After installation pip Can be installed
Code practice :
import pdfplumber# introduction pdfplumber library
#print(pdfplumber.__version__)# It has been proved by tests that pdfplumber Library installed successfully
pdf=pdfplumber.open('F:\\XX Notice .PDF')# open pdf file , Symbols between paths are \\
pages=pdf.pages# adopt pages Property to get information about all pages , here pages It's a list
text_all=[]# Create an empty list
for page in pages:# Traverse the data of all pages
text = page.extract_text() # use extract_text Function to get the text content of the current page
text_all.append(text)# Add the traversal data to text_all In the list
text_all=''.join(text_all)# hold text_all The list of is converted into a string
print(text_all)# Print all text
pdf.close()# close Pdf file
Running results :

import pdfplumber
pdf=pdfplumber.open('F:\\05pycharm\\20220227 Study \\ Jiawei Xinneng : Jiawei new energy Co., Ltd. signed by the actual controller of the company 《 Bail out investment agreement 》《 Voting power entrustment agreement 》 And the suggestive announcement of the proposed change of control .PDF')# open PDF file
pages=pdf.pages#pages Property to get all page contents
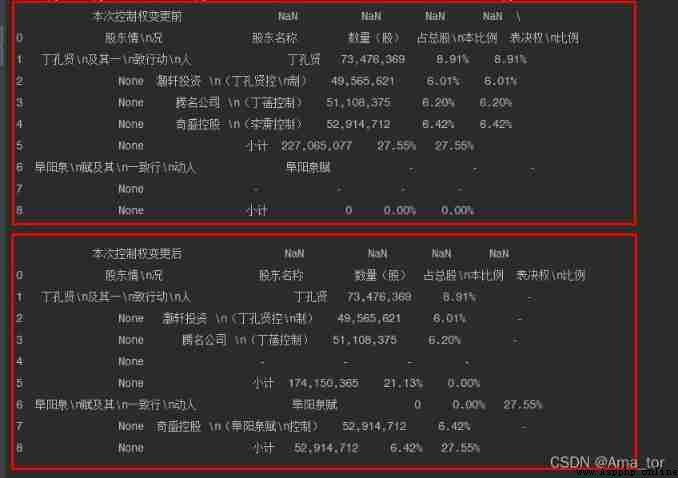
page=pages[2]# Extract the third page , Because the form is on page three
tables=page.extract_tables()#extract_tables() Function to extract all tables on the page
table=tables[0]# Take the first table
print(table)Running results : Format of test list displayed , Further beautification is needed

Through sorting and analysis : Yes 1 Large list , It's nested 10 A small list

import pdfplumber
import pandas as pd
pdf=pdfplumber.open('F:\\05pycharm\\20220227 Study \\ Jiawei Xinneng : Jiawei new energy Co., Ltd. signed by the actual controller of the company 《 Bail out investment agreement 》《 Voting power entrustment agreement 》 And the suggestive announcement of the proposed change of control .PDF')# open PDF file
pages=pdf.pages#pages Property to get all page contents
page=pages[2]# Extract the third page , Because the form is on page three
tables=page.extract_tables()#extract_tables() Function to extract all tables on the page
table=tables[0]# Take the first table
pd.set_option('display.max_columns',None)# Show all the contents of the table , The default display section
df=pd.DataFrame(table[1:],columns=table[0])#table[1:] Is the second row of the table and the following ,table[0] Is the first row of the table , And the contents of the header
print(df)
Running results :