目錄
(1)數據集背景介紹
(2)讀取數據並導入需要的第三方庫
(3)通過判斷每個屬性的取值范圍來估計屬性及其類型
(4)刪除數據值前的空格,調整數據格式
(5)處理缺失數據
(6)屬性可視化分析及數據變換
①"age" 年齡分析
②"workclass" 工作類型分析
③"education" 學歷分析
④"education_num" 受教育時間分析
⑤"marital_status" 婚姻狀態分析
⑥"occupation" 職業分析
⑦"relationship" 關系分析
⑧"race" 種族分析
⑨"sex" 性別
⑩"capital_gain" 資本收益 與 "capital_loss" 資本損失之間的關系分析
⑪"capital_gain" 資本收益分析
⑫"capital_loss" 資本損失分析
⑬"hours_per_week" 每周工作小時數分析
⑭"native_country" 原籍分析
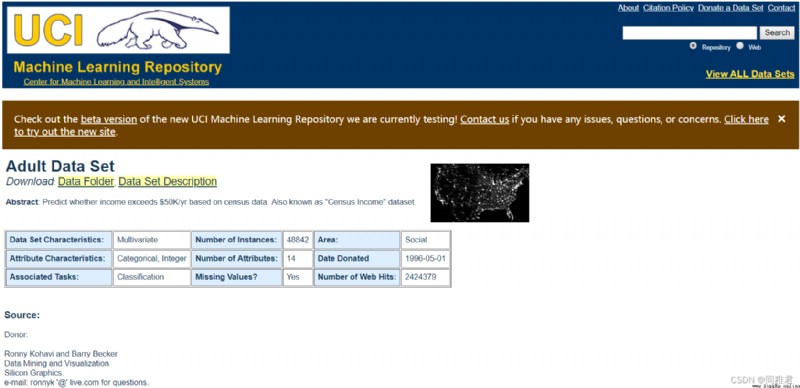
數據來源於1994年美國人口普查數據庫。(下載地址https://archive.ics.uci.edu/ml/datasets/Adult)
該數據集共32560條數據,15個變量。
數據詳細說明地址:Index of /ml/machine-learning-databases/adult
需要用到的數據分析工具包有:numpy、pandas
需要用到的數據可視化工具包有:pyecharts、matplotlib、missingno、seaborn
import csv
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts import options as opst
import matplotlib.pyplot as plt
import missingno as msno
import numpy as np
import pandas as pd
import seaborn as sns
iris_file = open("income dataset/adult.data", "r", encoding='utf-8')
reader = csv.reader(iris_file)
dataSet = []
for row in reader:
dataSet.append(row)
假設我們目前還不清楚數據集各個特征屬性的詳細信息(如名稱、數據類型、數據量等),通過提取各個屬性的取值范圍(即非重復值)來估計該屬性的一些情況。
def AttributeTypeJudgment(dataSet):
attributeNum = len(dataSet[0]) #計算屬性個數,包括最後的類別
uniqueAttributeDict = {}
for i in range(attributeNum): #遍歷每個屬性
attributeValueList = []
for j in range(len(dataSet)):
attributeValueList.append(dataSet[j][i])
uniqueAttributeValue = list(set(attributeValueList)) #將屬性值去重,得到第i個屬性的取值的范圍
uniqueAttributeDict[i] = uniqueAttributeValue
print(i, ":", uniqueAttributeValue)
return uniqueAttributeDict
AttributeTypeJudgment(dataSet)第 0 個屬性所有非重復值:

第1個屬性所有非重復值:
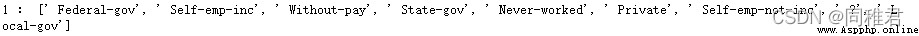
第2個屬性部分非重復值:

第3個屬性所有非重復值:

······
第13個屬性部分非重復值:

類別所有非重復值:
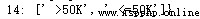
通過對每個屬性所有非重復值的觀察與分析,可以猜測到部分屬性可能的名稱,以及判斷每一個屬性的值的數據類型。再通過查找關於該數據集的介紹性的資料,得出該數據集各個屬性名稱及數據類型如下:
屬性
名稱
屬性類型
數據格式
age
年齡
離散屬性
Int64
workclass
工作類型
標稱屬性
object
fnlwgt
序號
連續屬性
Int64
education
學歷
標稱屬性
object
education_num
受教育時間
連續屬性
Int64
marital_status
婚姻狀態
標稱屬性
object
occupation
職業
標稱屬性
Object
relationship
關系
標稱屬性
Object
race
種族
標稱屬性
Object
sex
性別
二元屬性
object
capital_gain
資本收益
連續屬性
Int64
capital_loss
資本損失
連續屬性
Int64
hours_per_week
每周工作小時數
離散屬性
Int64
native_country
原籍
標稱屬性
object
類別
名稱
數據格式
wage_class
收入類別
Object
可以注意到數據集裡面的每一個數據的數據類型都是字符串類型,並且開頭存在一個空格,因此需要先去除每個數據前的空格,並且把每個特征數據裡面的數據類型由字符串轉換成其對應有的數據類型。
attributeLabels = ["age", #年齡 int64 離散屬性
"workclass", #工作類型 object 標稱屬性 有缺失
"fnlwgt", #序號 int64 連續屬性
"education", #學歷 boject 標稱屬性
"education_num", #受教育時間 int64 連續屬性
"marital_status", #婚姻狀態 object 標稱屬性
"occupation", #職業 object 標稱屬性 有缺失
"relationship", #關系 object 標稱屬性
"race", #種族 object 標稱屬性
"sex", #性別 object 二元屬性
"capital_gain", #資本收益 int64 連續屬性
"capital_loss", #資本損失 int64 連續屬性
"hours_per_week", #每周工作小時數 int64 離散屬性
"native_country", #原籍 object 標稱屬性 有缺失
"wage_class"] #收入類別 object 二元屬性
# 更改數據集格式為pandas 的DataFrame格式
dataFrame = pd.DataFrame(dataSet, columns=attributeLabels)
# 將缺失值部分的“ ?” 置為空,即 np.NaN,便於使用pandas來處理缺失值
newDataFrame = dataFrame.replace(" ?", np.NaN)
#刪除數據值前的空格
for label in attributeLabels:
newDataFrame[label] = newDataFrame[label].str.strip()
# 更改數據集中每一種數的值的數據格式,當前全為字符串對象,以便接下來的可視化分析
# 將"age"、"fnlwgt"、“education_num”、"capital_gain"、“capital_loss”、“hours_per_week” 改為 int64 類型
newDataFrame[['age', 'fnlwgt', 'education_num',
'capital_gain', 'capital_loss',
'hours_per_week']] = newDataFrame[['age', 'fnlwgt',
'education_num', 'capital_gain',
'capital_loss', 'hours_per_week']].apply(pd.to_numeric)
#查看對數據集數據分布的描述
print(newDataFrame.describe())
數據集中數值型屬性數據分布如下:

首先查看有數據缺失的屬性:
#可視化查看特征屬性缺失值
msno.matrix(newDataFrame, labels=True, fontsize=9) # 矩陣圖
plt.show()
可以直觀看出屬性“workclass”、“occupation”、“native_country”存在缺失值,數據集中樣本總數為32561個。
再查看具體缺失數量:
print(newDataFrame.describe())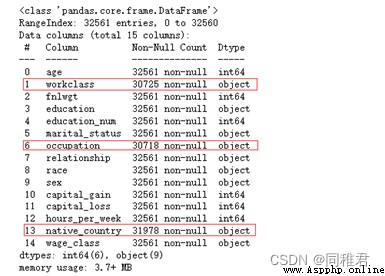
可以看到,三個屬性的缺失值數量均較少,因此可以采取補的方法,由於這三個屬性均是標稱屬性,所以可以采取用屬性中出現次數最多的值來代替(即使用最有可能值來代替缺失值)。三個屬性中出現次數最多的值分別為:“Private”、“Prof-specialty”、“United-States”。
#填補屬性workclass缺失值, 是標稱屬性,且缺失數量較少,所以用出現次數最多的值來代替(即使用最有可能值)
print(newDataFrame['workclass'].value_counts())
newDataFrame['workclass'].fillna("Private", inplace=True)
#填補屬性occupation缺失值, 是標稱屬性,且缺失數量較少,所以用出現次數最多的值來代替(即使用最有可能值)
print(newDataFrame['occupation'].value_counts())
newDataFrame['occupation'].fillna("Prof-specialty", inplace=True)
#填補屬性native_country缺失值, 是標稱屬性,且缺失數量較少,所以用出現次數最多的值來代替(即使用最有可能值)
print(newDataFrame['native_country'].value_counts())
newDataFrame['native_country'].fillna("United-States", inplace=True)# "age" 年齡分析
page_age = Page()
print(newDataFrame['age'].describe())
#查看年齡分布
# plt.hist(newDataFrame['age'], bins =20)
# plt.show()
#根據取值將年齡分段,年齡為[17,30) [30,65) [65,100), 段標簽為:youth、middleAged、elderly
newDataFrame['age'] = pd.cut(newDataFrame['age'], bins=[16, 30, 65, 100], labels=['youth', 'middleAged', 'elderly'])
#各個年齡段人數柱形圖
# print(newDataFrame['age'].value_counts())
x_age = list(dict(newDataFrame['age'].value_counts()).keys()) #獲取年齡段列表
y_age= list(newDataFrame['age'].value_counts()) #獲取各個年齡段的人數值
bar_age = (
Bar(init_opts=opts.InitOpts(theme="romantic"))
.add_xaxis(x_age)
.add_yaxis("人數", y_age, label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="年齡段人數柱形圖", pos_left="left"),
legend_opts=opts.LegendOpts(is_show=True))
)
y_age_wageclass1 = [
len(list(newDataFrame.loc[(newDataFrame['age']=='middleAged')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['age']=='youth')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['age']=='elderly')&(newDataFrame['wage_class']=='<=50K'), 'wage_class']))
]
y_age_wageclass2 = [
len(list(newDataFrame.loc[(newDataFrame['age'] == 'middleAged') & (newDataFrame['wage_class'] == '>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['age'] == 'youth') & (newDataFrame['wage_class'] == '>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['age'] == 'elderly') & (newDataFrame['wage_class'] == '>50K'), 'wage_class']))
]
#各年齡段收入類別堆疊柱形圖
stackBar_age = (
Bar(init_opts=opts.InitOpts(theme="romantic"))
.add_xaxis(x_age)
.add_yaxis("<=50K", y_age_wageclass1, stack=True)
.add_yaxis(">50K", y_age_wageclass2, stack=True)
.set_global_opts(title_opts=opst.TitleOpts(title="各年齡段收入類別堆疊柱形圖", pos_left="left"),
legend_opts=opst.LegendOpts(is_show=True, pos_left="center"))
)
page_age.add(bar_age, stackBar_age)
page_age.render("charts/age.html")由於“age”屬性值處於[16, 100]區間之間,且年齡大小與收入相關性較大,因此可以將年齡根據實際劃分為3個年齡段 [17,30)、[30,65)、[65,100),年齡段標簽為:youth、middleAged、elderly,用年齡段標簽來代替具體數值,使數據集適合用於分類模型。
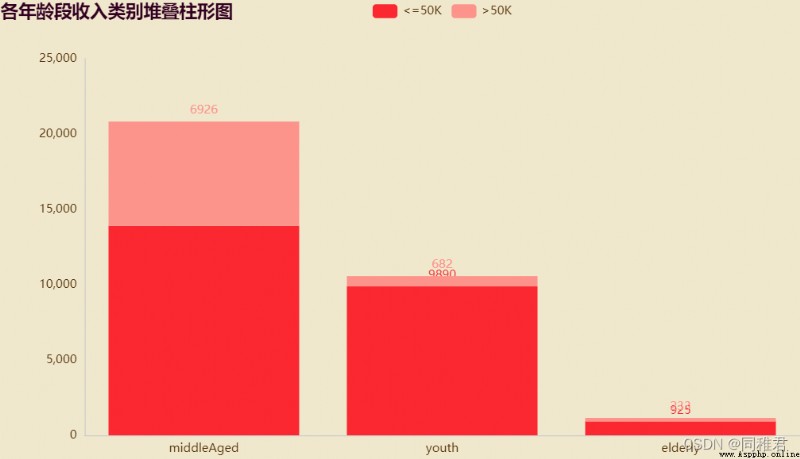
從圖中可以直觀看出,三個年齡段中中年階段收入>50K的人數占比最大,青年階段和老年階段人的收入大多<=50K。並且中年階段的人數在數據集中占比最多。
# "workclass" 工作類型分析
page_workclass = Page()
# print(dict(newDataFrame['workclass'].value_counts()))
x_workclass = list(dict(newDataFrame['workclass'].value_counts()).keys())
print(x_workclass)
y_workclass = list(newDataFrame['workclass'].value_counts())
bar_workclass = (
Bar(init_opts=opts.InitOpts(theme="chalk"))
.add_xaxis(x_workclass)
.add_yaxis("人數", y_workclass, label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="各工作類型人數柱形圖", pos_left="left"),
legend_opts=opts.LegendOpts(is_show=True))
)
y_workclass_wageclass1 = [
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Private')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Self-emp-not-inc')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Local-gov')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='State-gov')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Self-emp-inc')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Federal-gov')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Without-pay')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Never-worked')&(newDataFrame['wage_class']=='<=50K'), 'wage_class'])),
]
y_workclass_wageclass2 = [
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Private')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Self-emp-not-inc')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Local-gov')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='State-gov')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Self-emp-inc')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Federal-gov')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Without-pay')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
len(list(newDataFrame.loc[(newDataFrame['workclass']=='Never-worked')&(newDataFrame['wage_class']=='>50K'), 'wage_class'])),
]
#各工作類別收入類別堆疊柱形圖
stackBar_workclass = (
Bar(init_opts=opts.InitOpts(theme="chalk"))
.add_xaxis(x_workclass)
.add_yaxis("<=50K", y_workclass_wageclass1, stack=True)
.add_yaxis(">50K", y_workclass_wageclass2, stack=True)
.set_global_opts(title_opts=opst.TitleOpts(title="各工作類別入類別堆疊柱形圖", pos_left="left"),
legend_opts=opst.LegendOpts(is_show=True, pos_left="center"))
)
page_workclass.add(bar_workclass, stackBar_workclass)
page_workclass.render("charts/workclass.html")“workclass”本身是標稱屬性,因此除了填補缺失值外不需要過多的進行改變。從下圖中可以看出“Private”私營類工作者人數最多,收入>50K占比最多的是“Self-emp-inc” 自由職業者類。
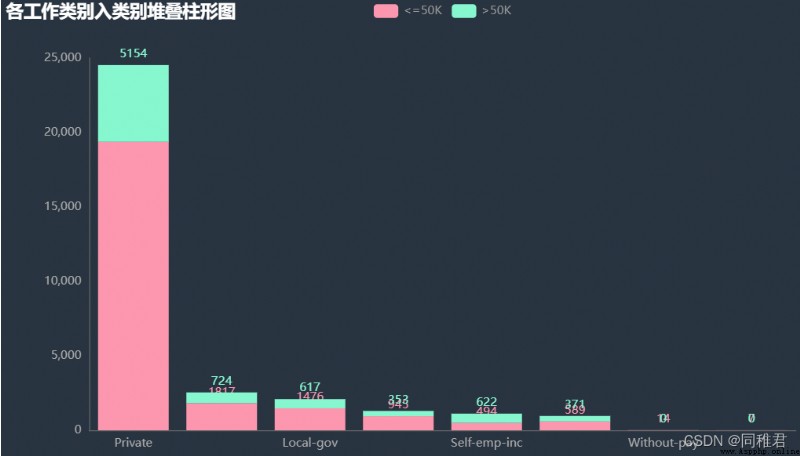
# "education" 學歷分析
print(list(dict(newDataFrame['education'].value_counts()).keys()))
sns.countplot('education', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=8, rotation=-45)
plt.show()
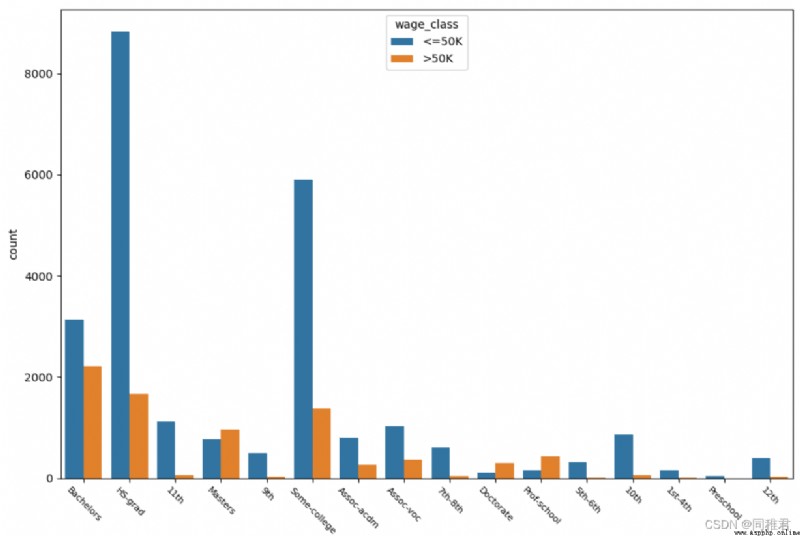
“education”是標稱屬性,取值有:
'HS-grad', 'Some-college', 'Bachelors', 'Masters', 'Assoc-voc', '11th', 'Assoc-acdm', '10th', '7th-8th', 'Prof-school', '9th', '12th', 'Doctorate', '5th-6th', '1st-4th', 'Preschool'。從下圖可以看出,學歷越高收入>50K的占比越高,大部分人受過高等教育。
# "education_num" 受教育時間分析
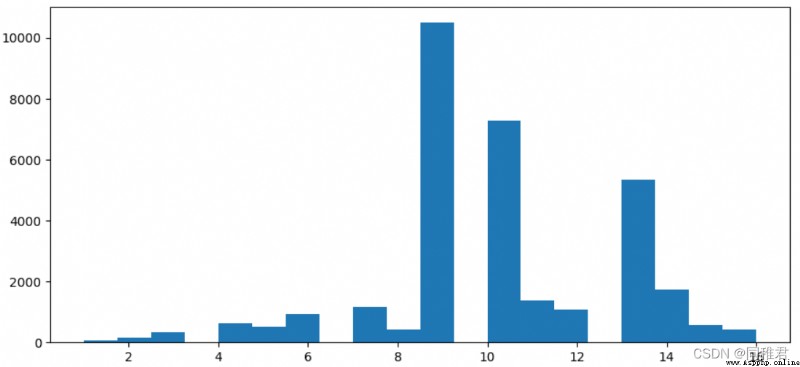
#查看教育時間詳情
print(newDataFrame['education_num'].describe())
#查看教育時間分布
plt.hist(newDataFrame['education_num'], bins =20)
plt.show()
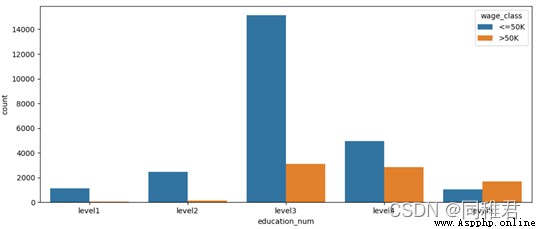
#將教育時間離散化,分為5個層次:level1、level2、...、level5,
newDataFrame['education_num'] = pd.cut(newDataFrame['education_num'], bins=5, labels=['level1', 'level2', 'level3', 'level4', 'level5'])
sns.countplot('education_num', hue='wage_class', data=newDataFrame)
plt.show()“education_num”是連續屬性,因此可以將其離散化,從下方的受教育時間數據分布直方圖來看,受教育時間可以分為5類,因此用等距法來畫分數據,劃分為'level1', 'level2', 'level3', 'level4', 'level5'五個范圍。劃分後可以直觀看出受教育時間處於中等層次的人數最多,越往後收入>50K占比越高。
其次“education”與“education_num”屬性含義重復程度較高,在建模時可以考慮去除其中一個屬 性,以降低數據冗余。
# "marital_status" 婚姻狀態分析
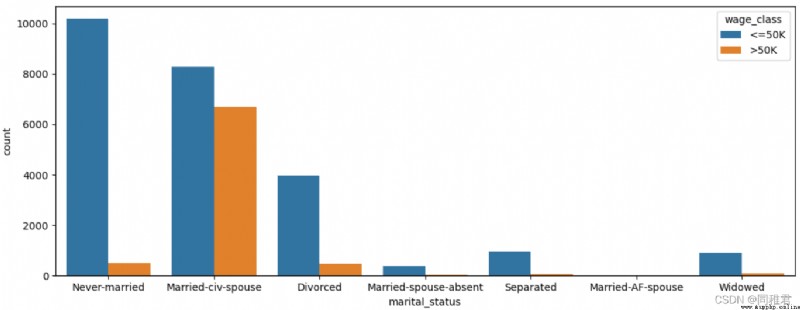
print(list(dict(newDataFrame['marital_status'].value_counts()).keys()))
sns.countplot('marital_status', hue='wage_class', data=newDataFrame)
plt.show()下圖可以看出單身人群收入普遍小於等於50K。
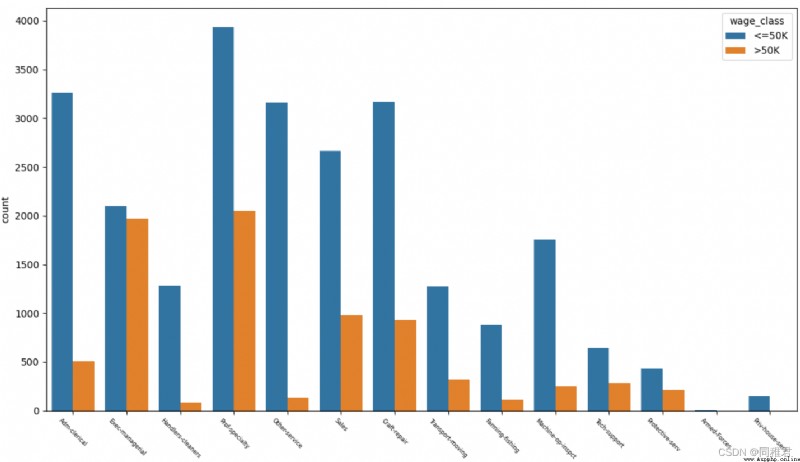
# "occupation" 職業分析
print(list(dict(newDataFrame['occupation'].value_counts()).keys()))
sns.countplot('occupation', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=6, rotation=-45) #調整x軸標簽字體大小
plt.show()從下圖中可以直觀看出高收入占比比較高的是Exec-managerial、Prof-specialty,比較低的是Handlers-cleaners、Farming-fishing。
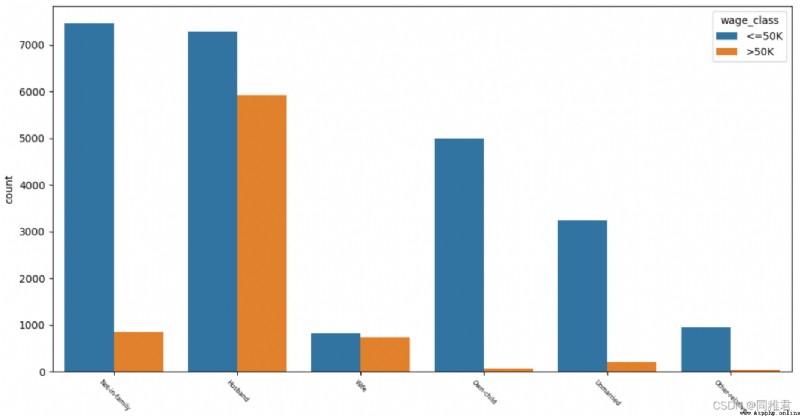
# "relationship" 關系分析
print(list(dict(newDataFrame['relationship'].value_counts()).keys()))
sns.countplot('relationship', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=6, rotation=-45) #調整x軸標簽字體大小
plt.show()從下圖中可以看出擁有家庭的人的收入普遍較高,其中“妻子”角色工作人數較少,說明家庭中一般是“丈夫”在工作。未結婚或有孩子的人的收入普遍小於等於50K。
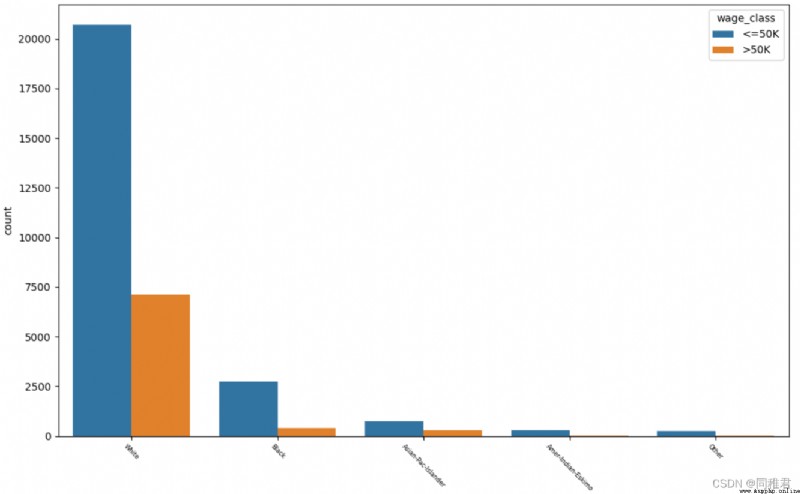
# "race" 種族分析
print(list(dict(newDataFrame['race'].value_counts()).keys()))
sns.countplot('race', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=6, rotation=-45) #調整x軸標簽字體大小
plt.show()從下圖中可以看出白人在總人數中占比最高,白人與亞洲太平洋島民收入>50K占比較高,黑人中高收入群體占比較低。
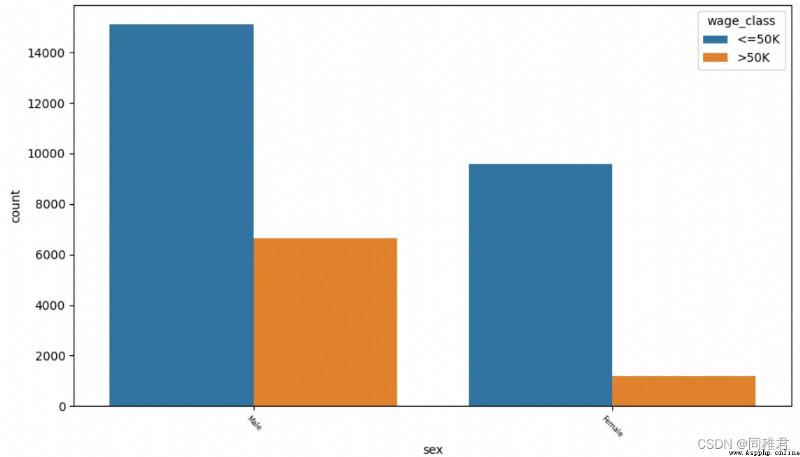
# "sex" 性別
print(list(dict(newDataFrame['sex'].value_counts()).keys()))
sns.countplot('sex', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=6, rotation=-45) #調整x軸標簽字體大小
plt.show()從下圖中可以看出男性在人數以及高收入占比上均高於女性。
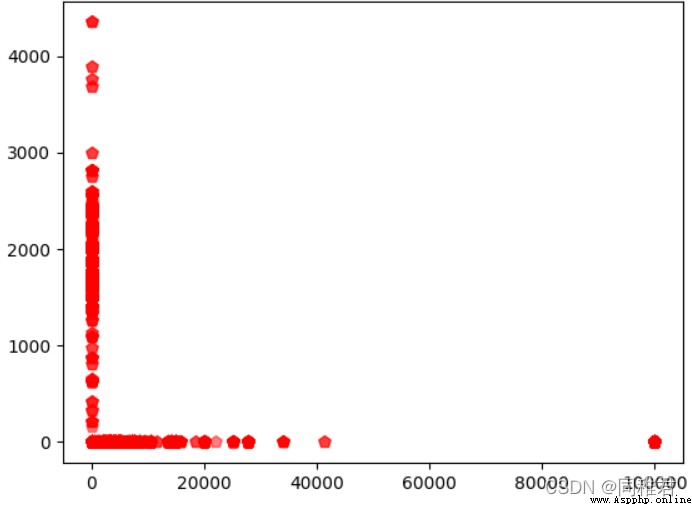
#"capital_gain" 資本收益 與 "capital_loss" 資本損失之間的關系分析,散點圖
x = list(newDataFrame['capital_gain'])
y = list(newDataFrame['capital_loss'])
print(len(x) == len(y))
plt.scatter(x, y, s=50, c="r", marker="p", alpha=0.5)
plt.show()可以看出資本收益與資本損失並不成某種定量關系,反而是程兩極關系,存在三種情況:有損失無收益、有收益無損失、既無收益也無損失。
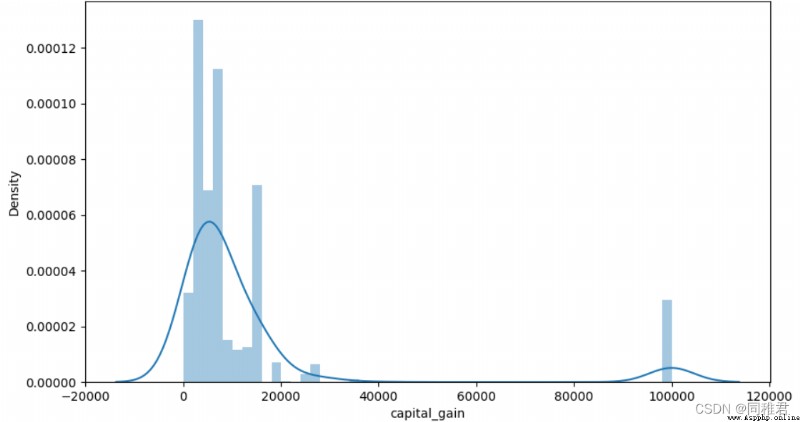
# "capital_gain" 資本收益分析
#查看資本收益詳情
print(newDataFrame['capital_gain'].describe())
#查看資本收益分布
# plt.hist(newDataFrame['capital_gain'], bins =10)
plt.subplots(figsize=(7,5))
sns.distplot(newDataFrame['capital_gain'][newDataFrame['capital_gain']!=0])
plt.show()
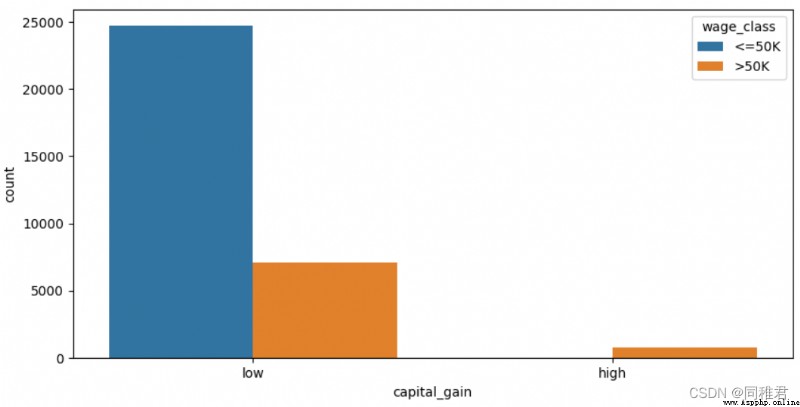
# 將資本收益離散化,分為2個層次:low [0,10000),high[10000, 100000)
newDataFrame['capital_gain'] = pd.cut(newDataFrame['capital_gain'], bins=[-1, 10000, 100000], labels=['low', 'high'])
sns.countplot('capital_gain', hue='wage_class', data=newDataFrame)
plt.show()“capital_gain”屬性為連續屬性,因此可以離散化,首先查看資本收益數據分布情況,可以看到大部分人收益小於10000$。根據數據分布可以將資本收益分為low和high兩個層次。離散化後可以看出低資本收益的人占大多數,高資本收益的人高收入占比也高。
# "capital_loss" 資本損失分析
#查看資本損失詳情
print(newDataFrame['capital_loss'].describe())
#查看資本損失分布
plt.subplots(figsize=(7,5))
sns.distplot(newDataFrame['capital_loss'][newDataFrame['capital_loss']!=0])
plt.show()
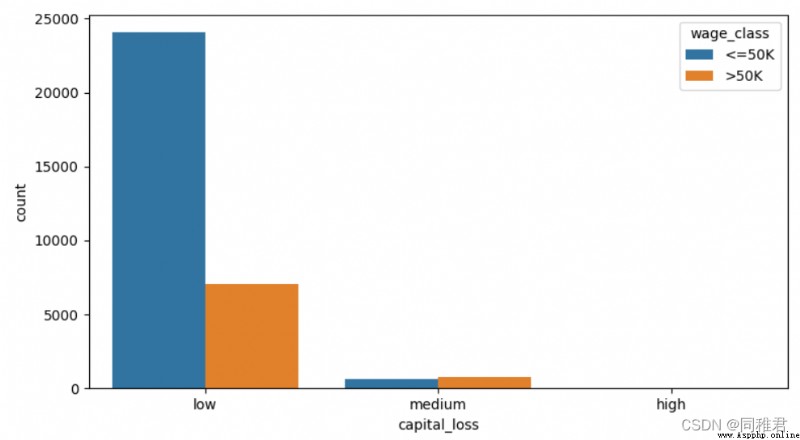
# 將資本損失離散化,分為2個層次:low [0,1000),high[1000, 5000)
newDataFrame['capital_loss'] = pd.cut(newDataFrame['capital_loss'], bins=3, labels=['low', 'medium', 'high'])
sns.countplot('capital_loss', hue='wage_class', data=newDataFrame)
plt.show()同樣的,從資本損失數據分布上分析,可以將資本損失離散化,等距分為“low”、“medium”、“high”三個層次。從離散化後的圖表上可以看出資本損失高的群體其高收入人群占比反而高於第資本損失群體。

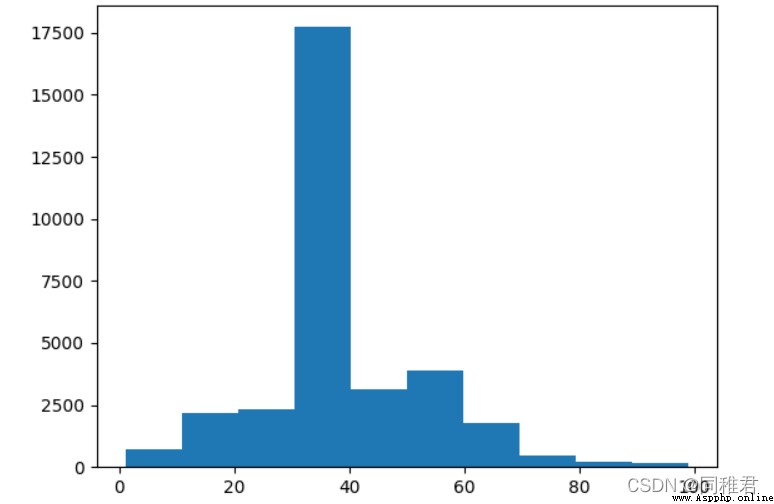
# "hours_per_week" 每周工作小時數分析
#查看每周工作小時數詳情
print(newDataFrame['hours_per_week'].describe())
#查看每周工作小時數分布
plt.hist(newDataFrame['hours_per_week'], bins =10)
plt.show()
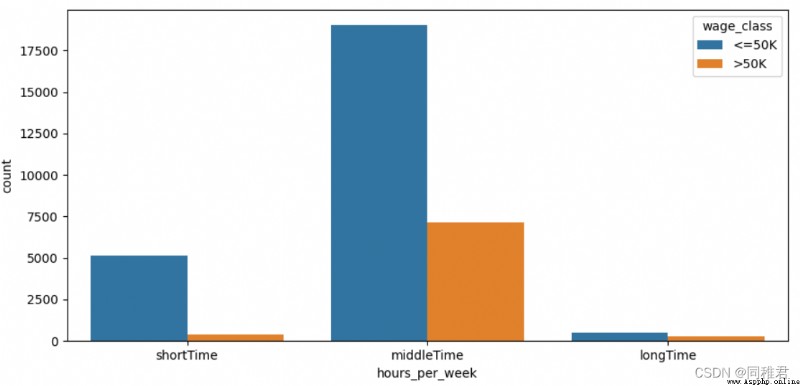
# 將每周工作小時數離散化,分為3個層次:短時、中時、長時
newDataFrame['hours_per_week'] = pd.cut(newDataFrame['hours_per_week'], bins=3, labels=['shortTime', 'middleTime', 'longTime'])
sns.countplot('hours_per_week', hue='wage_class', data=newDataFrame)
plt.show()“hours_per_week”是連續屬性,因此也需要離散化。從每周工作小時數數據分布直方圖上看,可以將每周工作小時數等距劃分為3個層次:'shortTime', 'middleTime', 'longTime'。從劃分後的圖表上看,隨著每周工作小時數的增加,高收入占比也在增高。
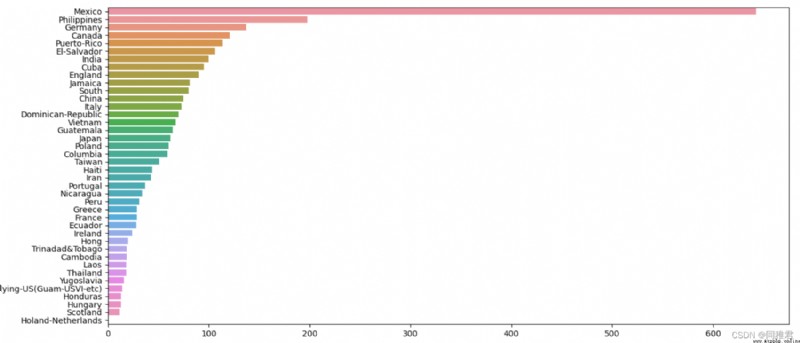
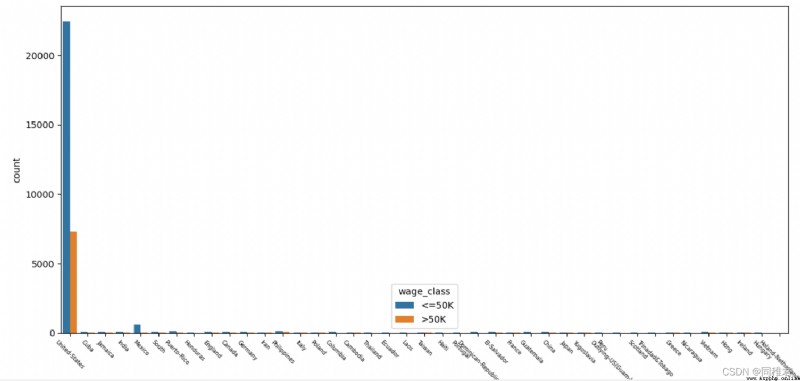
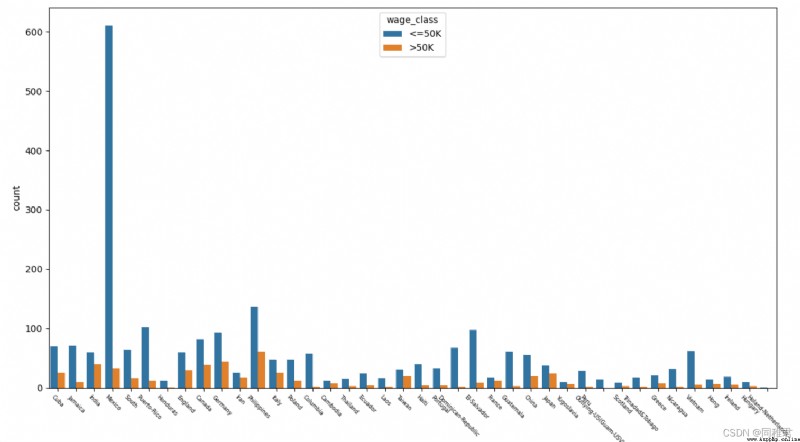
# "native_country" 原籍分析, 可以分為 發達國家和發展中國家兩類
print(list(dict(newDataFrame['native_country'].value_counts()).keys()))
# sns.countplot('native_country', hue='wage_class', data=newDataFrame[newDataFrame['native_country'] != 'United-States'])
sns.countplot('native_country', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=6, rotation=-45) #調整x軸標簽字體大小
plt.subplots(figsize=(5, 7))
s=newDataFrame['native_country'].value_counts()
sns.barplot(y=s.index,x=s.values)
plt.show()從下圖中可以看出美國籍樣本占了絕大部分,Mexico,Philippines,Germany籍樣本,由於美國籍樣本數量過多,影響了其他國際樣本數據在圖表中的顯示,所以在繪制原籍樣本數量條形圖和原籍收入柱形圖中分別繪制包含原籍'United-States'的圖表和不包含'United-States'的圖表。
本文通過美國人口普查年收入數據集演示了對原始數據的數據挖掘與探索過程,包括數據預處理、特征工程、數據轉換、數據可視化分析過程,《數據挖掘導論》與《數據挖掘-實用機器學習工具與技術》提供理論指導。希望通過本文對大家學習數據挖掘有所幫助,對數據進行挖掘是為了更好地進行加下來的數據建模。