Excel
1、將表格變為超級表
實現方法:Ctrl+T 功能:當有新的數據時,數據圖形得到及時更新
2、創建透視表
Alt + D +P
3、動態圖表
https://jingyan.baidu.com/article/5225f26bb4e00ee6fb090811.html
4、index函數
語法:index(reference,row_now,column_num,area_num) 參數: reference:必需,對一個或多個單元格的引用。 row_num:引用中某行的行號,函數從該行返回一個引用。 column_num:可選,引用中某列的列標,,函數從該列返回一個引用。 area_num:可選,選擇一個引用區域,從該區域中返回row_num和column_num的交集 5、 “相差天數”後面輸入:=DATEDIF(C5,C6,"D"), 注意:其中,C5為開始日期,C6為結束日期,D則為計算日差。
數據庫
1、可以向數據庫表中,指定的列添加數據
insert into sku_data (sku,cw_type) values (%s,%s)
Python
1、利用python 對分組排序:
按照旺旺號,訂單號,金額進行分組,並按付款時間進行排序
data1['ranks'] = data.groupby(['旺旺號','訂單號','商品金額']['付款時間'].rank().astype(int)

2、利用Python構建雙層索引,並將雙層變成一層。
data2 = pd.pivot_table(data1,values = ['商品金額'],index = ['旺旺號','付款時間'],columns =['ranks'])data2.columns.tolist()
#對列名重命名
data2.columns =[str(s1) +"第"+str(s2)+"次" for (s1,s2) in data2.columns.tolist()]data2.reset_index(inplace =True) #重置索引,然後拉平索引

3、分布密度圖,可視化制圖方法:sns.distplot()
輔助線制圖方法:plt.axvline()
4、 將占比轉為把百分比的形式
bk_std_fsl['訂單占比'] = bk_std_fsl['訂單數'].apply(lambda x: '%.2f%%' % (x / bk_std_fsl['訂單數'].sum() * 100))
5、去掉缺失值
data.dropna(inplace = True) # 去掉缺失值
6、python pandas去掉重復項
刪除所有重復項:df.drop_duplicates(inplace = True)
Remember: (inplace = True)將確保該方法不會返回一個新的DataFrame,但是它將從原始DataFrame中刪除所有重復。
7、將多種類型數據進行替換
例如將DataFrame中的空值,某些字符串等全都替換成0 replace([na.nan,'無數據','無數'],0,inplace = True)
8、轉置
data.T
9、numpy.concatenate()方法
numpy提供了numpy.concatenate((a1,a2,a3,……),axis =0),能夠一次完成多個數組的拼接,其中a1,a2,a3是數組類型的參數。
a = np.array([2,3,4])b = np.array([11,22,22])c = np.array([55,88,99])np.concatenate((a,b,c),axis =0) #默認情況下,axis=0可以不寫 array([ 2, 3, 4,11, 22, 22, 55, 88,99]) #對於一維數組拼接,axis的值不影響最後的結果。
例如:
angle= np.linspace(0,2*np.pi,4,endpoint=False) # 設置每個數據點的顯示位置angle = np.concatenate((angle,[angle[0]]))
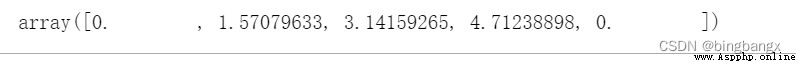
10、pd.cut()參數
pd.cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False,duplicates='raise')
- x : 一維數組
- bins :整數,標量序列或者間隔索引,是進行分組的依據,
如果填入整數n,則表示將x中的數值分成等寬的n份(即每一組內的最大值與最小值之差約相等); 如果是標量序列,序列中的數值表示用來分檔的分界值 如果是間隔索引,“ bins”的間隔索引必須不重疊
- right :布爾值,默認為True表示包含最右側的數值
當“ right = True”(默認值)時,則“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4] 當bins是一個間隔索引時,該參數被忽略。
- labels : 數組或布爾值,可選.指定分箱的標簽
如果是數組,長度要與分箱個數一致,比如“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3個區間,則labels的長度也就是標簽的個數也要是3 如果為False,則僅返回分箱的整數指示符,即x中的數據在第幾個箱子裡 當bins是間隔索引時,將忽略此參數
- retbins: 是否顯示分箱的分界值。默認為False,當bins取整數時可以設置retbins=True以顯示分界值,得到劃分後的區間
- precision:整數,默認3,存儲和顯示分箱標簽的精度。
- include_lowest:布爾值,表示區間的左邊是開還是閉,默認為false,也就是不包含區間左邊。
- duplicates:如果分箱臨界值不唯一,則引發ValueError或丟棄非唯一
11、matplotlib.pyplot.axvline()
參數:x:數據坐標中的x位置以放置垂直線
ymin:y軸上的垂直線起始位置,它將取0到1之間的值,0是軸的底部,1是軸的頂部
ymax:y軸上的垂直線結束位置,它將取0到1之間的值,0是軸的底部,1是軸的頂部
**kwargs:其他可選參數可更改線的屬性,例如改變顏色,線寬等
12、設置網格線
以下實例添加一個簡單的網格線,並設置網格線的樣式,格式如下:grid(color ='color', linestyle ='linestyle', linewidth = number)
參數說明: color:'b' 藍色,'m' 洋紅色,'g' 綠色,'y' 黃色,'r' 紅色,'k' 黑色,'w' 白色,'c' 青綠色,'#008000' RGB 顏色符串。
linestyle:'' 實線,'' 破折線,'.' 點劃線,':' 虛線。
linewidth:設置線的寬度,可以設置一個數字。
13、matplotlib面積堆疊圖
data.plot.area(colormap='',figsize =(x,y)) colormap表示要用的顏色塊
14、matplotlib 雷達圖
- 繪制雷達圖,需要先建立極坐標;
- 建好極坐標以後,可以在極坐標系中繪制柱狀圖,折線圖等,大部分情況都是用折線圖,形成一個不規則的閉合多邊形。
繪制多個點,並且第一個點與最後一個點相同,使其成為閉合圖形。 plt.polar(弧度,半徑,"ro",lw) #使用的是弧度制,使用弧度來表示度數;ro中r表示紅色,o表示形狀;lw表示點的大小 例如: 360度,表示2Π(2*np.pi);180度表示Π(np.pi) plt.polar(0.25*np.pi,20,)