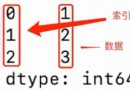
In the data of data mining project , There are two types of data : Ordered continuous values and Disorderly categorical features .
about xgboost、GBDT etc. boosting Tree model , Basic learning is usually cart Back to the tree , and cart Tree input usually only supports continuous numeric types , Like age 、 Continuous variables such as income Cart It can be dealt with very well , But for unordered category variables ( Such as occupation 、 Such area ),cart Tree processing is more troublesome , If you are directly and violently enumerating the combination of each possible category type feature , In this way, the amount of calculation for finding the classification points of category features is easy to explode .
Here it is , This article lists Tree model is a common method for category feature processing , And made an in-depth discussion ~ Like, remember to like 、 Collection 、 Focus on .
Be careful : There are technical exchange methods at the end of the article
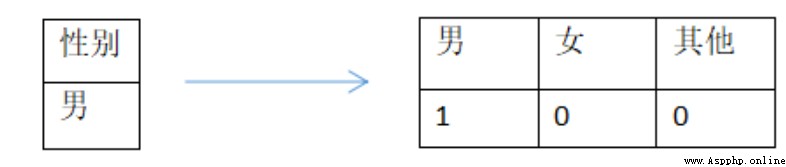 We can make a direct analysis of category features Onehot Handle ( This is also the most common practice ), The value of each category uses a single digit 0/1 To express , That's one “ Gender ” Category characteristics can be converted to whether they are “ male ”、“ Woman ” perhaps “ other ” To express , as follows :
We can make a direct analysis of category features Onehot Handle ( This is also the most common practice ), The value of each category uses a single digit 0/1 To express , That's one “ Gender ” Category characteristics can be converted to whether they are “ male ”、“ Woman ” perhaps “ other ” To express , as follows :
display(df.loc[:,['Gender_Code']].head())
# onehot
pd.get_dummies(df['Gender_Code']).head()
however onehot The major disadvantage of is , For category features with many values , It may lead to high-dimensional sparse features and easy to lead to over fitting of tree model . As mentioned before, in the face of high-dimensional sparse onehot features , Once the division conditions are met , The tree model is easy to deepen , The more you slice , The statistical information of each segmented sub feature space is getting smaller and smaller , All you learn may be noise ( namely Over fitting ).
Use advice :Onehot Naturally suitable for neural network models , Neural networks can easily learn from high-dimensional sparse features to low-dimensional dense representations . When onehot When used for tree model , When the number of category features is small, you can still learn more important interaction features , But when there are many values ( Such as Greater than 100), It is easy to cause over fitting , It's not suitable for onehot+ Tree model .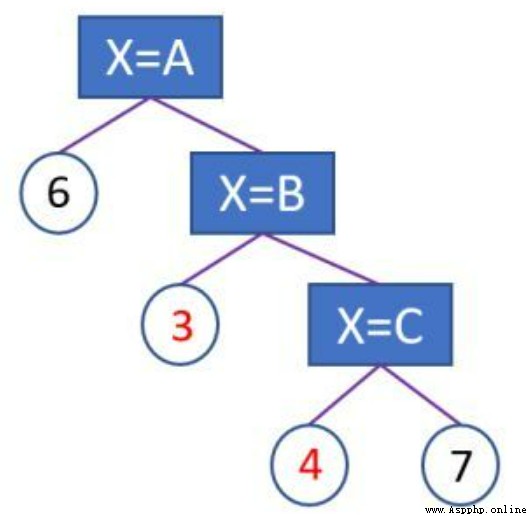 ( notes : Besides onehot There are also disadvantages such as increasing memory overhead and training time overhead )
( notes : Besides onehot There are also disadvantages such as increasing memory overhead and training time overhead )
OrdinalEncoder Also known as sequential coding ( And label encoding, The two functions are basically the same ), features / The label is converted to an ordinal integer (0 To n_categories - 1)
Use advice : Apply to ordinal feature , That is, although the category characteristics , But it has an internal order , For example, the size of clothes “S”,“M”, “L” And other features are suitable for integer coding from small to large .
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df[col] = encoder.transform(df[col])
target encoding Target coding is also called mean coding , It is coded with the help of the label information corresponding to each category feature ( For example, two categories Simply take values based on category characteristics The sample corresponding to the label value “0/1” Average value ), It is a common supervised coding method ( In addition, there are classic WoE code ), It is very suitable for weak models such as logistic regression .
Use advice : When the tree model uses target coding , You need to add some regularization techniques , Reduce Target encoding The phenomenon of conditional deviation caused by method ( When the data structure and distribution of training data set and test data set are different, the problem of conditional offset will occur ), The mainstream approach is to use Catboost code perhaps Use cross-validation Find out target mean or bayesian mean.

# The following simple target mean Code . It can also be used. :from category_encoders import TargetEncoder
target_encode_columns = ['Gender_Code']
target = ['y']
target_encode_df = score_df[target_encode_columns + target].reset_index().drop(columns = 'index', axis = 1)
target_name = target[0]
target_df = pd.DataFrame()
for embed_col in target_encode_columns:
val_map = target_encode_df.groupby(embed_col)[target].mean().to_dict()[target_name]
target_df[embed_col] = target_encode_df[embed_col].map(val_map).values
score_target_drop = score_df.drop(target_encode_columns, axis = 1).reset_index().drop(columns = 'index', axis = 1)
score_target = pd.concat([score_target_drop, target_df], axis = 1)
CatBoostEncoder yes CatBoost How the model handles category variables (Ordered TS code ), It is based on the target coding to reduce the conditional offset . Its calculation formula is :
TargetCount : For the specified category, the characteristics are in target value The sum of
prior: For the entire dataset ,target Summation of values / Number of all observed variables
FeatureCount: The number of occurrences of the observed feature list in the whole dataset .
CBE_encoder = CatBoostEncoder()
train_cbe = CBE_encoder.fit_transform(train[feature_list], target)
test_cbe = CBE_encoder.transform(test[feature_list])
Also known as frequency coding , The values of category features are converted into their frequency in the training set , This is intuitively based on the frequency of category values Divide high frequency category and low frequency category . As for the effect , It is still necessary to combine the business and actual scenarios .
## It can also be direct from category_encoders import CountEncoder
bm = []
tmp_df=train_df
for k in catefeas:
t = pd.DataFrame(tmp_df[k].value_counts(dropna=True,normalize=True)) # frequency
t.columns=[k+'vcount']
bm.append(t)
for k,j in zip(catefeas, range(len(catefeas))):# Join coding
df = df.merge(bm[j], left_on=k, right_index=True,how='left')
When there are many values in a category (onehot High dimensional ), If direct onehot, In terms of performance or effect, it will be relatively poor , At this time, through neural network embedding It's a good way , Change the category variable onehot The input neural network learns a low dimensional dense vector , Such as the classical unsupervised word vector representation learning word2vec perhaps Based on supervised neural network coding .
Use advice : It is especially suitable for category variables with many values ,onehot Post high dimensional sparse , Do it again NN The low dimensional representation is transformed and applied to the tree model .
# word2vec
from gensim.models import word2vec
# Load data
raw_sentences = ["the quick brown fox jumps over the lazy dogs","yoyoyo you go home now to sleep"]
# Segmentation vocabulary
sentences= [s.encode('utf-8').split() for s in sentences]
# Build the model
model = word2vec.Word2Vec(sentences,size=10) # The dimension of the word vector is 10
# The word vector of each word
model['dogs']
# array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
In order to solve one-hot code (one vs many ) Deficiencies in dealing with category characteristics .lgb Adopted Many vs many Segmentation method of , Simply speaking , It is through numerical coding of the value of each category ( Similar to target coding ), Find a better cut point according to the coded value , The better segmentation of category feature set is realized .
1 、 The number of feature values is less than or equal to 4( Parameters max_cat_to_onehot): direct onehot code , Scan each... One by one bin Containers , Find the best split point ;
2、 The number of feature values is greater than 4:max bin The default value of is 256 The number of values is greater than max bin Number of hours , It will screen out the values with less frequency . Then count the sum of one step degrees of samples corresponding to each eigenvalue , The sum of two steps , With the sum of one step / ( The sum of two steps + Regularization coefficient ) As the code of the feature value . After converting the category to numerical code , Sort from large to small , Traverse the histogram to find the best segmentation point
Simply speaking ,Lightgbm Using gradient statistical information to encode category features . My personal understanding is that it can be divided into categories and feature groups according to the difficulty of learning , For example, a feature has a total of 【 The Wolf 、 Dog 、 cat 、 The pig 、 rabbit 】 Values of five categories , and 【 The Wolf 、 Dog 】 The difficulty of sample classification under type is quite high ( The gradient under this characteristic value is large ), On the category features after gradient coding , Looking for a better division point may be 【 The Wolf 、 Dog 】|vs|【 cat 、 The pig 、 rabbit 】
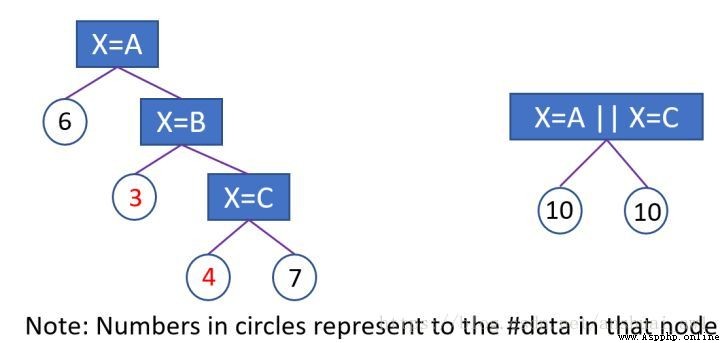
Use advice : Usually use lgb Class feature processing , The effect is better than one-hot encoding, And it's easy to use .
# lgb Category processing : Simply convert to category type features and input directly Lgb Model training is enough .
for ft in category_list:
train_x[ft] = train_x[ft].astype('category')
clf = LGBMClassifier(**best_params)
clf.fit(train_x, train_y)
The number of values is very small (<10) Categorical characteristics of , The corresponding number of samples under each value is also relatively large , Can directly Onehot code .
There are many values (10 To hundreds ), At this time onehot In terms of efficiency or effect , Not even lightgbm Gradient coding or catboost Target code , And direct use is also very convenient .( It should be noted that , In personal practice, these two methods have different characteristics in many categories , It's still easier to fit . At this time , First merge the category values or try to eliminate some category features , The effect of the model will be better )
When hundreds or thousands of categories take values , You can start with onehot after ( High dimensional sparsity ), Low dimensional dense representation with the help of neural network model .
The above is the main tree model coding method for category features . The effect of the actual project , Specific verification is required . When computing resources are abundant , You can try several coding methods , Then make feature selection , Select more effective features , The bar effect !!
At present, a technical exchange group has been opened , Group friends have exceeded 3000 people , The best way to add notes is : source + Interest direction , Easy to find like-minded friends , Data acquisition can also be added
The way 1、 Add microsignals :dkl88191, remarks : come from CSDN
The way 2、 WeChat search official account :Python Learning and data mining , The background to reply : Add group