用自己的子類進行初始化
# self.__init__()
# self.info()
# def make_Animals(self):
# # 調用父類方法,但是為了保證調用到的屬性也是父類的屬性,所以必須在調用的方法之前調用到父類的初始化
# Animals.__init__(self)
# Animals.info(self)
dog=Dogs()
dog.make_Dogs()
# dog.make_Animals()
#這個是動物
這裡演示的是無參數的
# 定義一個父類animal
class Animals():
def __init__(self) :
self.name='動物'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
# 定義一個子類
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
def make_Dogs(self):
super().__init__()
super().info()
# def make_Dogs(self):
# # 如果先調用父類屬性和方法,父類屬性會覆蓋掉子類的屬性,所以在調用屬性之前,要先調用自己的子類進行初始化
# self.__init__()
# self.info()
# def make_Animals(self):
# # 調用父類方法,但是為了保證調用到的屬性也是父類的屬性,所以必須在調用的方法之前調用到父類的初始化
# Animals.__init__(self)
# Animals.info(self)
dog=Dogs()
dog.make_Dogs()
# dog.make_Animals()
設置一些屬性或者方法讓不被子類繼承
設置私有屬性的方法:在屬性名和方法名前面加上兩個下劃線
# 定義一個父類animal
class Animals():
def __init__(self) :
self.__skin='毛發'#這是一個私有屬性
self.name='動物'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
# 定義一個子類
class Dogs(Animals):
def __init__(self) :
self.name='狗'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
def make_Dogs(self):
super().__init__()
super().info()
dog=Dogs()
dog.make_Dogs()
print(dog.__skin)
這個是動物
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-18-ba391c645d4c> in <module>
20 dog=Dogs()
21 dog.make_Dogs()
---> 22 print(dog.__skin)
AttributeError: 'Dogs' object has no attribute '__skin'
私有屬性不可以被繼承,但是可以在類中通過get_xx(獲取私有屬性)和set_xx(修改私有屬性)
# 定義一個父類animal
class Animals():
def __init__(self) :
self.__skin='毛發'#這是一個私有屬性
self.name='動物'# 動物都有名字
def info(self):
print(f'這個是{
self.name}')
def get_skin(self):
return self.__skin
def set_skin(self,skin):
self.__skin=skin
# 定義一個子類
class Dogs(Animals):
pass
dog=Dogs()
dog.set_skin('棕色毛發')
print(dog.get_skin())
# 棕色毛發
在python中,多態不一定來源於繼承,但是最好來源於繼承
class Dog(object):
def work(self):
pass
class DrugDog(Dog):
def work(self):
print('追查毒品')
class ArmyDog(Dog):
def work(self):
print('追查犯人')
class Persion(object):
def work_with_dog(self,dog):
dog.work()
persion =Persion()
dog=ArmyDog()
persion.work_with_dog(dog)
dog=DrugDog()
persion.work_with_dog(dog)
追查犯人
追查毒品
類屬性是類對象所擁有的屬性,它被這個類的所有實例對象所公有
類屬性可以使用類對象或者實例對象訪問
# 定義一個類animal
class Animals():
tooth=10# 類屬性
print(Animal.tooth)#類訪問
cat=Animals()
print(cat.tooth)#實例訪問
dog=Animals()
print(dog.tooth)
#10
#10
#10
類屬性只能通過類來修改,不能通過實例對象修改,如果聽過實例對象修改,意思就是創建了一個實例屬性
# 定義一個類animal
class Animals():
tooth=10# 類屬性
Animals.tooth=14
print(Animals.tooth)
cat=Animals()
print(cat.tooth)
dog=Animals()
dog.tooth=20#創建了一個實例屬性tooth=20
print(cat.tooth)
print(dog.tooth)
14
14
14
20
@classmethod來標識的才是類方法,對於類方法,第一個參數必須是類對象,一般一cls作為第一個參數# 定義一個類animal
class Animals():
__tooth=10# 類屬性
@classmethod
def get_tooth(cls):
return cls.__tooth
cat=Animals()
result=cat.get_tooth()
print(result)
#10
@staticmethod來裝飾,靜態方法不需要傳遞類對象也不需要傳遞1實例對象(形參沒有self、cls)# 定義一個類animal
class Animals():
@staticmethod
def get_static():
print('靜態方法')
cat=Animals()
cat.get_static()
Animals.get_static()
靜態方法
靜態方法
try:
可能發生錯誤的代碼
except:
如果出現異常執行的代碼
try:
f=open('test1.txt','r')
except:
f=open('test1.txt','w')
try:
可能發生錯誤的代碼
except (異常類型1,異常類型2) as result:
print(result)#打印捕獲的異常的信息
注意:
- 如果嘗試執行的代碼異常類型和想要捕獲的類型不一致,就沒有辦法捕獲異常
- 一般來講try下方只放一行代碼
Exception是所有程序異常的父類
try:
可能發生錯誤的代碼
except Exception as result:
print(result)#打印捕獲的異常的信息
else表示如果沒有異常要執行的代碼
try:
可能發生錯誤的代碼
except Exception as result:
print(result)#打印捕獲的異常的信息
else:
沒有異常需要執行的代碼塊
finally表示無論是否異常都要執行的代碼。例如關閉文件
try:
可能發生錯誤的代碼
except Exception as result:
print(result)#打印捕獲的異常的信息
else:
沒有異常需要執行的代碼塊
finally:
無論是否異常都要執行的代碼塊
在python中,拋出自定義異常的語法是raise 異常對象
# 自定義一個異常類,要繼承Exceptipon
class shortInputError(Exception):
def __init__(self,length,min_len ) :
self.length=length
self.min_len=min_len
def __str__(self) :
return f'你輸入的長度是{
self.length},不能少於{
self.min_len}個字符'
def main():
try:
con=input('請輸入密碼:')
if len(con)<8:
raise shortInputError(len(con),8)
except Exception as result:
print(result)
else:
print('密碼輸入正確')
main()
import time
time.功能
import time
print(time.time())
from time import time
直接功能調用
from time import time
print(time())
from time from *
直接功能調用
from time import *
print(time())
from time import time as t
print(t())
當導入一個模塊的時候,python解析器對模塊的搜索順序是:
注意:
- 自己的文件名最好不要和已經有的模塊名重復,否則會導致已有的模塊無法使用(因為搜索路徑由近及遠)
- 如果
from 模塊名 import 功能,如果功能名字重復,調用的是最後定義或者導入的功能- 這裡值得注意的是,就算是同名的變量,也是會對模塊進行覆蓋的,因為我們的內容是通過
引用來定義的,當我們的名字相同的時候,也就是引用相同,就會導致後來的東西覆蓋掉原來的東西,所以我們在定義名字的時候一定要注意最好不要和模塊同名
如果一個模塊文件中有這個變量,當使用from xxx import *導入的時候,只能導入這個列表中的元素,這裡值得注意的是,這個模塊的命名,只能是以.py為後綴來命名,不能以其他任何形式後綴命名
__all__=['testA']
def testA():
print('testA')
def testB():
print('testB')
from module1 import *
testA()
testB()
testA
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-10-5967f3f88564> in <module>
1 from module1 import *
2 testA()
----> 3 testB()
NameError: name 'testB' is not defined
包將有聯系的模塊組織到一起,也就是放在同一個文件夾中,並且這個文件夾創建一個名字為__init__.py文件,那麼這個文件夾就稱作包
mypackage包__init__.py、module1.py、module2.py文件def module1_test():
print('這個是module1方法')
def module2_test():
print('這個是module2方法')
import 包名.模塊名
包名.模塊名.目標
import mypackage.module1
mypackage.module1.module1_test()
__init__.py文件中添加__all__=[],控制允許導入的模塊列表,如果不設置,代表所有模塊都不能通過from 包名 impor*
模塊名.目標
# 控制包的導入行為
__all__=['module1']
from mypackage import*
module1.module1_test()
這個是module1方法
class Dog(object):
a=1
def work(self):
print('正在工作')
dog=Dog()
print(Dog.__dict__)
{
'__module__': '__main__', 'a': 1, 'work': <function Dog.work at 0x00000270150CA790>, '__dict__': <attribute '__dict__' of 'Dog' objects>, '__weakref__': <attribute '__weakref__' of 'Dog' objects>, '__doc__': None}
time 和 calendar 模塊可以用於格式化日期和時間。time.time()用於獲取當前時間戳,import time
ticks=time.time()
print ("當前時間為:",ticks)
# 當前時間為: 1634655386.6290803
很多Python函數用一個元組裝起來的9組數字處理