在《喜羊羊與灰太狼》2021年1月出的一部《運動英雄傳之筐出勝利》中,在最後一集的結尾,有一部分對著一個大背景的平移鏡頭,使用Python可以根據此部分鏡頭還原出大背景。
喜羊羊與灰太狼之筐出勝利 第60集 冠軍
導入相關庫
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pyod.models.knn import KNN
讀取視頻中的第一幀
video = cv2.VideoCapture(r'60.mp4') # 讀取視頻
ret, leftframe = video.read() # 讀取幀
由於後期拼接圖片需要使用透明度,所以這裡將圖片轉為4通道
b_channel, g_channel, r_channel = cv2.split(leftframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值為0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
leftframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('leftframe',leftframe)
參考https://blog.csdn.net/qq878594585/article/details/81901703,首先要檢測圖片的關鍵特征點。現在SIFT可在cv2中直接使用,參考https://www.dtmao.cc/news_show_359297.shtml
hessian=400
surf=cv2.SIFT_create(hessian) #將Hessian Threshold設置為400,阈值越大能檢測的特征就越少
# 更新openCV版本即可使用SIFT,參考https://www.dtmao.cc/news_show_359297.shtml
kp1,des1=surf.detectAndCompute(leftframe,None) #查找關鍵點和描述符
讀取下一幀後同樣的操作
ret, rightframe = video.read() # 讀取下一幀
b_channel, g_channel, r_channel = cv2.split(rightframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值為0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
rightframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
print("frameshape:",leftframe.shape,rightframe.shape)
kp2,des2=surf.detectAndCompute(rightframe,None) #查找關鍵點和描述符
# frameshape: (1080, 1920, 4) (1080, 1920, 4)
這裡繼續參考https://blog.csdn.net/qq878594585/article/details/81901703
FLANN_INDEX_KDTREE=0 #建立FLANN匹配器的參數
indexParams=dict(algorithm=FLANN_INDEX_KDTREE,trees=5) #配置索引,密度樹的數量為5
searchParams=dict(checks=50) #指定遞歸次數
#FlannBasedMatcher:是目前最快的特征匹配算法(最近鄰搜索)
flann=cv2.FlannBasedMatcher(indexParams,searchParams) #建立匹配器
matches=flann.knnMatch(des1,des2,k=2) #得出匹配的關鍵點
good=[]
#提取優秀的特征點
for m,n in matches:
if m.distance < 0.7*n.distance: #如果第一個鄰近距離比第二個鄰近距離的0.7倍小,則保留
good.append(m)
src_pts = np.array([ kp1[m.queryIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #查詢圖像的特征描述子索引
dst_pts = np.array([ kp2[m.trainIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #訓練(模板)圖像的特征描述子索引
#H=cv2.findHomography(src_pts,dst_pts) #生成變換矩陣
h,w=leftframe.shape[:2]
h1,w1=rightframe.shape[:2]
獲取所有檢測到的關鍵點偏移向量
sandian=dst_pts-src_pts
print("sandian:",sandian.shape)
# sandian: (298, 2)
如果把這些散點在圖上表示出來是這樣的
import mpl_toolkits.axisartist as axisartist
from matplotlib.patches import ConnectionPatch
# https://zhuanlan.zhihu.com/p/40399870
fig=plt.figure()
#使用axisartist.Subplot方法創建一個繪圖區對象ax
ax1=axisartist.Subplot(fig,121)
ax2=axisartist.Subplot(fig,122)
#fig,(ax1,ax2)=plt.subplots(1,2)
for ax in (ax1,ax2):
#通過set_visible方法設置繪圖區所有坐標軸隱藏
#ax.axis[:].set_visible(False)
#ax.new_floating_axis代表添加新的坐標軸
ax.axis["x"] = ax.new_floating_axis(0,0)
ax.axis["x"].toggle(all=False)
#給x坐標軸加上箭頭
ax.axis["x"].set_axisline_style("-|>", size = 1.0)
#添加y坐標軸,且加上箭頭
ax.axis["y"] = ax.new_floating_axis(1,0)
ax.axis["y"].toggle(all=False)
ax.axis["y"].set_axisline_style("-|>", size = 1.0)
#設置x、y軸上刻度顯示方向
#ax1.axis["x"].set_axis_direction("top")
ax.axis["y"].set_axis_direction("right")
#plt.subplot(1,2,1)
ax1.scatter(*sandian.T)
#plt.subplot(1,2,2)
ax2.scatter(*sandian.T)
ax2.set_xlim(-1,1)
ax2.set_ylim(-1,1)
#將繪圖區對象添加到畫布中
fig.add_axes(ax1)
fig.add_axes(ax2)
fig.tight_layout(pad=2)
# https://matplotlib.org/stable/gallery/userdemo/connect_simple01.html#sphx-glr-gallery-userdemo-connect-simple01-py
for i in [(-1,-1),(-1,1)]:
con=ConnectionPatch(i,i,ax1.transData,ax2.transData)
fig.add_artist(con)
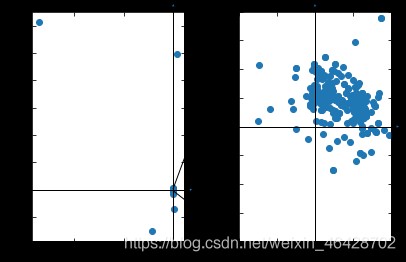
可以看到大部分的散點都集中在一小部分區域,只有幾個異常點,需要將異常點排除,然後取平均值得到最終的平移向量,這裡參考https://blog.csdn.net/weixin_42199542/article/details/106885459的方法。
# 參考:https://blog.csdn.net/weixin_42199542/article/details/106885459
clf = KNN(0.5)
clf.fit(sandian)
y_test_pred = clf.predict(sandian)
sandian=sandian[y_test_pred==0]
# 取平均值得到平移向量
pingyi=np.mean(sandian,0)
print("pingyi:",pingyi)
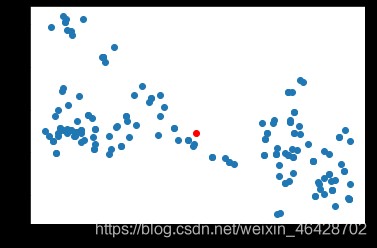
plt.scatter(*sandian.T)
plt.scatter(*pingyi,c='red')
# pingyi: [0.30781024 0.24436529]
後續要用到的變量:
h,w是原有圖片的高和寬
h1,w1是新圖片的高和寬
zuo為原有圖片需要平移的向量
you為新圖片需要平移的向量
rows和cols是合成大圖的高和寬
pingyi是由新圖片的左上角指向原有圖片左上角的向量(np.array的坐標系以左上角作為原點)
隨著圖像的平移,坐標系可能會發生變化,這裡用一張圖來說明一下。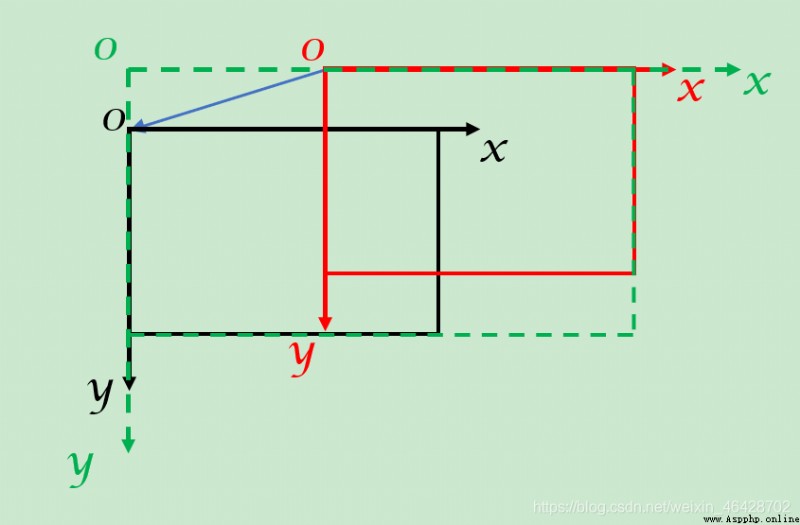
(黑色是原有圖片,紅色是新圖片,綠色是合成的大圖,藍色是pingyi)
此圖中,pingyi在x軸方向上的數值(即pingyi[0])是小於0的,此時新圖片應向右側平移,即向x軸正方向平移,同時大圖的寬度(cols)為pingyi在x軸方向上的數值的絕對值+新圖片的寬度(w1);
而pingyi在y軸方向上的數值(即pingyi[1])是大於0的,此時原有圖片向下平移,即向y軸正方向平移,同時大圖的高度(rows)為pingyi
在y軸方向上的數值的絕對值+原有圖片的高度(h)。
rows,cols=0,0
zuo,you=[0,0],[0,0]
for i in [0,1]:
if pingyi[i]>0:
zuo[i]=pingyi[i]
else:
you[i]=-pingyi[i]
if pingyi[1]<0:
if h1 + abs(int(round(pingyi[1]))) > rows:
rows = h1 + abs(int(round(pingyi[1]))) # 擴展底圖
else:
if h + abs(int(round(pingyi[1]))) > rows:
rows = h + abs(int(round(pingyi[1])))
if pingyi[0]<0:
if w1 + abs(int(round(pingyi[0]))) > cols:
cols = w1 + abs(int(round(pingyi[0])))
else:
if w + abs(int(round(pingyi[0]))) > cols:
cols = w + abs(int(round(pingyi[0])))
print("rows:",rows,"cols:",cols)
# rows: 1080 cols: 1920

在鏡頭移動的過程中不斷有字幕產生遮擋畫面,因此合成時若鏡頭向下移動,則應用新圖片覆蓋原有圖片,從而遮擋字幕;若鏡頭向上移動,則應用原有圖片覆蓋新圖片,防止字幕露出。
具體代碼如下:
(由於最終此部分放到函數中執行,所以若單獨執行,則應先執行leftgray,rightgray=leftframe,rightframe)
鏡頭向下移動時,先將原有圖片平移並擴大,之後將新圖片覆蓋上去。
if pingyi[1]<0:
M = np.float32([[1,0,zuo[0]],[0,1,zuo[1]]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
#cv2.namedWindow('leftdst', 0)
#cv2.imshow('leftdst',leftdst)
#cv2.namedWindow('rightdst', 0)
#cv2.imshow('rightdst',rightdst)
print("dstshape:",leftdst.shape)
weizhix=abs(int(round(you[0])))
weizhiy=abs(int(round(you[1])))
print("weizhi:",weizhix,weizhiy)
#cv2.imwrite(r'leftdst.png',leftdst)
#cv2.imwrite(r'rightgray.png',rightgray)
leftdst[weizhiy:weizhiy+h1,weizhix:weizhix+w1]=rightgray[:,:]
鏡頭向上移動時,先將新圖片平移並擴大,再根據原有圖片的透明度將原有圖片覆蓋上去,最終顯示的圖像為原有圖片*原有圖片的透明度+新圖片*(1-原有圖片的透明度),由於此場景下透明度只有不透明和透明,所以最終顯示圖像的透明度為原有圖片和新圖片透明度的並集。這裡透明度圖層的數值為最大255的整數,通過運算後達到並集的效果。
else:
M = np.float32([[1,0,you[0]],[0,1,you[1]]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
print("dstshape:",rightdst.shape)
weizhix=abs(int(round(zuo[0])))
weizhiy=abs(int(round(zuo[1])))
print("weizhi:",weizhix,weizhiy)
#rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,:3]=leftgray[:,:,:3]
#rightdst=cv2.addWeighted(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w],leftgray[:,:,2],leftgray[:,:,:3],1-leftgray[:,:,2],0)
alpha = leftgray[:,:,3] / 255.0
#print(alpha[:10,:10])
#result = np.zeros(rightdst.shape[:2]+(4,))
#cv2.imshow('result',result)
#cv2.imwrite(r'rightdst.png',rightdst)
#cv2.imwrite(r'leftgray.png',leftgray)
#cv2.waitKey(1000)
print(rightdst.shape[:2]+(4,),leftgray.shape)
print(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0].shape)
print(leftgray[weizhiy:weizhiy+h,weizhix:weizhix+w,1].shape)
print(weizhiy,weizhiy+h,weizhix,weizhix+w)
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] + alpha * leftgray[:,:,0]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] + alpha * leftgray[:,:,1]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] + alpha * leftgray[:,:,2]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3] = (1 - (1-rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3]/255) * (1-leftgray[:,:,3]/255)) * 255
對於合成後的圖片,需要再將其與第三張圖合成,此時若對原合成圖片再次檢測關鍵點,則會浪費大量內存、延長代碼運行時間,並且由於圖片過大,關鍵點不集中,最終的效果會不理想。基於每相鄰兩幀的畫面都有重疊部分,因此可以不考慮整張大圖的其他部分的關鍵點,可以將上一張新圖片中檢測到的關鍵點位移後作為下一次檢測的原有圖片的關鍵點。
global kp1,des1,rows,cols
kp1,des1=kp2,des2
for j in kp1:
j.pt=(j.pt[0]+you[0],j.pt[1]+you[1])
if pingyi[1]<0:
return leftdst
else:
return result
將上述過程定義為pinjie函數,然後加入循環讀取視頻中的每一幀進行合成。
i=0
while 1: # 逐幀讀取
ret, rightframe = video.read() # 讀取下一幀
if not ret:
break
b_channel, g_channel, r_channel = cv2.split(rightframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值為0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
rightframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('frame',frame)
#if i%5==0:
print(i)
leftframe=pinjie(leftframe,rightframe)
#cv2.namedWindow('dst', 0)
#cv2.imshow('dst',leftframe)
#cv2.waitKey(1000)
print()
cv2.imwrite(r'dst.png',leftframe)
i+=1
首次正式運行,結果是這樣的:(原圖過大無法插入,這裡是縮小後的圖片)
可以看到,在圖像的邊緣出現了黑邊,並且放大後可以看到鏡頭繞一圈後原有的部分變模糊了,越早出現的畫面越模糊,與較晚出現的畫面形成了明顯的對比。
仔細研究後,我找到了原因。
程序中多次使用cv2.warpAffine函數,並且平移的向量基本上均為小數,多次非整數的平移使最終的圖片變模糊,使透明度通道的透明部分和不透明部分的界限不明顯,則會產生黑邊。
M = np.float32([[1,0,zuo[0]],[0,1,zuo[1]]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
M = np.float32([[1,0,you[0]],[0,1,you[1]]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
同時,由於此場景下透明度只能為透明或不透明,所以可以將設置透明度的語句中的除改為整除。
alpha = leftgray[:,:,3] // 255.0
...
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3] = (1 - (1-rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3]//255) * (1-leftgray[:,:,3]//255)) * 255
在尋找問題的時候,看到了這個https://zhuanlan.zhihu.com/p/89684929,於是有了思路,就測試了一下。
當平移整數個像素時:
d = np.array([[255, 200, 0, 50],
[200, 255, 50, 0],
[ 0, 50, 255, 200],
[ 50, 0, 200, 255]], np.uint8)
M = np.float32([[1,0,1],[0,1,1]])
M2 = np.float32([[1,0,-1],[0,1,-1]])
for i in range(100):
d = cv2.warpAffine(d,M,(10,10))
d = cv2.warpAffine(d,M2,(10,10))
print(d)
"""[[255 200 0 50 0 0 0 0 0 0] [200 255 50 0 0 0 0 0 0 0] [ 0 50 255 200 0 0 0 0 0 0] [ 50 0 200 255 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0]] """
當平移小數個像素時:
d = np.array([[255, 200, 0, 50],
[200, 255, 50, 0],
[ 0, 50, 255, 200],
[ 50, 0, 200, 255]], np.uint8)
M = np.float32([[1,0,0.5],[0,1,0.5]])
M2 = np.float32([[1,0,-0.5],[0,1,-0.5]])
for i in range(100):
d = cv2.warpAffine(d,M,(10,10))
d = cv2.warpAffine(d,M2,(10,10))
print(d)
"""[[ 3 4 6 7 7 6 5 3 1 0] [ 4 7 10 12 12 10 9 6 3 1] [ 6 10 13 15 15 13 11 8 4 1] [ 7 12 15 16 16 14 12 8 5 2] [ 7 12 15 16 15 14 11 8 4 1] [ 6 10 13 14 14 12 9 6 3 1] [ 5 9 11 12 11 9 6 3 1 0] [ 3 6 8 8 8 6 3 1 0 0] [ 1 3 4 5 4 3 1 0 0 0] [ 0 1 1 2 1 1 0 0 0 0]] """
之後又用圖片測試了一下,發現不斷進行小數個像素的平移確實會變模糊。
既然知道了問題,那就很好解決,將原有圖片和新圖片需要平移的量四捨五入取整即可。
M = np.float32([[1,0,int(round(zuo[0]))],[0,1,int(round(zuo[1]))]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
M = np.float32([[1,0,int(round(you[0]))],[0,1,int(round(you[1]))]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
這裡只是對仿射變換所需的變換矩陣中進行取整,而不是直接修改pingyi,這樣可以避免不斷取整造成的誤差累計。
圖片說明: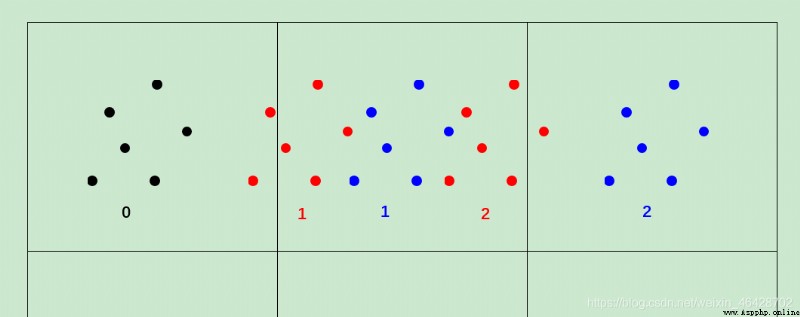
原來的黑色點0平移後應到紅色點1,但由於取整到了藍色點1,若直接修改pingyi,則第二次平移時會直接平移到藍色點2,誤差變大。而正確的平移是紅色點2,若對紅色點2取整,則結果還是藍色點1,誤差較小。
可以看到,左側仍舊露出了部分字幕。
仔細思考後,我發現了原因。
目前判斷鏡頭向上向下移動的變量是pingyi,但此變量實際的含義是從新圖片的左上角指向原有圖片的左上角的向量(np.array的坐標系以左上角作為原點),因此,在以下這種情況時可以正常判斷。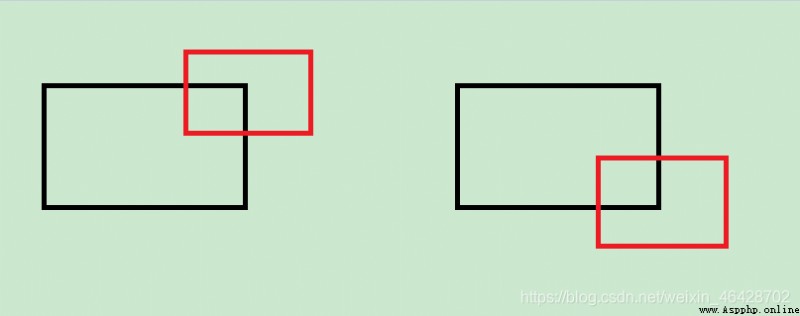
(黑色是原有圖片,紅色是新圖片)
但當這個鏡頭把右側和下面部分移動完,從左側向上移動時,新圖像的加入則不需要擴大原有圖像的尺寸了。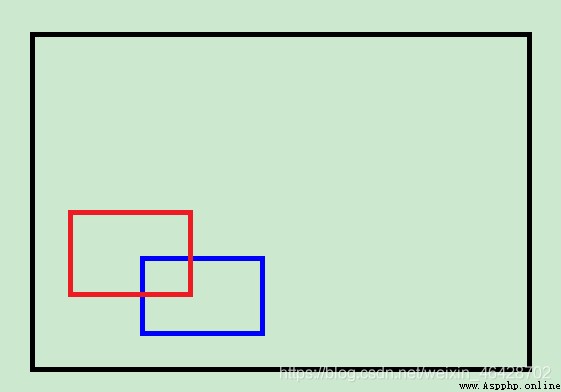
(黑色是原有圖片,紅色是新圖片,藍色是上一次的新圖片)
此時,按照正確的判斷方法,紅色圖片相對於藍色圖片的左上角是向上平移的,但是用目前的判斷方法的話,相對於黑色圖片的左上角是向下平移的,於是就會出現問題。
這個解決方法也很簡單,記錄上次的pingyi,每次用當前的pingyi減去上次的pingyi即為相對上次圖片平移的向量。
last_x,last_y=0,0
...
global kp1,des1,rows,cols,last_x,last_y
...
up_or_down=pingyi[1]-last_y
last_x,last_y=pingyi
...
if up_or_down<0:
...
else:
...
...
if up_or_down<0:
return leftdst
else:
return rightdst
解決以上問題後,再次運行,結果是這樣的:(原圖過大無法插入,這裡是縮小後的圖片)
可見效果好了很多,模糊和黑邊都沒有了,左側大片字幕沒有了,雖然有些地方還是有點錯位,字幕也沒有完全去掉,但總的來說效果還是不錯的。
(沒有模糊了,但是還是有錯位和字幕)
# 參考:https://blog.csdn.net/qq878594585/article/details/81901703
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pyod.models.knn import KNN
clf_name = 'KNN'
clf = KNN(0.5)
hessian=400
surf=cv2.SIFT_create(hessian) #將Hessian Threshold設置為400,阈值越大能檢測的特征就越少
rows,cols=0,0
last_x,last_y=0,0
def pinjie(leftgray,rightgray):
global kp1,des1,rows,cols,last_x,last_y
print("grayshape:",leftgray.shape,rightgray.shape)
kp2,des2=surf.detectAndCompute(rightgray,None) #查找關鍵點和描述符
FLANN_INDEX_KDTREE=0 #建立FLANN匹配器的參數
indexParams=dict(algorithm=FLANN_INDEX_KDTREE,trees=5) #配置索引,密度樹的數量為5
searchParams=dict(checks=50) #指定遞歸次數
#FlannBasedMatcher:是目前最快的特征匹配算法(最近鄰搜索)
flann=cv2.FlannBasedMatcher(indexParams,searchParams) #建立匹配器
matches=flann.knnMatch(des1,des2,k=2) #得出匹配的關鍵點
good=[]
#提取優秀的特征點
for m,n in matches:
if m.distance < 0.7*n.distance: #如果第一個鄰近距離比第二個鄰近距離的0.7倍小,則保留
good.append(m)
src_pts = np.array([ kp1[m.queryIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #查詢圖像的特征描述子索引
dst_pts = np.array([ kp2[m.trainIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #訓練(模板)圖像的特征描述子索引
#H=cv2.findHomography(src_pts,dst_pts) #生成變換矩陣
h,w=leftgray.shape[:2]
h1,w1=rightgray.shape[:2]
sandian=dst_pts-src_pts
print("sandian:",sandian.shape)
#plt.figure(1)
#plt.scatter(*sandian.T)
# 參考:https://blog.csdn.net/weixin_42199542/article/details/106885459
# train kNN detector
clf.fit(sandian)
# If you want to see the predictions of the training data, you can use this way:
#y_train_scores = clf.decision_scores_
#plt.figure(2)
y_test_pred = clf.predict(sandian)
sandian=sandian[y_test_pred==0]
pingyi=np.mean(sandian,0)
print("pingyi:",pingyi)
#plt.scatter(*sandian.T)
#plt.scatter(*pingyi,c='red')
# h,w是原有圖片的高和寬
# h1,w1是新圖片的高和寬
# zuo為原有圖片需要平移的向量
# you為新圖片需要平移的向量
# 因為最終是在一張大底圖上合成,所以有時原有圖片和新圖片都需要平移
# rows和cols是大底圖的高和寬
zuo,you=[0,0],[0,0]
for i in [0,1]:
if pingyi[i]>0:
zuo[i]=pingyi[i]
else:
you[i]=-pingyi[i]
if pingyi[1]<0:
if h1 + abs(int(round(pingyi[1]))) > rows:
rows = h1 + abs(int(round(pingyi[1])))
else:
if h + abs(int(round(pingyi[1]))) > rows:
rows = h + abs(int(round(pingyi[1])))
if pingyi[0]<0:
if w1 + abs(int(round(pingyi[0]))) > cols:
cols = w1 + abs(int(round(pingyi[0])))
else:
if w + abs(int(round(pingyi[0]))) > cols:
cols = w + abs(int(round(pingyi[0])))
print("rows:",rows,"cols",cols)
up_or_down=pingyi[1]-last_y
last_x,last_y=pingyi
if up_or_down<0: # 如果不加int和round會造成不斷進行小數的仿射變換,最會終產生模糊
M = np.float32([[1,0,int(round(zuo[0]))],[0,1,int(round(zuo[1]))]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
#cv2.namedWindow('leftdst', 0)
#cv2.imshow('leftdst',leftdst)
#cv2.namedWindow('rightdst', 0)
#cv2.imshow('rightdst',rightdst)
print("dstshape:",leftdst.shape)
weizhix=abs(int(round(you[0])))
weizhiy=abs(int(round(you[1])))
print("weizhi:",weizhix,weizhiy)
#cv2.imwrite(r'leftdst.png',leftdst)
#cv2.imwrite(r'rightgray.png',rightgray)
leftdst[weizhiy:weizhiy+h1,weizhix:weizhix+w1]=rightgray[:,:]
else:
M = np.float32([[1,0,int(round(you[0]))],[0,1,int(round(you[1]))]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
print("dstshape:",rightdst.shape)
weizhix=abs(int(round(zuo[0])))
weizhiy=abs(int(round(zuo[1])))
print("weizhi:",weizhix,weizhiy)
#rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,:3]=leftgray[:,:,:3]
#rightdst=cv2.addWeighted(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w],leftgray[:,:,2],leftgray[:,:,:3],1-leftgray[:,:,2],0)
alpha = leftgray[:,:,3] // 255.0
#print(alpha[:10,:10])
#result = np.zeros(rightdst.shape[:2]+(4,))
#cv2.imshow('result',result)
#cv2.imwrite(r'rightdst.png',rightdst)
#cv2.imwrite(r'leftgray.png',leftgray)
#cv2.waitKey(1000)
print(rightdst.shape[:2]+(4,),leftgray.shape)
print(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0].shape)
print(leftgray[weizhiy:weizhiy+h,weizhix:weizhix+w,1].shape)
print(weizhiy,weizhiy+h,weizhix,weizhix+w)
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] + alpha * leftgray[:,:,0]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] + alpha * leftgray[:,:,1]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] + alpha * leftgray[:,:,2]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3] = (1 - (1-rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3]//255) * (1-leftgray[:,:,3]//255)) * 255
#cv2.namedWindow('dst', 0)
#cv2.imshow('dst',leftdst)
#cv2.waitKey(1000)
#plt.show()
kp1,des1=kp2,des2
for j in kp1:
j.pt=(j.pt[0]+you[0],j.pt[1]+you[1])
if up_or_down<0:
return leftdst
else:
return rightdst
video = cv2.VideoCapture(r'60.mp4') # 讀取視頻
#for i in range(270):
# video.read()
ret, leftframe = video.read() # 讀取幀
b_channel, g_channel, r_channel = cv2.split(leftframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值為0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
leftframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('leftframe',leftframe)
kp1,des1=surf.detectAndCompute(leftframe,None) #查找關鍵點和描述符
i=0
while i<=3700:
#for i in range(1200): # 逐幀讀取
ret, rightframe = video.read() # 讀取下一幀
if not ret:
break
b_channel, g_channel, r_channel = cv2.split(rightframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值為0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
rightframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('frame',frame)
#if i%5==0:
print(i)
leftframe=pinjie(leftframe,rightframe)
#cv2.namedWindow('dst', 0)
#cv2.imshow('dst',leftframe)
#cv2.waitKey(1000)
print()
cv2.imwrite(r'dst.png',leftframe)
i+=1
將圖片的仿射變換改成透視變換,再通過cv2.VideoCapture調用手機的攝像頭,即可進行手機拍攝照片的全景拼接。(手機運行Python可用Aid-learning、QPython 3、Pydroid 3、Termux、Linux Deploy等,也可將圖片傳輸至電腦,在電腦上拼接)