DataFrame.sum(axis=None,skipna=None,level=None,numeric_only=None,min_count=0,**kwargs)
NaN表示非數值。在進行數據處理、數據計算時,Pandas會為缺少的值自動分配NaN值。
import pandas as pd
data = [[110,105,99],[105,88,115],[109,120,130]]
index = [1,2,3]
columns = ['語文','數學','英語']
df = pd.DataFrame(data=data, index=index, columns=columns)
df
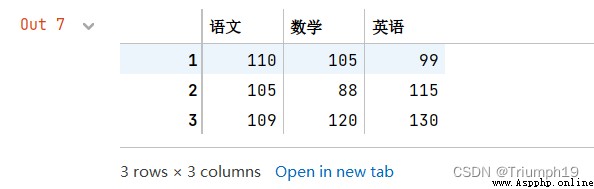
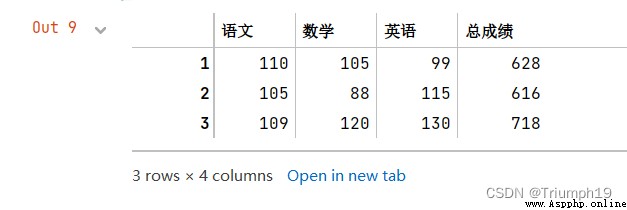
df['總成績']=df.sum(axis=1)
df
DataFrame.mean(axis=None,skipna=None,level=None,numeric_only=None,**kwargs)
import pandas as pd
data = [[110,105,99],[105,88,115],[109,120,130],[112,115]]
index = [1,2,3,4]
columns = ['語文','數學','英語']
df = pd.DataFrame(data=data, index=index, columns=columns)
df
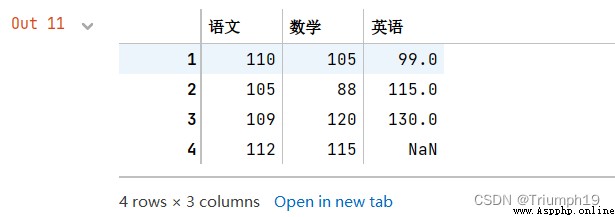
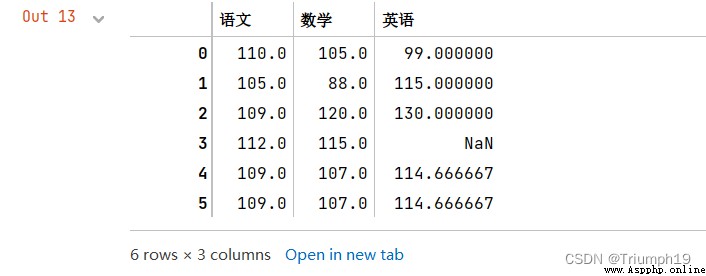
new=df.mean()
#增加一行數據(語文、數學和英語的平均值,忽略索引)
df=df.append(new,ignore_index=True)
df
DataFrame.max(axis=None,skipna=None,level=None,numeric_only=None,**kwargs)
new=df.max()
#增加一行數據(語文、數學和英語的最大值,忽略索引)
df=df.append(new,ignore_index=True)
df
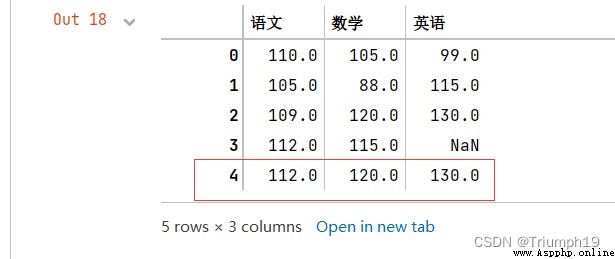
DataFrame.min(axis=None,skipna=None,level=None,numeric_only=None,**kwargs)
new=df.min()
#增加一行數據(語文、數學和英語的最小值,忽略索引)
df=df.append(new,ignore_index=True)
df
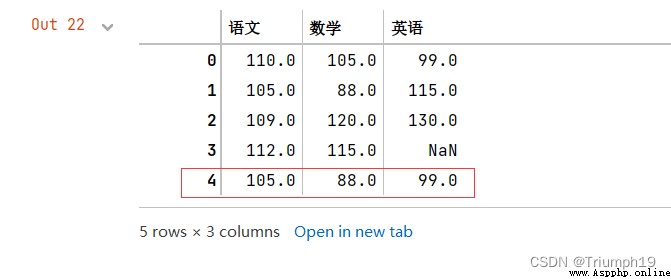
DataFrame.median(axis=None,skipna=None,level=None,numeric_only=None,**kwargs)
import pandas as pd
data = [[110,120,110],[130,130,130],[130,120,130]]
columns = ['語文','數學','英語']
df = pd.DataFrame(data=data,columns=columns)
new=df.median()
#增加一行數據(語文、數學和英語的中位數,忽略索引)
df=df.append(new,ignore_index=True)
df

DataFrame.mode(axis=0,numeric_only=False,dropna=True)
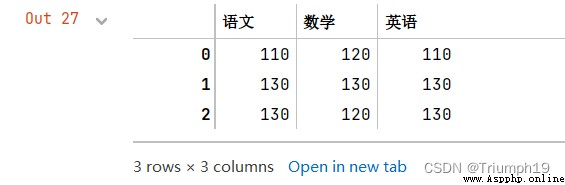
import pandas as pd
data = [[110,120,110],[130,130,130],[130,120,130]]
columns = ['語文','數學','英語']
df = pd.DataFrame(data=data,columns=columns)
df
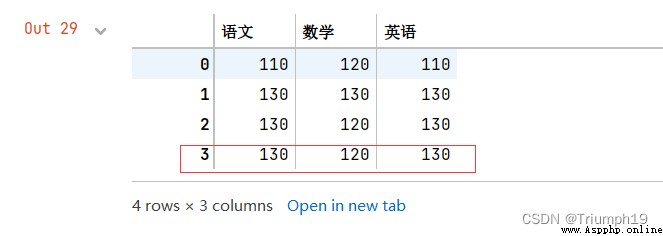
new=df.mode() #計算三科成績的眾數
#df.mode(axis=1) #每一行的眾數
#df['數學'].mode() #“數學”的眾數
#增加一行數據(語文、數學和英語的中位數,忽略索引)
df=df.append(new,ignore_index=True)
df
DataFrame.var(axis=None,skipna=None,level=None,ddof=1,numeric_only=None,**kwargs)
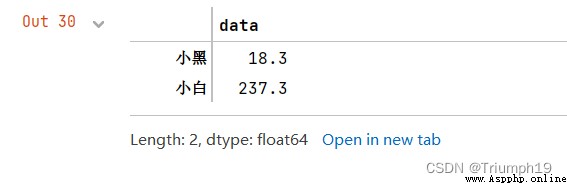
import pandas as pd
import numpy as np
data = [[110,113,102,105,108],[118,98,119,85,118]]
index=['小黑','小白']
columns = ['物理1','物理2','物理3','物理4','物理5']
df = pd.DataFrame(data=data,index=index,columns=columns)
df.var(axis=1)
DataFrame.std(axis=None,skipna=None,level=None,ddof=1,numeric_only=None,**kwargs)
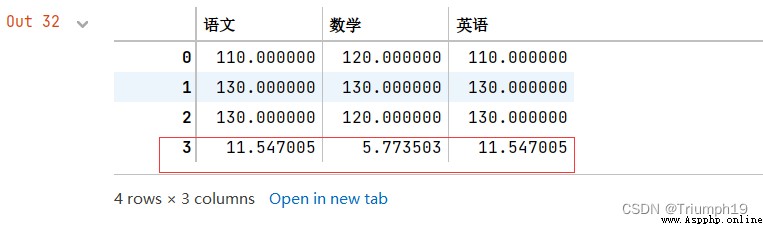
import pandas as pd
import numpy as np
data = [[110,120,110],[130,130,130],[130,120,130]]
columns = ['語文','數學','英語']
df = pd.DataFrame(data=data,columns=columns)
new = df.std()
#增加一行數據(語文、數學和英語的標准差,忽略索引)
df=df.append(new,ignore_index=True)
df
DataFrame.quantile(q=0.5,axis=0,numeric_only=True,interpolation='linear')
import pandas as pd
#創建DataFrame數據(數學成績)
data = [120,89,98,78,65,102,112,56,79,45]
columns = ['數學']
df = pd.DataFrame(data=data,columns=columns)
#計算35%的分位數
x=df['數學'].quantile(0.35)
#輸出淘汰學生
df[df['數學']<=x]

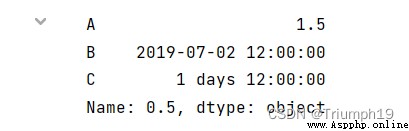
import pandas as pd
df = pd.DataFrame({
'A': [1, 2],
'B': [pd.Timestamp('2019'),
pd.Timestamp('2020')],
'C': [pd.Timedelta('1 days'),
pd.Timedelta('2 days')]})
print(df.quantile(0.5, numeric_only=False))
DataFrame.round(decimals=0,*args,**kwargs)
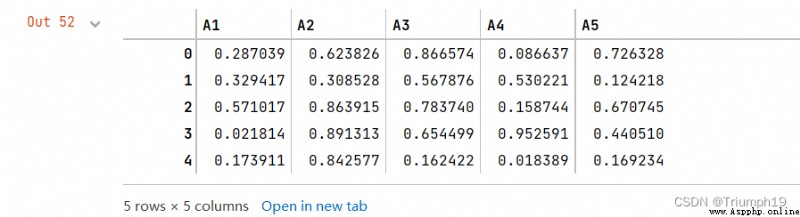
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5, 5]),
columns=['A1', 'A2', 'A3','A4','A5'])
df
df.loc[:,'A1':'A3']=df.round(2)#將A1至A3列保留小數點後兩位
df
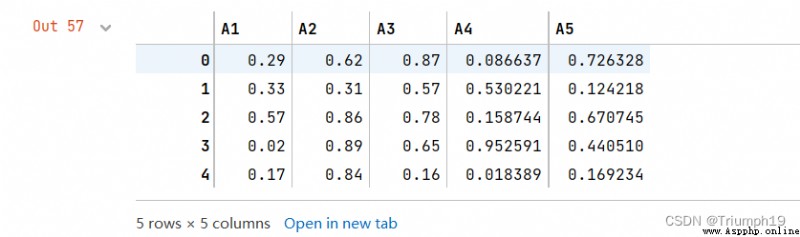
df.round({
'A1': 1, 'A3': 2}) #A1列保留小數點後一位、A3列保留小數點後兩位
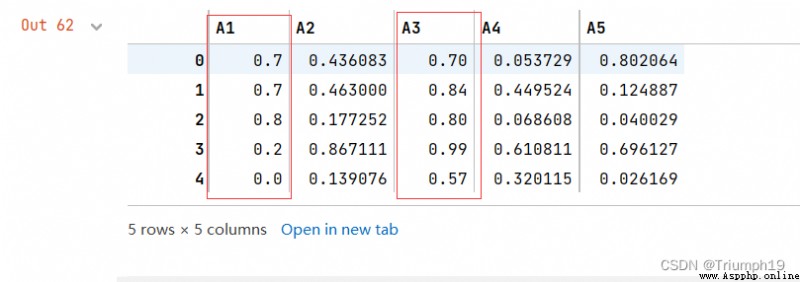
s1 = pd.Series([1, 0, 2], index=['A1', 'A2', 'A3']) #A1保留1位小數,A2列保留0位小數,A3列保留2位小數。
df.round(s1) #設置Series對象小數位數
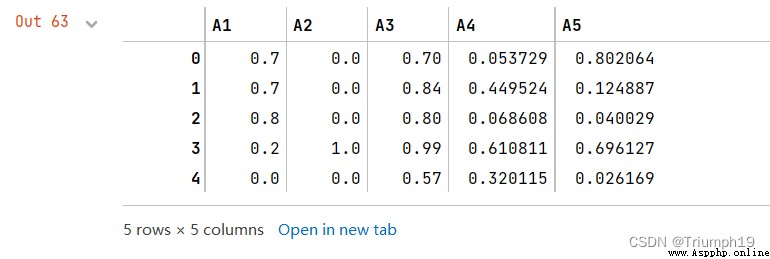
df.applymap(lambda x: '%.2f'%x) #通過自定義函數設置小數位數,返回類型為object
經過自定義函數處理過的數據將不再是浮點型而是對象型,如果後續計算需要數據,則應先進行數據類型轉換。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([5, 5]),
columns=['A1', 'A2', 'A3','A4','A5'])
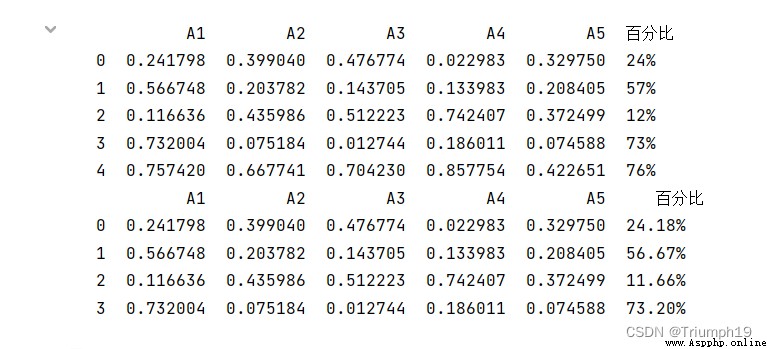
df['百分比']=df['A1'].apply(lambda x: format(x,'.0%')) #整列保留0位小數
print(df)
df['百分比']=df['A1'].apply(lambda x: format(x,'.2%')) #整列保留兩位小數
print(df)
df['百分比']=df['A1'].map(lambda x:'{:.0%}'.format(x)) #整列保留0位小數,也可以使用map函數
print(df)
import pandas as pd
data = [['零基礎學Python','1月',49768889],['零基礎學Python','2月',11777775],['零基礎學Python','3月',13799990]]
columns = ['圖書','月份','碼洋']
df = pd.DataFrame(data=data, columns=columns)
df['碼洋']=df['碼洋'].apply(lambda x:format(int(x),','))
print(df)
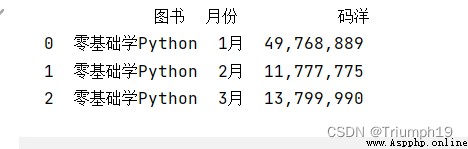
設置千位分隔符後,對於程序來說,這些數據將不再是數值型,而是數字和逗號組成的字符串,如果由於程序需要再變成數值型就會很麻煩,因此設置千位分隔符要慎重。
DataFrame.group(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=False,observed=False)
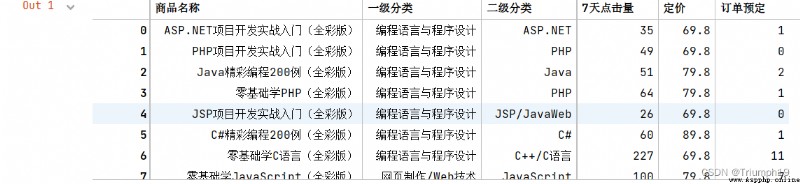
import pandas as pd #導入pandas模塊
df=pd.read_csv('JD.csv',encoding='gbk')
df
#抽取數據
df1=df[['一級分類','7天點擊量','訂單預定']]
df1
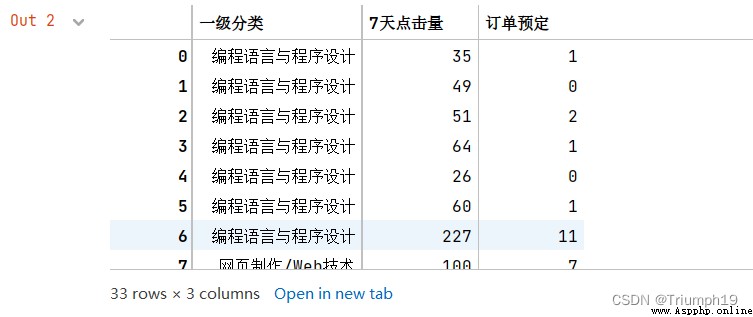
df1=df1.groupby('一級分類').sum() #分組統計求和
df1
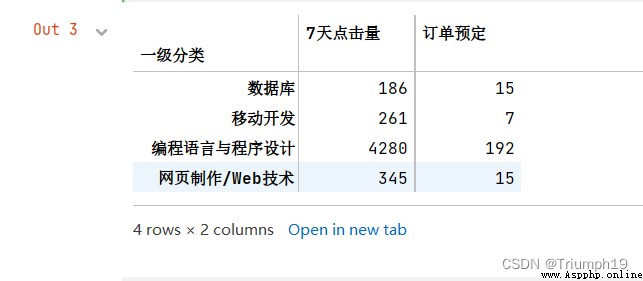
#抽取數據
df1=df[['一級分類','二級分類','7天點擊量','訂單預定']]
df1

df2=df1.groupby(['一級分類','二級分類']).sum() #分組統計求和
df2
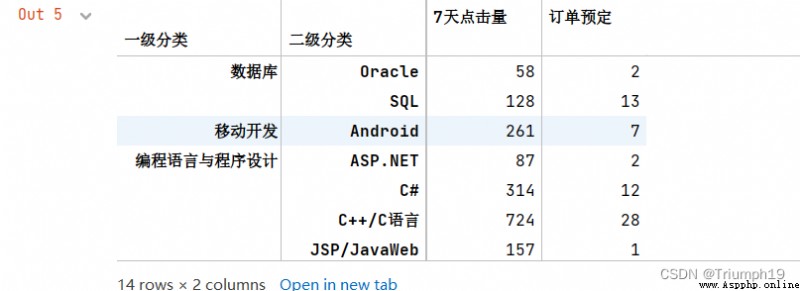
#抽取數據
df1=df[['二級分類','7天點擊量']]
df1
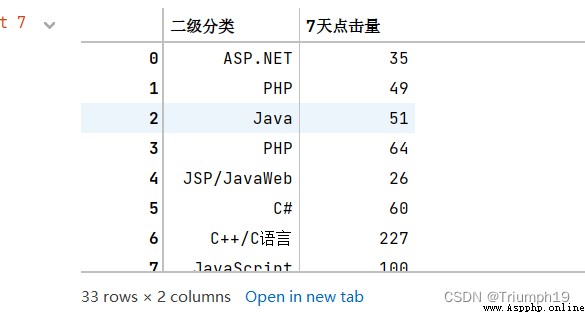
df1=df1.groupby('二級分類')['7天點擊量'].sum()
df1

import pandas as pd #導入pandas模塊
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取數據
df1=df[['一級分類','7天點擊量','訂單預定']]
df1
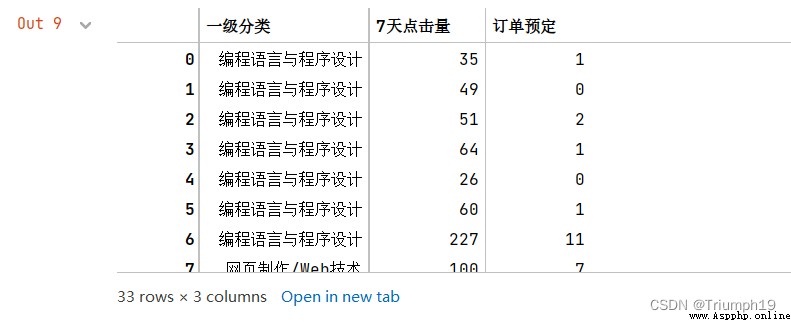
for name, group in df1.groupby('一級分類'):
print(name)
print(group)
數據庫
一級分類 7天點擊量 訂單預定
25 數據庫 58 2
27 數據庫 128 13
移動開發
一級分類 7天點擊量 訂單預定
10 移動開發 85 4
19 移動開發 32 1
24 移動開發 85 2
28 移動開發 59 0
編程語言與程序設計
一級分類 7天點擊量 訂單預定
0 編程語言與程序設計 35 1
1 編程語言與程序設計 49 0
2 編程語言與程序設計 51 2
3 編程語言與程序設計 64 1
4 編程語言與程序設計 26 0
5 編程語言與程序設計 60 1
6 編程語言與程序設計 227 11
8 編程語言與程序設計 122 3
9 編程語言與程序設計 111 5
11 編程語言與程序設計 165 5
12 編程語言與程序設計 131 1
13 編程語言與程序設計 149 10
15 編程語言與程序設計 1139 79
16 編程語言與程序設計 125 1
18 編程語言與程序設計 149 4
20 編程語言與程序設計 52 1
21 編程語言與程序設計 597 25
22 編程語言與程序設計 474 15
23 編程語言與程序設計 83 3
26 編程語言與程序設計 132 8
29 編程語言與程序設計 27 2
30 編程語言與程序設計 239 13
31 編程語言與程序設計 45 1
32 編程語言與程序設計 28 0
網頁制作/Web技術
一級分類 7天點擊量 訂單預定
7 網頁制作/Web技術 100 7
14 網頁制作/Web技術 188 8
17 網頁制作/Web技術 57 0
import pandas as pd #導入pandas模塊
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取數據
df2=df[['一級分類','二級分類','7天點擊量','訂單預定']]
df2
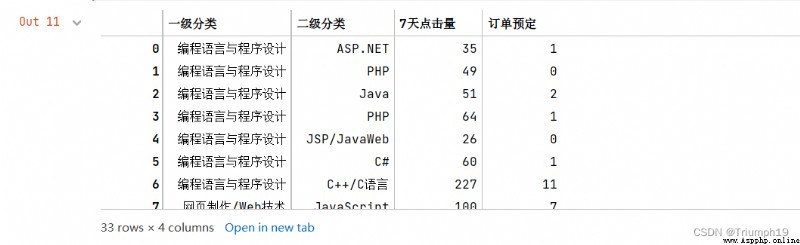
for (key1,key2), group in df2.groupby(['一級分類','二級分類']):
print(key1,key2)
print(group)
數據庫 Oracle
一級分類 二級分類 7天點擊量 訂單預定
25 數據庫 Oracle 58 2
數據庫 SQL
一級分類 二級分類 7天點擊量 訂單預定
27 數據庫 SQL 128 13
移動開發 Android
一級分類 二級分類 7天點擊量 訂單預定
10 移動開發 Android 85 4
19 移動開發 Android 32 1
24 移動開發 Android 85 2
28 移動開發 Android 59 0
編程語言與程序設計 ASP.NET
一級分類 二級分類 7天點擊量 訂單預定
0 編程語言與程序設計 ASP.NET 35 1
20 編程語言與程序設計 ASP.NET 52 1
編程語言與程序設計 C#
一級分類 二級分類 7天點擊量 訂單預定
5 編程語言與程序設計 C# 60 1
8 編程語言與程序設計 C# 122 3
26 編程語言與程序設計 C# 132 8
編程語言與程序設計 C++/C語言
一級分類 二級分類 7天點擊量 訂單預定
6 編程語言與程序設計 C++/C語言 227 11
9 編程語言與程序設計 C++/C語言 111 5
11 編程語言與程序設計 C++/C語言 165 5
18 編程語言與程序設計 C++/C語言 149 4
29 編程語言與程序設計 C++/C語言 27 2
31 編程語言與程序設計 C++/C語言 45 1
編程語言與程序設計 JSP/JavaWeb
一級分類 二級分類 7天點擊量 訂單預定
4 編程語言與程序設計 JSP/JavaWeb 26 0
12 編程語言與程序設計 JSP/JavaWeb 131 1
編程語言與程序設計 Java
一級分類 二級分類 7天點擊量 訂單預定
2 編程語言與程序設計 Java 51 2
13 編程語言與程序設計 Java 149 10
16 編程語言與程序設計 Java 125 1
23 編程語言與程序設計 Java 83 3
編程語言與程序設計 PHP
一級分類 二級分類 7天點擊量 訂單預定
1 編程語言與程序設計 PHP 49 0
3 編程語言與程序設計 PHP 64 1
編程語言與程序設計 Python
一級分類 二級分類 7天點擊量 訂單預定
15 編程語言與程序設計 Python 1139 79
21 編程語言與程序設計 Python 597 25
22 編程語言與程序設計 Python 474 15
30 編程語言與程序設計 Python 239 13
編程語言與程序設計 Visual Basic
一級分類 二級分類 7天點擊量 訂單預定
32 編程語言與程序設計 Visual Basic 28 0
網頁制作/Web技術 HTML
一級分類 二級分類 7天點擊量 訂單預定
14 網頁制作/Web技術 HTML 188 8
網頁制作/Web技術 JavaScript
一級分類 二級分類 7天點擊量 訂單預定
7 網頁制作/Web技術 JavaScript 100 7
網頁制作/Web技術 WEB前端
一級分類 二級分類 7天點擊量 訂單預定
17 網頁制作/Web技術 WEB前端 57 0
import pandas as pd #導入pandas模塊
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取數據
df1=df[['一級分類','7天點擊量','訂單預定']]
df1
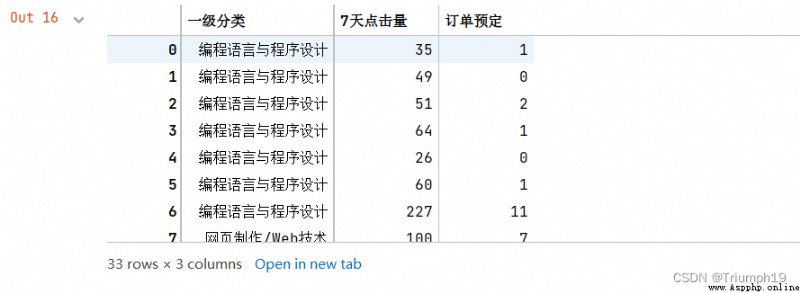
df1.groupby('一級分類').agg(['mean','sum'])
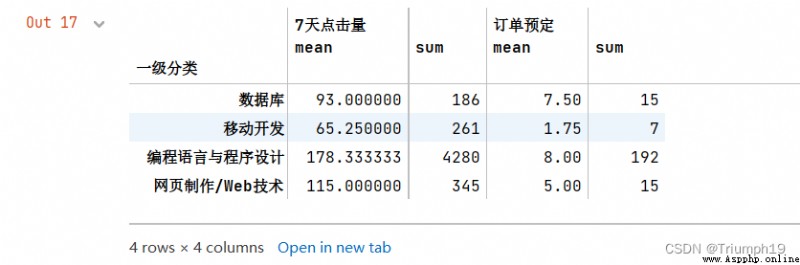
df1.groupby('一級分類').agg({
'7天點擊量':['mean','sum'],'訂單預定':['sum']})
import pandas as pd #導入pandas模塊
df=pd.read_excel('1月.xlsx') #導入Excel文件
df
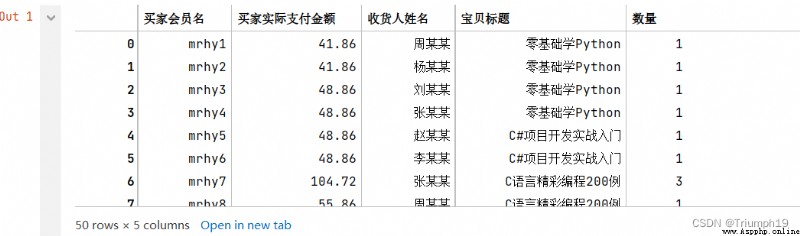
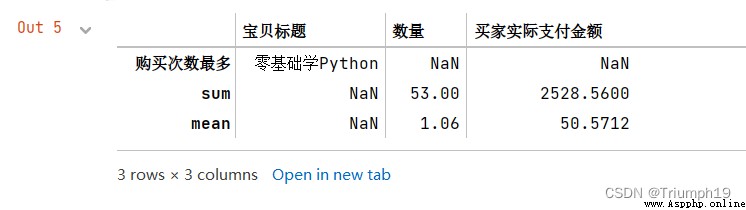
#x是“寶貝標題”對應的列
#value_counts()函數用於Series對象中的每個值進行計數並且排序
max1 = lambda x: x.value_counts(dropna=False).index[0]
max1.__name__ = "購買次數最多"
df1=df.agg({
'寶貝標題': [max1],
'數量': ['sum', 'mean'],
'買家實際支付金額': ['sum', 'mean']})
df1
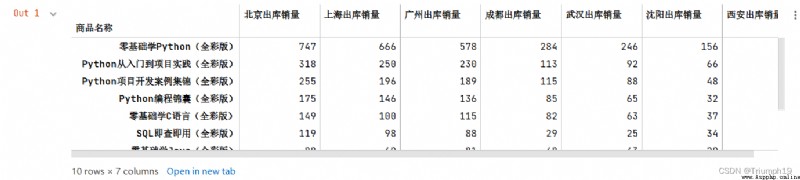
import pandas as pd #導入pandas模塊
#解決數據輸出時列名不對齊的問題
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk') #導入csv文件
df=df.set_index(['商品名稱'])
df
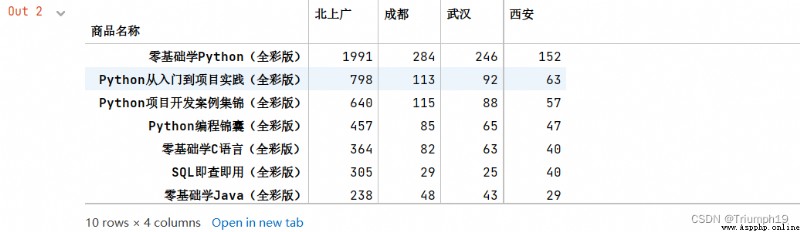
#創建字典
mapping={
'北京出庫銷量':'北上廣','上海出庫銷量':'北上廣',
'廣州出庫銷量':'北上廣','成都出庫銷量':'成都',
'武漢出庫銷量':'武漢','西安出庫銷量':'西安'}
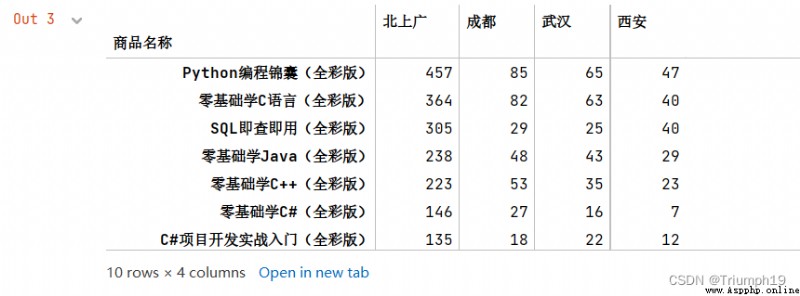
df1=df.groupby(mapping,axis=1).sum()
df1
import pandas as pd #導入pandas模塊
df=pd.read_csv('JD.csv',encoding='gbk') #導入csv文件
df=df.set_index(['商品名稱'])
data={
'北京出庫銷量':'北上廣','上海出庫銷量':'北上廣',
'廣州出庫銷量':'北上廣','成都出庫銷量':'成都',
'武漢出庫銷量':'武漢','西安出庫銷量':'西安',}
s1=pd.Series(data)
s1

df1=df.groupby(s1,axis=1).sum()
df1

DataFrame.shift(periods=1,freq=1,axis=0)
import pandas as pd
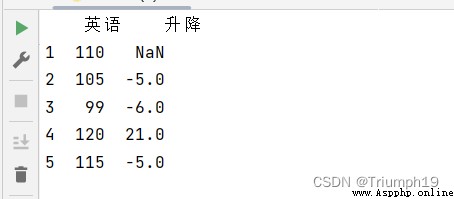
data = [110,105,99,120,115]
index=[1,2,3,4,5]
df = pd.DataFrame(data=data,index=index,columns=['英語'])
df['升降']=df['英語']-df['英語'].shift()
print(df)
import pandas as pd
import matplotlib.pylab as plt
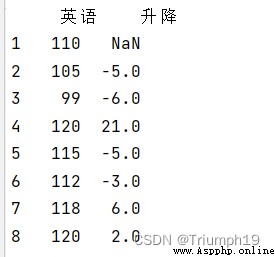
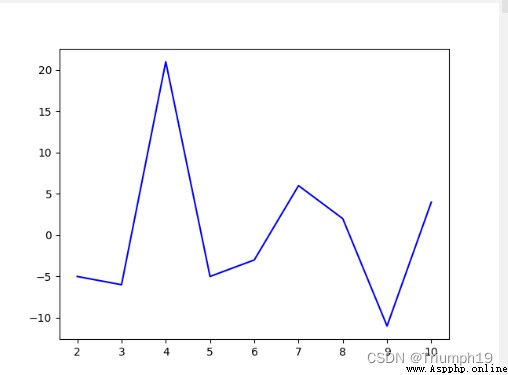
data = [110,105,99,120,115,112,118,120,109,113]
index=[1,2,3,4,5,6,7,8,9,10]
df = pd.DataFrame(data=data,index=index,columns=['英語'])
df['升降']=df['英語']-df['英語'].shift()
print(df)
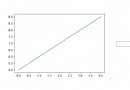
df['升降'].plot(style='b')
plt.show()
Series.str.split(pat=None,n=1,expand=False)

import pandas as pd
#導入Excel文件指定列數據(“買家會員名”和“收貨地址”)
df = pd.read_excel('mrbooks.xls',usecols=['買家會員名','收貨地址'])
df

#使用split方法分割“收貨地址”
series=df['收貨地址'].str.split(' ',expand=True)
df['省']=series[0]
df['市']=series[1]
df['區']=series[2]
df1=df.head()
df1

import pandas as pd
#導入Excel文件部分列數據(“買家會員名”和“寶貝標題”)
df = pd.read_excel('mrbooks.xls',usecols=['買家會員名','寶貝標題'])
df

#使用join方法和split方法分割“寶貝標題”
df = df.join(df['寶貝標題'].str.split(',', expand=True))
df1=df.head()
df1

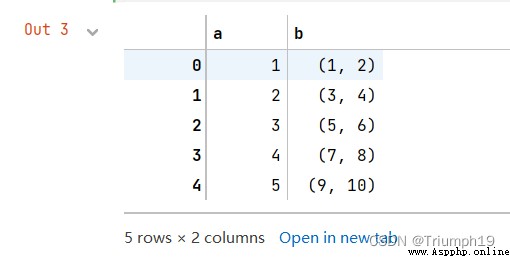
import pandas as pd
df = pd.DataFrame({
'a':[1,2,3,4,5], 'b':[(1,2), (3,4),(5,6),(7,8),(9,10)]})
df
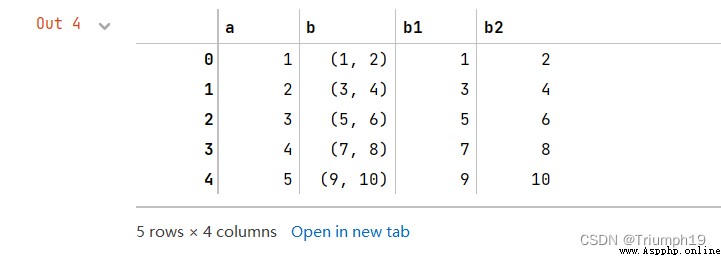
# apply函數分割元組
df[['b1', 'b2']] = df['b'].apply(pd.Series)
df
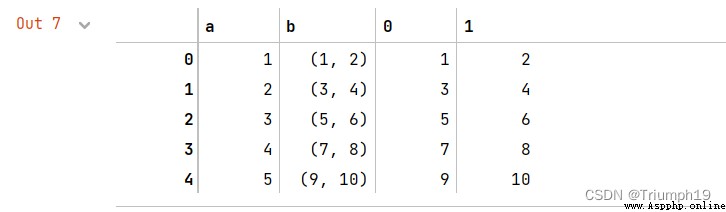
#或者join方法結合apply函數分割元組
df= df.join(df['b'].apply(pd.Series))
df
DataFrame.stack(level=-1,dropna=True)
import pandas as pd
df=pd.read_excel('grade.xls') #導入Excel文件
df
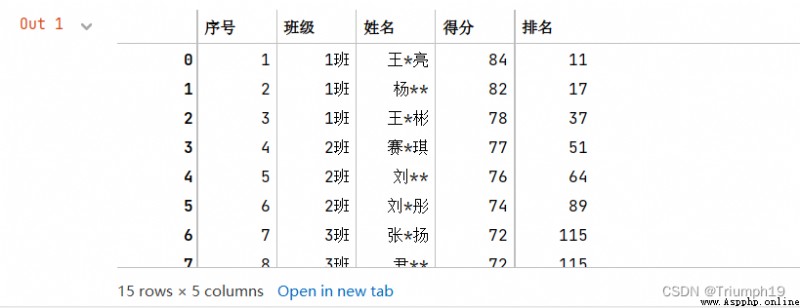
df = df.set_index(['班級','序號']) #設置2級索引“班級”和“序號”
df

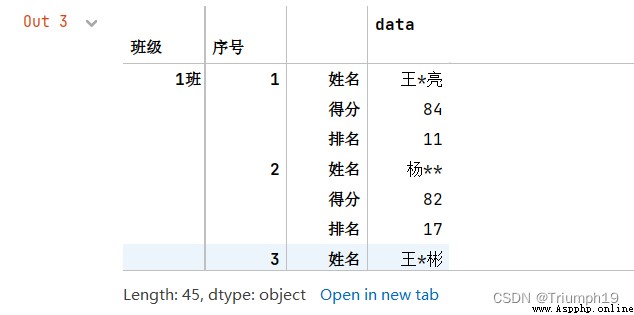
df = df.stack()
df
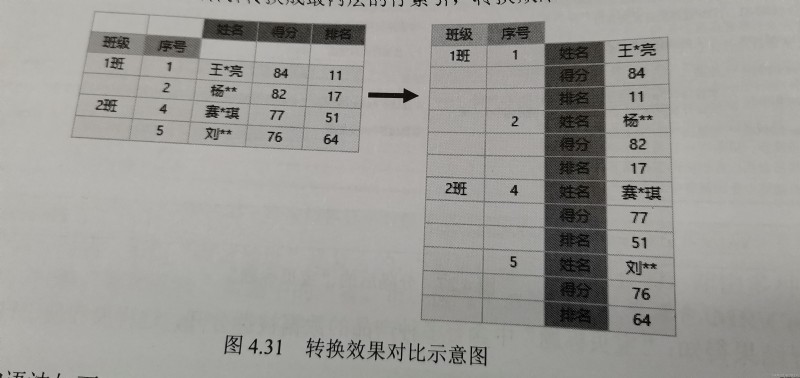
unstack()方法與stack()方法相反,它是stack()方法的逆操作,即將最內層的行索引轉換成列索引,轉換效果對比如圖4.32所示。
unstack()方法的語法如下: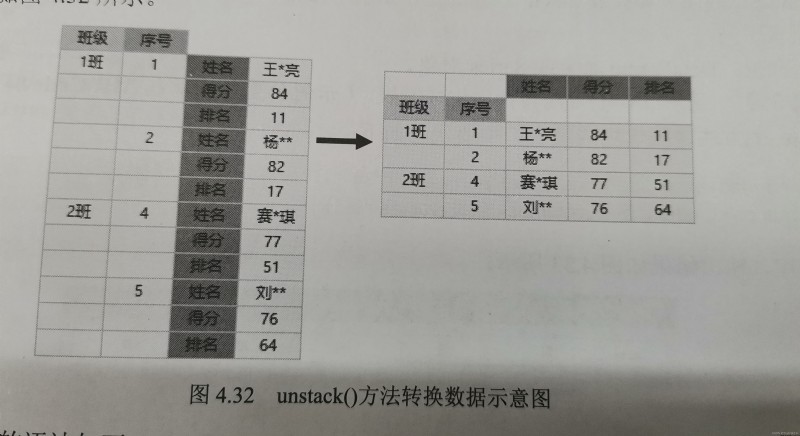
DataFrame.unstack(level=-1,fill_value=None)
import pandas as pd
#設置數據顯示的列數和寬度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解決數據輸出時列名不對齊的問題
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_excel('grade.xls',sheet_name='英語2') #導入Excel文件
df
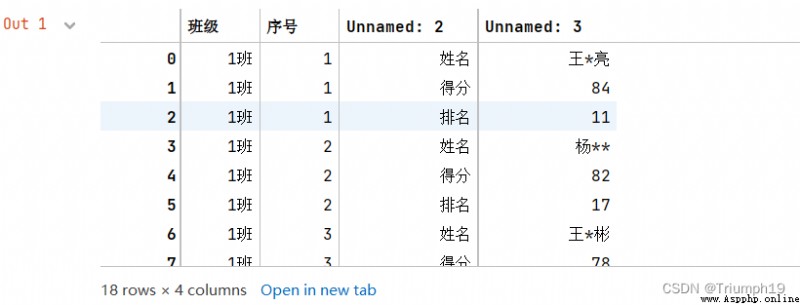
df = df.set_index(['班級','序號','Unnamed: 2']) #設置多級索引
df
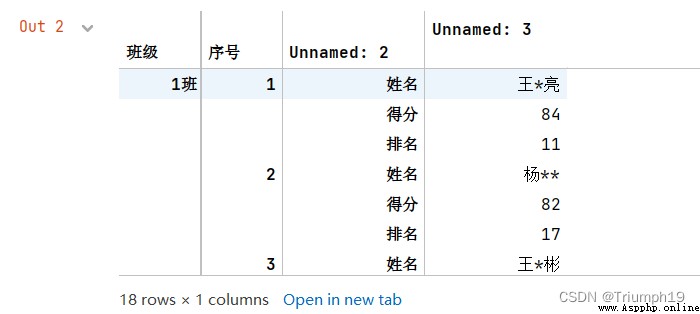
df.unstack()
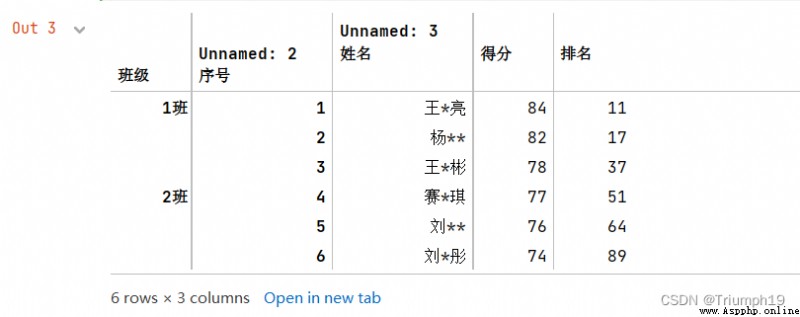
DataFrame.pivot(index=None,columns=None,values=None)
import pandas as pd
df=pd.read_excel('grade.xls',sheet_name='英語3') #導入Excel文件
df
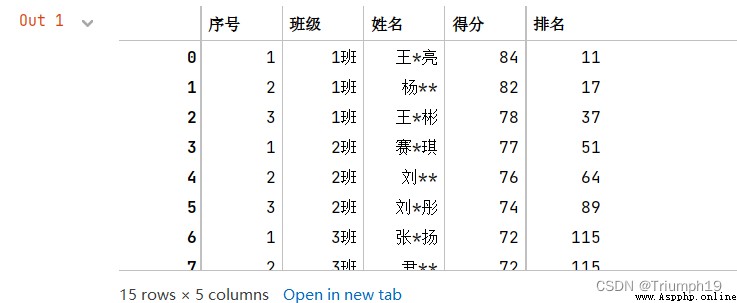
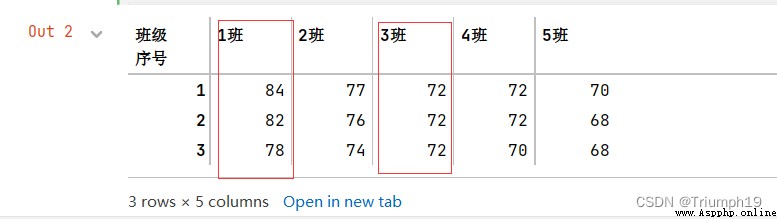
df1=df.pivot(index='序號',columns='班級',values='得分')
df1
import pandas as pd
df = pd.read_excel('mrbooks.xls')
df

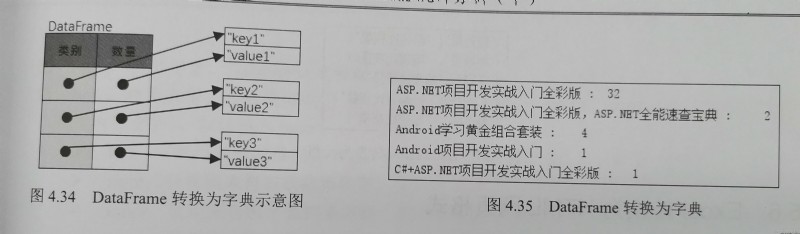
mydict=df1.to_dict()
for i,j in mydict.items():
print(i,':\t', j)

import pandas as pd
df =pd.read_excel('mrbooks.xls')
df
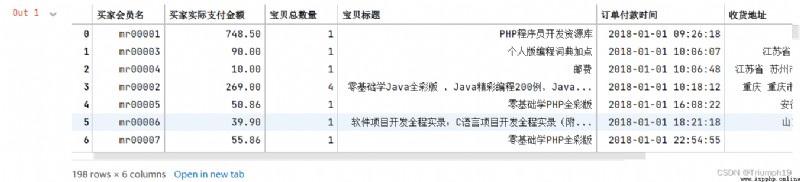
df1=df[['買家會員名']].head()
df1
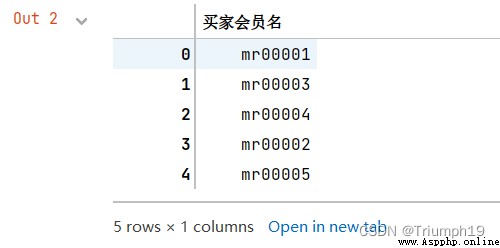
list1=df1['買家會員名'].values.tolist()
for s in list1:
print(s)

import pandas as pd
df = pd.read_excel('fl4.xls')
df
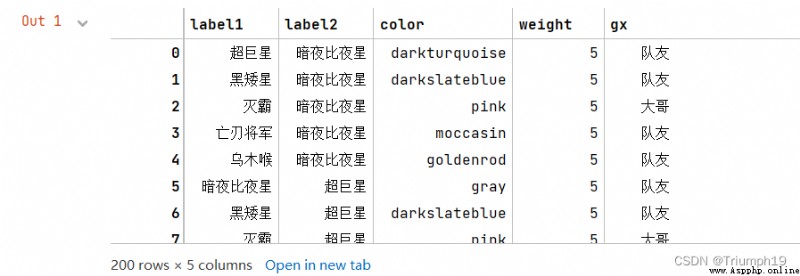
df1=df[['label1','label2']].head()
df1

tuples = [tuple(x) for x in df1.values]
for t in tuples:
print(t)

import pandas as pd
df=pd.read_excel('mrbooks.xls',usecols=['買家會員名','寶貝標題']).head()
df.to_html('mrbooks.html',header = True,index = False,encoding='gbk') #編碼要也可能是utf8
Pandas.merge(right,how='inner',on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=False,suffixes=('_x','_y'),copy=True,indicator=False,validate=None)

import pandas as pd
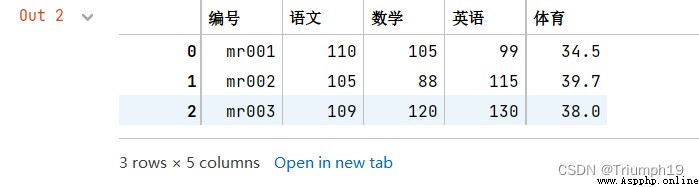
df1 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'語文':[110,105,109],
'數學':[105,88,120],
'英語':[99,115,130]})
df2 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'體育':[34.5,39.7,38]})
df_merge=pd.merge(df1,df2,on='編號')
df_merge
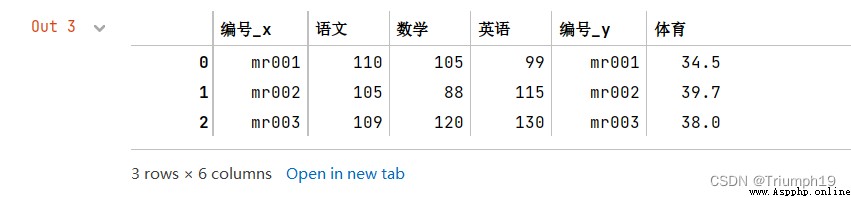
import pandas as pd
df1 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'語文':[110,105,109],
'數學':[105,88,120],
'英語':[99,115,130]})
df2 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'體育':[34.5,39.7,38]})
df_merge=pd.merge(df1,df2,left_index=True,right_index=True)
df_merge
df_merge=pd.merge(df1,df2,on='編號',left_index=True,rith_index=True)
df_merge=pd.merge(df1,df2,on='編號',how='left')
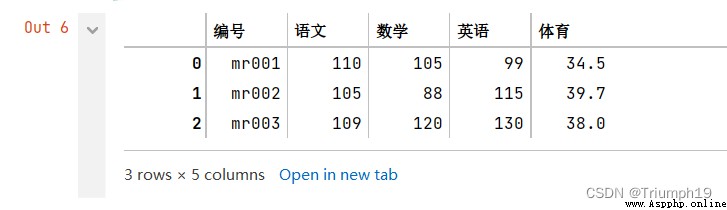
import pandas as pd
df1 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'語文':[110,105,109],
'數學':[105,88,120],
'英語':[99,115,130]})
df2 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'體育':[34.5,39.7,38]})
# df_merge=pd.merge(df1,df2,on='編號',left_index=True,right_index=True)
# df_merge
df_merge=pd.merge(df1,df2,on='編號',how='left')
df_merge
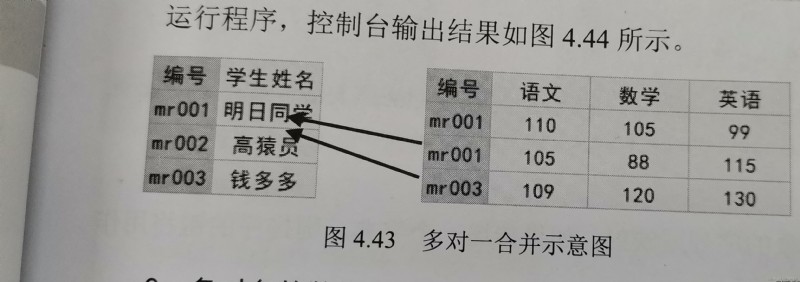
import pandas as pd
df1 = pd.DataFrame({
'編號':['mr001','mr002','mr003'],
'學生姓名':['明日同學','高猿員','錢多多']})
df2 = pd.DataFrame({
'編號':['mr001','mr001','mr003'],
'語文':[110,105,109],
'數學':[105,88,120],
'英語':[99,115,130],
'時間':['1月','2月','1月']})
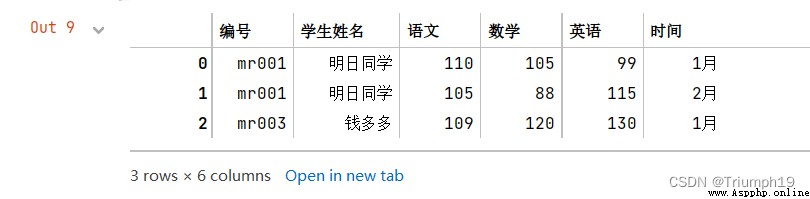
df_merge=pd.merge(df1,df2,on='編號')
df_merge
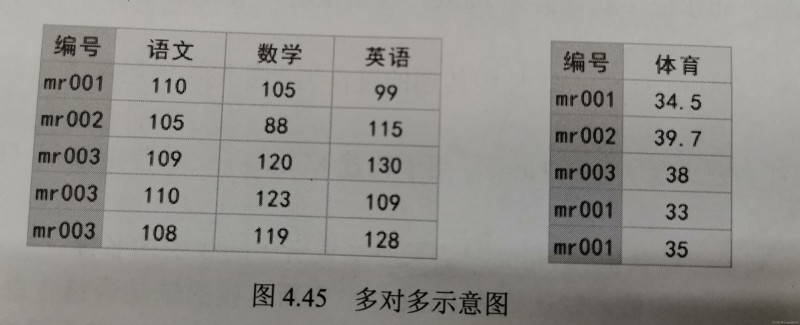
import pandas as pd
df1 = pd.DataFrame({
'編號':['mr001','mr002','mr003','mr001','mr001'],
'體育':[34.5,39.7,38,33,35]})
df2 = pd.DataFrame({
'編號':['mr001','mr002','mr003','mr003','mr003'],
'語文':[110,105,109,110,108],
'數學':[105,88,120,123,119],
'英語':[99,115,130,109,128]})
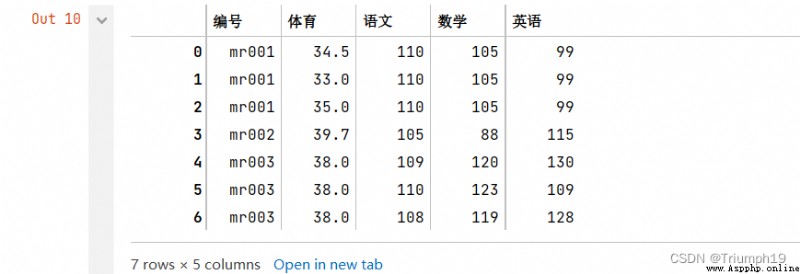
df_merge=pd.merge(df1,df2)
df_merge
pandas.concat(objs,axis=0,join='outer',ignore_index:bool = False,keys=None,levels=None,names=None,verify_integrity:bool=False,sort:bool=False,copy:bool=True)
dfs=[df1,df2,df3]
result=pd.concat(dfs)
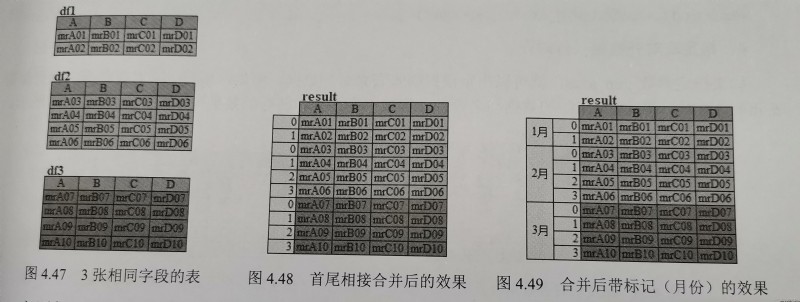
result=pd.concat(dfs,keys=['1月','2月','3月'])

result=pd.concat([df1,df4],axis=1)
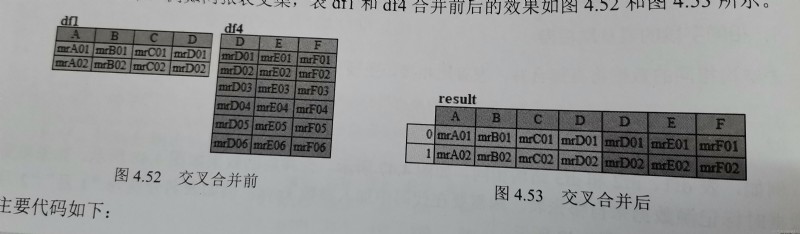
result=pd.concat([df1,df4],axis=1,join="inner")

result=pd.concat([df1,df4],axis=1,join_axes=[df4,index]
DataFrame.to_excel(excel_writer,sheet_name='Sheet1',na_rep='',float_format=None,columns=None,header=True,index=True,index_label=None,startrow=0,startcol=0,engine=None,merge_cells=True,encoding=None,inf_rep='inf',verbose=True,freeze_panes=None)
import pandas as pd
df1 = pd.DataFrame({
'編號':['mr001','mr002','mr003','mr001','mr001'],
'體育':[34.5,39.7,38,33,35]})
df2 = pd.DataFrame({
'編號':['mr001','mr002','mr003','mr003','mr003'],
'語文':[110,105,109,110,108],
'數學':[105,88,120,123,119],
'英語':[99,115,130,109,128]})
df_merge=pd.merge(df1,df2)
df_merge.to_excel('merge.xlsx')
df1.to_excel('df1.xlsx',sheet_name='df1')
DataFrame.to_csv(path_or_buf=None,sep=',',na_rep='',float_format=None,columns=None,header=True,index=True,index_label=None,mode='w',encoding=None,compression='infer',quoting=None,quotechar="",line_terminator=None,chunksize=None,data_format=None,doublequote=True,escapechar=None,decimal='.',errors='strict')
import pandas as pd
data = [['a',110,105,99],['b',105,88,115],['c',109,120,130],['d',112,115]]
index = [1,2,3,4]
columns = ['name','語文','數學','英語']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
#相對位置,保存在程序所在路徑下
df.to_csv('Result1.csv',encoding='gb2312')
#絕對位置
df.to_csv('d:\Result.csv',encoding='gb2312')
#分隔符。使用問號(?)分隔符分隔需要保存的數據
df.to_csv('Result2.csv',sep='?',encoding='gb2312')
#替換空值,缺失值保存為NA
df.to_csv('Result3.csv',na_rep='NA',encoding='gb2312')
#格式化數據,保留兩位小數
df.to_csv('Result4.csv',float_format='%.2f',encoding='gb2312')
#保留某列數據,保存索引列和name列
df.to_csv('Result5.csv',columns=['name'],encoding='gb2312')
#是否保留列名,不保留列名
df.to_csv('Result6.csv',header=0,encoding='gb2312')
#是否保留行索引,不保留行索引
df.to_csv('Result7.csv',index=0,encoding='gb2312')
import pandas as pd
data = [['a',110,105,99],['b',105,88,115],['c',109,120,130],['d',112,115]]
index = [1,2,3,4]
columns = ['A','語文','數學','英語']
df1 = pd.DataFrame(data=data, index=index, columns=columns)
df1.to_excel('df1.xlsx',sheet_name='df1')
work=pd.ExcelWriter('df2.xlsx') #打開一個Excel文件
df1.to_excel(work,sheet_name='df2')
df1['A'].to_excel(work,sheet_name='df3')
work.save()
 Basic composition of Python HTML (3. background layout and page optimization)
Basic composition of Python HTML (3. background layout and page optimization)
One .html Basic summary :html
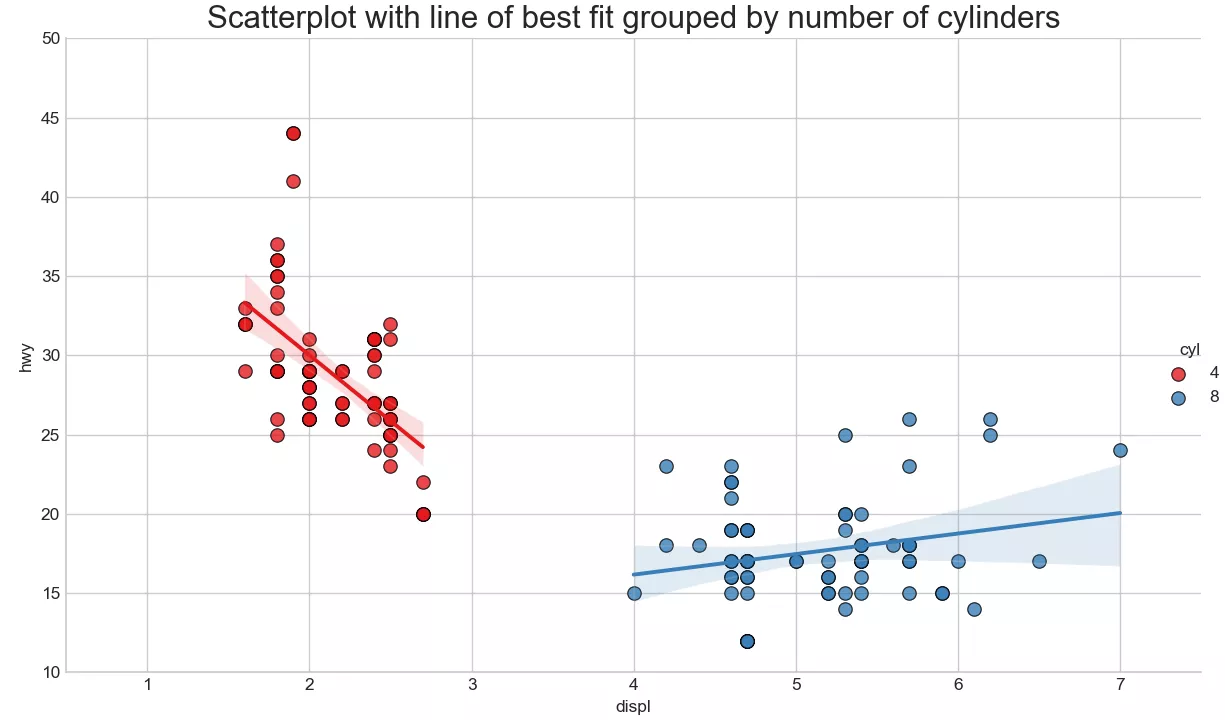 Visual analysis and drawing of scatter chart and edge histogram with trend line in Python
Visual analysis and drawing of scatter chart and edge histogram with trend line in Python
Catalog One 、 Draw a scatter