阿裡師兄精心整理的 Python 相關的基礎知識,用於面試,或者平時復習,都是很好的!廢話不多說,直接開搞
由於文章過長,小編也貼心的把文章整理成了PDF文檔,想要觀看學習起來更方便的話在文末查看獲取方式~
Python 語言簡單易懂,上手容易,隨著 AI 風潮,越來越火
編譯型語言:把做好的源程序全部編譯成二進制的可運行程序。然後,可直接運行這個程序。如:C,C++ 解釋型語言:把做好的源程序翻譯一句,然後執行一句,直至結束!如:Python, (Java 有些特殊,java程序也需要編譯,但是沒有直接編譯稱為機器語言,而是編譯稱為字節碼,然後用解釋方式執行字節碼。)
字符串(str):字符串是用引號括起來的任意文本,是編程語言中最常用的數據類型。列表(list):列表是有序的集合,可以向其中添加或刪除元素。元組(tuple):元組也是有序集合,但是是無法修改的。即元組是不可變的。字典(dict):字典是無序的集合,是由 key-value 組成的。集合(set):是一組 key 的集合,每個元素都是唯一,不重復且無序的。
字符串:
output luobodazahui-good
mystr5 = 'luobo,dazahui good'
# 以空格分割
print(mystr5.split())
# 以h分割
print(mystr5.split('h'))
# 以逗號分割
print(mystr5.split(','))
output
['luobo,dazahui', 'good']
['luobo,daza', 'ui good']
['luobo', 'dazahui good']
列表:
mylist1 = [1, 2]
mylist2 = [3, 4]
mylist3 = [1, 2]
mylist1.append(mylist2)
print(mylist1)
mylist3.extend(mylist2)
print(mylist3)
outout
[1, 2, [3, 4]]
[1, 2, 3, 4]
mylist4 = ['a', 'b', 'c', 'd']
del mylist4[0]
print(mylist4)
mylist4.pop()
print(mylist4)
mylist4.remove('c')
print(mylist4)
output
['b', 'c', 'd']
['b', 'c']
['b']
mylist5 = [1, 5, 2, 3, 4]
mylist5.sort()
print(mylist5)
mylist5.reverse()
print(mylist5)
output
[1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
字典:
dict1 = {'key1':1, 'key2':2}
dict1.clear()
print(dict1)
output
{}
dict1 = {'key1':1, 'key2':2}
d1 = dict1.pop('key1')
print(d1)
print(dict1)
output
1
{'key2': 2}
dict2 = {'key1':1, 'key2':2}
mykey = [key for key in dict2]
print(mykey)
myvalue = [value for value in dict2.values()]
print(myvalue)
key_value = [(k, v) for k, v in dict2.items() ]
print(key_value)
output
['key1', 'key2']
[1, 2]
[('key1', 1), ('key2', 2)]
keys = ['zhangfei', 'guanyu', 'liubei', 'zhaoyun']
dict.fromkeys(keys, 0)
output
{'zhangfei': 0, 'guanyu': 0, 'liubei': 0, 'zhaoyun': 0}
計算機在最初的設計中,采用了8個比特(bit)作為一個字節(byte)的方式。一個字節能表示的最大的整數就是255(二進制11111111=十進制255),如果要表示更大的整數,就必須用更多的字節。最早,計算機只有 ASCII 編碼,即只包含大小寫英文字母、數字和一些符號,這些對於其他語言,如中文,日文顯然是不夠用的。後來又發明了Unicode,Unicode把所有語言都統一到一套編碼裡,這樣就不會再有亂碼問題了。當需要保存到硬盤或者需要傳輸的時候,就轉換為UTF-8編碼。UTF-8 是隸屬於 Unicode 的可變長的編碼方式。在 Python 中,以 Unicode 方式編碼的字符串,可以使用 encode() 方法來編碼成指定的 bytes,也可以通過 decode() 方法來把 bytes 編碼成字符串。encode
"中文".encode('utf-8')
output
b'\xe4\xb8\xad\xe6\x96\x87'
decode
b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
output
'中文'
1a = 1
2b = 2
3a, b = b, a
4print(a, b)
output
12 1
先來看個例子
c = d = [1,2]
e = [1,2]
print(c is d)
print(c == d)
print(c is e)
print(c == e)
output
True
True
False
True
== 是比較操作符,只是判斷對象的值(value)是否一致,而 is 則判斷的是對象之間的身份(內存地址)是否一致。對象的身份,可以通過 id() 方法來查看
id(c)
id(d)
id(e)
output
88748080
88748080
88558288
可以看出,只有 id 一致時,is 比較才會返回 True,而當 value 一致時,== 比較就會返回 True
位置參數,默認參數,可變參數,關鍵字參數
*arg和**kwarg作用允許我們在調用函數的時候傳入多個實參
def test(*arg, **kwarg):
if arg:
print("arg:", arg)
if kwarg:
print("kearg:", kwarg)
test('ni', 'hao', key='world')
output
arg: ('ni', 'hao')
kearg: {'key': 'world'}
可以看出,*arg 會把位置參數轉化為 tuple**kwarg 會把關鍵字參數轉化為 dict
sum(range(1, 101))
import time
import datetime
print(datetime.datetime.now())
print(time.strftime('%Y-%m-%d %H:%M:%S'))
output
2019-06-07 18:12:11.165330
2019-06-07 18:12:11
簡單列舉10條:盡量以免單獨使用小寫字母'l',大寫字母'O',以及大寫字母'I'等容易混淆的字母。函數命名使用全部小寫的方式,可以使用下劃線。常量命名使用全部大寫的方式,可以使用下劃線。使用 has 或 is 前綴命名布爾元素,如: is_connect = True; has_member = False 不要在行尾加分號, 也不要用分號將兩條命令放在同一行。不要使用反斜槓連接行。頂級定義之間空2行, 方法定義之間空1行,頂級定義之間空兩行。如果一個類不繼承自其它類, 就顯式的從object繼承。內部使用的類、方法或變量前,需加前綴_表明此為內部使用的。要用斷言來實現靜態類型檢測。
淺拷貝
import copy
list1 = [1, 2, 3, [1, 2]]
list2 = copy.copy(list1)
list2.append('a')
list2[3].append('a')
print(list1, list2)
output
[1, 2, 3, [1, 2, 'a']] [1, 2, 3, [1, 2, 'a'], 'a']
能夠看出,淺拷貝只成功”獨立“拷貝了列表的外層,而列表的內層列表,還是共享的
深拷貝
import copy
list1 = [1, 2, 3, [1, 2]]
list3 = copy.deepcopy(list1)
list3.append('a')
list3[3].append('a')
print(list1, list3)
output
[1, 2, 3, [1, 2]] [1, 2, 3, [1, 2, 'a'], 'a']
深拷貝使得兩個列表完全獨立開來,每一個列表的操作,都不會影響到另一個
def num():
return [lambda x:i*x for i in range(4)]
print([m(1) for m in num()])
output
[3, 3, 3, 3]
通過運行結果,可以看出 i 的取值為3,很神奇
可變數據類型:list、dict、set
不可變數據類型:int/float、str、tuple
for i in range(1, 10):
for j in range(1, i+1):
print("%s*%s=%s " %(i, j, i*j), end="")
print()
output
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
print 函數,默認是會換行的,其有一個默認參數 end,如果像例子中,我們把 end 參數顯示的置為"",那麼 print 函數執行完後,就不會換行了,這樣就達到了九九乘法表的效果了
filter 函數用於過濾序列,它接收一個函數和一個序列,把函數作用在序列的每個元素上,然後根據返回值是True還是False決定保留還是丟棄該元素
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list(filter(lambda x: x%2 == 1, mylist))
output
[1, 3, 5, 7, 9]
保留奇數列表
map 函數傳入一個函數和一個序列,並把函數作用到序列的每個元素上,返回一個可迭代對象
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list(map(lambda x: x*2, mylist))
output
[2, 4, 6, 8, 10, 12, 14, 16, 18]
reduce 函數用於遞歸計算,同樣需要傳入一個函數和一個序列,並把函數和序列元素的計算結果與下一個元素進行計算
from functools import reduce
reduce(lambda x, y: x+y, range(101))
output
5050
可以看出,上面的三個函數與匿名函數相結合使用,可以寫出強大簡潔的代碼
match()函數只檢測要匹配的字符是不是在 string 的開始位置匹配,search()會掃描整個 string 查找匹配
__new__和__init__區別__new__是在實例創建之前被調用的,因為它的任務就是創建實例然後返回該實例對象,是個靜態方法。__init__是當實例對象創建完成後被調用的,然後設置對象屬性的一些初始值,通常用在初始化一個類實例的時候,是一個實例方法
1、__new__至少要有一個參數 cls,代表當前類,此參數在實例化時由 Python 解釋器自動識別。2、__new__必須要有返回值,返回實例化出來的實例,這點在自己實現__new__時要特別注意,可以 return 父類(通過 super(當前類名, cls))__new__出來的實例,或者直接是 object 的__new__出來的實例。3、__init__有一個參數 self,就是這個__new__返回的實例,__init__在__new__的基礎上可以完成一些其它初始化的動作,__init__不需要返回值。4、如果__new__創建的是當前類的實例,會自動調用__init__函數,通過 return 語句裡面調用的__new__函數的第一個參數是 cls 來保證是當前類實例,如果是其他類的類名,;那麼實際創建返回的就是其他類的實例,其實就不會調用當前類的__init__函數,也不會調用其他類的__init__函數
a, b = 1, 2
# 若果 a>b 成立 就輸出 a-b 否則 a+b
h = a-b if a>b else a+b
output
3
print(random.random())
print(random.randint(1, 100))
print(random.uniform(1,5))
output
0.03765019937131564
18
1.8458555362279228
zip() 函數將可迭代的對象作為參數,將對象中對應的元素打包成一個個元組,然後返回由這些元組組成的列表
list1 = ['zhangfei', 'guanyu', 'liubei', 'zhaoyun']
list2 = [0, 3, 2, 4]
list(zip(list1, list2))
output
[('zhangfei', 0), ('guanyu', 3), ('liubei', 2), ('zhaoyun', 4)]
range([start,] stop[, step]),根據start與stop指定的范圍以及step設定的步長,生成一個序列。而 xrange 生成一個生成器,可以很大的節約內存
開文件在進行讀寫的時候可能會出現一些異常狀況,如果按照常規的 f.open 寫法,我們需要 try,except,finally,做異常判斷,並且文件最終不管遇到什麼情況,都要執行 finally f.close() 關閉文件,with 方法幫我們實現了 finally 中 f.close
Python 中默認是貪婪匹配模式
貪婪模式:正則表達式一般趨向於最大長度匹配
非貪婪模式:在整個表達式匹配成功的前提下,盡可能少的匹配
例如:
def test(L=[]):
L.append('test')
print(L)
output
test() # ['test']
test() # ['test', 'test']
默認參數是一個列表,是可變對象[],Python 在函數定義的時候,默認參數 L 的值就被計算出來了,是[],每次調用函數,如果 L 的值變了,那麼下次調用時,默認參數的值就已經不再是[]了
mystr = '1,2,3'
mystr.split(',')
output
['1', '2', '3']
mylist = ['1', '2', '3']
list(map(lambda x: int(x), mylist))
output
[1, 2, 3]
mylist = [1, 2, 3, 4, 5, 5]
list(set(mylist))
from collections import Counter
mystr = 'sdfsfsfsdfsd,were,hrhrgege.sdfwe!sfsdfs'
Counter(mystr)
output
Counter({'s': 9,
'd': 5,
'f': 7,
',': 2,
'w': 2,
'e': 5,
'r': 3,
'h': 2,
'g': 2,
'.': 1,
'!': 1})
[x for x in range(10) if x%2 == 1]
output
[1, 3, 5, 7, 9]
list1 = [[1,2],[3,4],[5,6]]
[j for i in list1 for j in i]
output
[1, 2, 3, 4, 5, 6]
二分查找算法也稱折半查找,基本思想就是折半,對比大小後再折半查找,必須是有序序列才可以使用二分查找
遞歸算法
def binary_search(data, item):
# 遞歸
n = len(data)
if n > 0:
mid = n // 2
if data[mid] == item:
return True
elif data[mid] > item:
return binary_search(data[:mid], item)
else:
return binary_search(data[mid+1:], item)
return False
list1 = [1,4,5,66,78,99,100,101,233,250,444,890]
binary_search(list1, 999)
非遞歸算法
def binary_search(data, item):
# 非遞歸
n = len(data)
first = 0
last = n - 1
while first <= last:
mid = (first + last)//2
if data[mid] == item:
return True
elif data[mid] > item:
last = mid - 1
else:
first = mid + 1
return False
list1 = [1,4,5,66,78,99,100,101,233,250,444,890]
binary_search(list1, 99)
字典轉 json
import json
dict1 = {'zhangfei':1, "liubei":2, "guanyu": 4, "zhaoyun":3}
myjson = json.dumps(dict1)
myjson
output
'{"zhangfei": 1, "liubei": 2, "guanyu": 4, "zhaoyun": 3}'
json 轉字典
mydict = json.loads(myjson)
mydict
output
{'zhangfei': 1, 'liubei': 2, 'guanyu': 4, 'zhaoyun': 3}
import random
td_list=[i for i in range(10)]
print("列表推導式", td_list, type(td_list))
ge_list = (i for i in range(10))
print("生成器", ge_list)
dic = {k:random.randint(4, 9)for k in ["a", "b", "c", "d"]}
print("字典推導式",dic,type(dic))
output
列表推導式 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] <class 'list'>
生成器 <generator object <genexpr> at 0x0139F070>
字典推導式 {'a': 6, 'b': 5, 'c': 8, 'd': 9} <class 'dict'>
read 讀取整個文件
readline 讀取下一行,使用生成器方法
readlines 讀取整個文件到一個迭代器以供我們遍歷
list2 = [1, 2, 3, 4, 5, 6]
random.shuffle(list2)
print(list2)
output
[4, 6, 5, 1, 2, 3]str1 = 'luobodazahui'
str1[::-1]
output
'iuhazadoboul'
__foo__:一種約定,Python 內部的名字,用來區別其他用戶自定義的命名,以防沖突,就是例如__init__(),__del__(),__call__()些特殊方法
_foo:一種約定,用來指定變量私有。不能用 from module import * 導入,其他方面和公有變量一樣訪問
__foo:這個有真正的意義:解析器用_classname__foo 來代替這個名字,以區別和其他類相同的命名,它無法直接像公有成員一樣隨便訪問,通過對象名._類名__xxx 這樣的方式可以訪問
a. 在 python 裡凡是繼承了 object 的類,都是新式類
b. Python3 裡只有新式類
c. Python2 裡面繼承 object 的是新式類,沒有寫父類的是經典類
d. 經典類目前在 Python 裡基本沒有應用
a. 同時支持單繼承與多繼承,當只有一個父類時為單繼承,當存在多個父類時為多繼承
b. 子類會繼承父類所有的屬性和方法,子類也可以覆蓋父類同名的變量和方法
c. 在繼承中基類的構造(__init__())方法不會被自動調用,它需要在其派生類的構造中專門調用
d. 在調用基類的方法時,需要加上基類的類名前綴,且需要帶上 self 參數變量。區別於在類中調用普通函數時並不需要帶上 self 參數
super() 函數是用於調用父類(超類)的一個方法
class A():
def funcA(self):
print("this is func A")
class B(A):
def funcA_in_B(self):
super(B, self).funcA()
def funcC(self):
print("this is func C")
ins = B()
ins.funcA_in_B()
ins.funcC()
output
this is func A
this is func C
主要分為實例方法、類方法和靜態方法
實例方法
定義:第一個參數必須是實例對象,該參數名一般約定為“self”,通過它來傳遞實例的屬性和方法(也可以傳類的屬性和方法)
調用:只能由實例對象調用
類方法
定義:使用裝飾器@classmethod。第一個參數必須是當前類對象,該參數名一般約定為“cls”,通過它來傳遞類的屬性和方法(不能傳實例的屬性和方法)
調用:實例對象和類對象都可以調用
靜態方法
定義:使用裝飾器@staticmethod。參數隨意,沒有“self”和“cls”參數,但是方法體中不能使用類或實例的任何屬性和方法
調用:實例對象和類對象都可以調用
靜態方法是類中的函數,不需要實例。靜態方法主要是用來存放邏輯性的代碼,主要是一些邏輯屬於類,但是和類本身沒有交互。即在靜態方法中,不會涉及到類中的方法和屬性的操作。可以理解為將靜態方法存在此類的名稱空間中
類方法是將類本身作為對象進行操作的方法。他和靜態方法的區別在於:不管這個方式是從實例調用還是從類調用,它都用第一個參數把類傳遞過來
與類和實例無綁定關系的 function 都屬於函數(function)
與類和實例有綁定關系的 function 都屬於方法(method)
普通函數:
def func1():
pass
print(func1)
output
<function func1 at 0x01379348>
類中的函數:
class People(object):
def func2(self):
pass
@staticmethod
def func3():
pass
@classmethod
def func4(cls):
pass
people = People()
print(people.func2)
print(people.func3)
print(people.func4)
output
<bound method People.func2 of <__main__.People object at 0x013B8C90>>
<function People.func3 at 0x01379390>
<bound method People.func4 of <class '__main__.People'>>
isinstance() 函數來判斷一個對象是否是一個已知的類型,類似 type()
區別:
type() 不會認為子類是一種父類類型,不考慮繼承關系
isinstance() 會認為子類是一種父類類型,考慮繼承關系
class A(object):
pass
class B(A):
pass
a = A()
b = B()
print(isinstance(a, A))
print(isinstance(b, A))
print(type(a) == A)
print(type(b) == A)
output
True
True
True
False單例模式:主要目的是確保某一個類只有一個實例存在
工廠模式:包涵一個超類,這個超類提供一個抽象化的接口來創建一個特定類型的對象,而不是決定哪個對象可以被創建
import os
print(os.listdir('.'))
# 1到5組成的互不重復的三位數
k = 0
for i in range(1, 6):
for j in range(1, 6):
for z in range(1, 6):
if (i != j) and (i != z) and (j != z):
k += 1
if k%6:
print("%s%s%s" %(i, j, z), end="|")
else:
print("%s%s%s" %(i, j, z))
output
123|124|125|132|134|135
142|143|145|152|153|154
213|214|215|231|234|235
241|243|245|251|253|254
312|314|315|321|324|325
341|342|345|351|352|354
412|413|415|421|423|425
431|432|435|451|452|453
512|513|514|521|523|524
531|532|534|541|542|543
str1 = " hello nihao "
str1.strip()
output
'hello nihao'
str2 = "hello you are good"
print(str2.replace(" ", ""))
"".join(str2.split(" "))
output
helloyouaregood
'helloyouaregood'
print("This is for %s" % "Python")
print("This is for %s, and %s" %("Python", "You"))
output
This is for Python
This is for Python, and You
在 Python3 中,引入了這個新的字符串格式化方法
print("This is my {}".format("chat"))
print("This is {name}, hope you can {do}".format(name="zhouluob", do="like"))
output
This is my chat
This is zhouluob, hope you can like
在 Python3-6 中,引入了這個新的字符串格式化方法
name = "luobodazahui"
print(f"hello {name}")
output
hello luobodazahui
一個復雜些的例子:
def mytest(name, age):
return f"hello {name}, you are {age} years old!"
people = mytest("luobo", 20)
print(people)
output
hello luobo, you are 20 years old!
str1 = "hello world"
print(str1.title())
" ".join(list(map(lambda x: x.capitalize(), str1.split(" "))))
output
Hello World
'Hello World'
如:[1, 2, 3] -> ["1", "2", "3"]
list1 = [1, 2, 3]
list(map(lambda x: str(x), list1))
output
['1', '2', '3']
如:("zhangfei", "guanyu"),(66, 80) -> {'zhangfei': 66, 'guanyu': 80}
a = ("zhangfei", "guanyu")
b = (66, 80)
dict(zip(a,b))
output
{'zhangfei': 66, 'guanyu': 80}
例子1:
a = (1,2,3,[4,5,6,7],8)
a[3] = 2
output
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-35-59469d550eb0> in <module>
1 a = (1,2,3,[4,5,6,7],8)
----> 2 a[3] = 2
3 #a
TypeError: 'tuple' object does not support item assignment
例子2:
a = (1,2,3,[4,5,6,7],8)
a[3][2] = 2
a
output
(1, 2, 3, [4, 5, 2, 7], 8)
從例子1的報錯中也可以看出,tuple 是不可變類型,不能改變 tuple 裡的元素,例子2中,list 是可變類型,改變其元素是允許的
反射就是通過字符串的形式,導入模塊;通過字符串的形式,去模塊尋找指定函數,並執行。利用字符串的形式去對象(模塊)中操作(查找/獲取/刪除/添加)成員,一種基於字符串的事件驅動!
簡單理解就是用來判斷某個字符串是什麼,是變量還是方法
class NewClass(object):
def __init__(self, name, male):
self.name = name
self.male = male
def myname(self):
print(f'My name is {self.name}')
def mymale(self):
print(f'I am a {self.male}')
people = NewClass('luobo', 'boy')
print(hasattr(people, 'name'))
print(getattr(people, 'name'))
setattr(people, 'male', 'girl')
print(getattr(people, 'male'))
output
True
luobo
girl
getattr,hasattr,setattr,delattr 對模塊的修改都在內存中進行,並不會影響文件中真實內容
使用 flask 構造 web 服務器
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['POST'])
def simple_api():
result = request.get_json()
return result
if __name__ == "__main__":
app.run()
類與實例:
首先定義類以後,就可以根據這個類創建出實例,所以:先定義類,然後創建實例
類與元類:
先定義元類, 根據 metaclass 創建出類,所以:先定義 metaclass,然後創建類
class MyMetaclass(type):
def __new__(cls, class_name, class_parents, class_attr):
class_attr['print'] = "this is my metaclass's subclass %s" %class_name
return type.__new__(cls, class_name, class_parents, class_attr)
class MyNewclass(object, metaclass=MyMetaclass):
pass
myinstance = MyNewclass()
myinstance.print
output
"this is my metaclass's subclass MyNewclass"56. Python 中的反射
反射就是通過字符串的形式,導入模塊;通過字符串的形式,去模塊尋找指定函數,並執行。利用字符串的形式去對象(模塊)中操作(查找/獲取/刪除/添加)成員,一種基於字符串的事件驅動!
簡單理解就是用來判斷某個字符串是什麼,是變量還是方法
class NewClass(object):
def __init__(self, name, male):
self.name = name
self.male = male
def myname(self):
print(f'My name is {self.name}')
def mymale(self):
print(f'I am a {self.male}')
people = NewClass('luobo', 'boy')
print(hasattr(people, 'name'))
print(getattr(people, 'name'))
setattr(people, 'male', 'girl')
print(getattr(people, 'male'))
output
True
luobo
girl
getattr,hasattr,setattr,delattr 對模塊的修改都在內存中進行,並不會影響文件中真實內容
57. 實現一個簡單的 API
使用 flask 構造 web 服務器
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['POST'])
def simple_api():
result = request.get_json()
return result
if __name__ == "__main__":
app.run()
58. metaclass 元類
類與實例:
首先定義類以後,就可以根據這個類創建出實例,所以:先定義類,然後創建實例
類與元類:
先定義元類, 根據 metaclass 創建出類,所以:先定義 metaclass,然後創建類
class MyMetaclass(type):
def __new__(cls, class_name, class_parents, class_attr):
class_attr['print'] = "this is my metaclass's subclass %s" %class_name
return type.__new__(cls, class_name, class_parents, class_attr)
class MyNewclass(object, metaclass=MyMetaclass):
pass
myinstance = MyNewclass()
myinstance.print
output
"this is my metaclass's subclass MyNewclass"sort() 是可變對象列表(list)的方法,無參數,無返回值,sort() 會改變可變對象
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(list1.sort())
list1
output
None
[1, 2, 3]
sorted() 是產生一個新的對象。sorted(L) 返回一個排序後的L,不改變原始的L,sorted() 適用於任何可迭代容器
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(sorted(dict1))print(sorted(list1))
output
['test1', 'test2']
[1, 2, 3]
GIL 是 Python 的全局解釋器鎖,同一進程中假如有多個線程運行,一個線程在運行 Python 程序的時候會占用 Python 解釋器(加了一把鎖即 GIL),使該進程內的其他線程無法運行,等該線程運行完後其他線程才能運行。如果線程運行過程中遇到耗時操作,則解釋器鎖解開,使其他線程運行。所以在多線程中,線程的運行仍是有先後順序的,並不是同時進行
import random
"".join(random.choice(string.printable[:-7]) for i in range(8))
output
'd5^NdNJp'
print('hello\nworld')
print(b'hello\nworld')
print(r'hello\nworld')
output
hello
world
b'hello\nworld'
hello\nworld
list1 = [{'name': 'guanyu', 'age':29},
{'name': 'zhangfei', 'age': 28},
{'name': 'liubei', 'age':31}]
sorted(list1, key=lambda x:x['age'])
output
[{'name': 'zhangfei', 'age': 28},
{'name': 'guanyu', 'age': 29},
{'name': 'liubei', 'age': 31}]
all 如果存在 0 Null False 返回 False,否則返回 True;any 如果都是 0,None,False,Null 時,返回 True
print(all([1, 2, 3, 0]))
print(all([1, 2, 3]))
print(any([1, 2, 3, 0]))
print(any([0, None, False]))
output
False
True
True
False def reverse_int(x):
if not isinstance(x, int):
return False
if -10 < x < 10:
return x
tmp = str(x)
if tmp[0] != '-':
tmp = tmp[::-1]
return int(tmp)
else:
tmp = tmp[1:][::-1]
x = int(tmp)
return -x
reverse_int(-23837)
output
-73832
首先判斷是否是整數,再判斷是否是一位數字,最後再判斷是不是負數
函數式編程是一種抽象程度很高的編程范式,純粹的函數式編程語言編寫的函數沒有變量,因此,任意一個函數,只要輸入是確定的,輸出就是確定的,這種純函數稱之為沒有副作用。而允許使用變量的程序設計語言,由於函數內部的變量狀態不確定,同樣的輸入,可能得到不同的輸出,因此,這種函數是有副作用的。由於 Python 允許使用變量,因此,Python 不是純函數式編程語言
函數式編程的一個特點就是,允許把函數本身作為參數傳入另一個函數,還允許返回一個函數!
函數作為返回值例子:
def sum(*args):
def inner_sum():
tmp = 0
for i in args:
tmp += i
return tmp
return inner_sum
mysum = sum(2, 4, 6)
print(type(mysum))
mysum()
output
<class 'function'>
12
如果在一個內部函數裡,對在外部作用域(但不是在全局作用域)的變量進行引用,那麼內部函數就被認為是閉包(closure) 附上函數作用域圖片
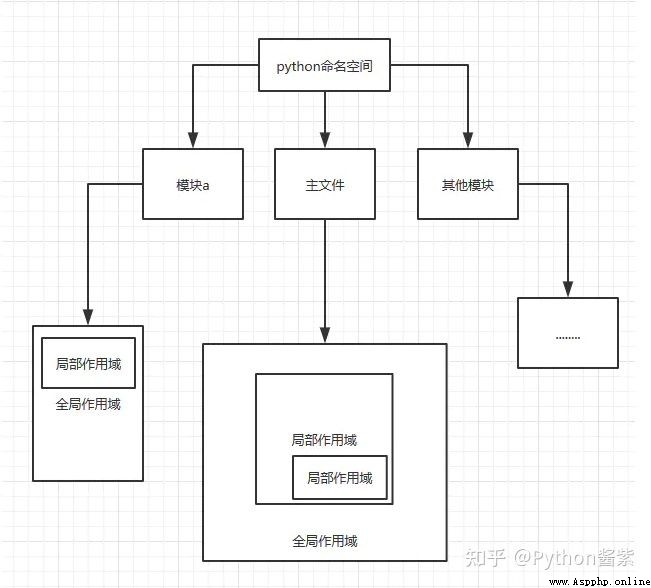
閉包特點
1.必須有一個內嵌函數
2.內嵌函數必須引用外部函數中的變量
3.外部函數的返回值必須是內嵌函數
裝飾器是一種特殊的閉包,就是在閉包的基礎上傳遞了一個函數,然後覆蓋原來函數的執行入口,以後調用這個函數的時候,就可以額外實現一些功能了
一個打印 log 的例子:
import time
def log(func):
def inner_log(*args, **kw):
print("Call: {}".format(func.__name__))
return func(*args, **kw)
return inner_log
@log
def timer():
print(time.time())
timer()
output
Call: timer
1560171403.5128365
本質上,decorator就是一個返回函數的高階函數
子程序切換不是線程切換,而是由程序自身控制
沒有線程切換的開銷,和多線程比,線程數量越多,協程的性能優勢就越明顯
不需要多線程的鎖機制,因為只有一個線程,也不存在同時寫變量沖突,在協程中控制共享資源不加鎖
斐波那契數列:
又稱黃金分割數列,指的是這樣一個數列:1、1、2、3、5、8、13、21、34、……在數學上,斐波納契數列以如下被以遞歸的方法定義:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
生成器法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n): # 判斷是正整數
return False
a, b = 0, 1
while n:
a, b = b, a+b
n -= 1
yield a
[i for i in fib(10)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
遞歸法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n):
return False
if n <= 1:
return n
return fib(n-1)+ fib(n-2)
[fib(i) for i in range(1, 11)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]import re
str1 = 'hello world:luobo dazahui'
result = re.split(r":| ", str1)
print(result)
output
['hello', 'world', 'luobo', 'dazahui']
yield 是用來生成迭代器的語法,在函數中,如果包含了 yield,那麼這個函數就是一個迭代器。當代碼執行至 yield 時,就會中斷代碼執行,直到程序調用 next() 函數時,才會在上次 yield 的地方繼續執行
def foryield():
print("start test yield")
while True:
result = yield 5
print("result:", result)
g = foryield()
print(next(g))
print("*"*20)
print(next(g))
output
start test yield
5
********************
result: None
5
可以看到,第一個調用 next() 函數,程序只執行到了 "result = yield 5" 這裡,同時由於 yield 中斷了程序,所以 result 也沒有被賦值,所以第二次執行 next() 時,result 是 None
list1 = [2, 5, 8, 9, 3, 11]
def paixu(data, reverse=False):
if not reverse:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] > data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
else:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] < data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
print(paixu(list1, reverse=True))
output
[11, 9, 8, 5, 3, 2]
快排的思想:首先任意選取一個數據(通常選用數組的第一個數)作為關鍵數據,然後將所有比它小的數都放到它前面,所有比它大的數都放到它後面,這個過程稱為一趟快速排序,之後再遞歸排序兩邊的數據
挑選基准值:從數列中挑出一個元素,稱為"基准"(pivot)
分割:重新排序數列,所有比基准值小的元素擺放在基准前面,所有比基准值大的元素擺在基准後面(與基准值相等的數可以到任何一邊)
在這個分割結束之後,對基准值的排序就已經完成
遞歸排序子序列:遞歸地將小於基准值元素的子序列和大於基准值元素的子序列排序
list1 = [8, 5, 1, 3, 2, 10, 11, 4, 12, 20]
def partition(arr,low,high):
i = ( low-1 ) # 最小元素索引
pivot = arr[high]
for j in range(low , high):
# 當前元素小於或等於 pivot
if arr[j] <= pivot:
i = i+1
arr[i],arr[j] = arr[j],arr[i]
arr[i+1],arr[high] = arr[high],arr[i+1]
return ( i+1 )
def quicksort(arr,low,high):
if low < high:
pi = partition(arr,low,high)
quicksort(arr, low, pi-1)
quicksort(arr, pi+1, high)
quicksort(list1, 0, len(list1)-1)
print(list1)
output
[1, 2, 3, 4, 5, 8, 10, 11, 12, 20]該庫是發起 HTTP 請求的強大類庫,調用簡單,功能強大
import requests
url = "http://www.luobodazahui.top"
response = requests.get(url) # 獲得請求
response.encoding = "utf-8" # 改變其編碼
html = response.text # 獲得網頁內容
binary__content = response.content # 獲得二進制數據
raw = requests.get(url, stream=True) # 獲得原始響應內容
headers = {'user-agent': 'my-test/0.1.1'} # 定制請求頭
r = requests.get(url, headers=headers)
cookies = {"cookie": "# your cookie"} # cookie的使用
r = requests.get(url, cookies=cookies)
dict1 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
dict2 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
def compare_dict(dict1, dict2):
issame = []
for k in dict1.keys():
if k in dict2:
if dict1[k] == dict2[k]:
issame.append(1)
else:
issame.append(2)
else:
issame.append(3)
print(issame)
sum_except = len(issame)
sum_actually = sum(issame)
if sum_except == sum_actually:
print("this two dict are same!")
return True
else:
print("this two dict are not same!")
return False
test = compare_dict(dict1, dict2)
output
[1, 1, 1]
this two dict are same!
input() 函數
def forinput():
input_text = input()
print("your input text is: ", input_text)
forinput()
output
hello
your input text is: hello
enumerate() 函數用於將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,同時列出數據和數據下標,一般用在 for 循環當中
data1 = ['one', 'two', 'three', 'four']
for i, enu in enumerate(data1):
print(i, enu)
output
0 one
1 two
2 three
3 four
pass 是空語句,是為了保持程序結構的完整性。pass 不做任何事情,一般用做占位語句
def forpass(n):
if n == 1:
pass
else:
print('not 1')
forpass(1)
import re
email_list= ["[email protected]","[email protected]", "[email protected]", "[email protected]" ]
for email in email_list:
ret = re.match("[\w]{4,20}@(.*)\.com$",email)
if ret:
print("%s 是符合規定的郵件地址,匹配後結果是:%s" % (email,ret.group()))
else:
print("%s 不符合要求" % email)
output
[email protected] 是符合規定的郵件地址,匹配後結果是:[email protected]
[email protected] 不符合要求
[email protected] 不符合要求
[email protected] 是符合規定的郵件地址,匹配後結果是:[email protected]
str2 = 'werrQWSDdiWuW'
counter = 0
for i in str2:
if i.isupper():
counter += 1
print(counter)
output
6
普通序列化:
import json
dict1 = {'name': '蘿卜', 'age': 18}
dict1_new = json.dumps(dict1)
print(dict1_new)
output
{"name": "\u841d\u535c", "age": 18}
保留中文
import json
dict1 = {'name': '蘿卜', 'age': 18}
dict1_new = json.dumps(dict1, ensure_ascii=False)
print(dict1_new)
output
{"name": "蘿卜", "age": 18}
一個類繼承自另一個類,也可以說是一個孩子類/派生類/子類,繼承自父類/基類/超類,同時獲取所有的類成員(屬性和方法)
繼承使我們可以重用代碼,並且還可以更方便地創建和維護代碼
Python 支持以下類型的繼承:
單繼承- 一個子類類繼承自單個基類
多重繼承- 一個子類繼承自多個基類
多級繼承- 一個子類繼承自一個基類,而基類繼承自另一個基類
分層繼承- 多個子類繼承自同一個基類
混合繼承- 兩種或兩種以上繼承類型的組合
猴子補丁是指在運行時動態修改類和模塊
猴子補丁主要有以下幾個用處:
在運行時替換方法、屬性等
在不修改第三方代碼的情況下增加原來不支持的功能
在運行時為內存中的對象增加 patch 而不是在磁盤的源代碼中增加
help() 函數返回幫助文檔和參數說明:
help(dict)
output
Help on class dict in module builtins:
class dict(object)
| dict() -> new empty dictionary
| dict(mapping) -> new dictionary initialized from a mapping object's
| (key, value) pairs
| dict(iterable) -> new dictionary initialized as if via:
| d = {}
| for k, v in iterable:
| d[k] = v
| dict(**kwargs) -> new dictionary initialized with the name=value pairs
| in the keyword argument list. For example: dict(one=1, two=2)
......
dir() 函數返回對象中的所有成員 (任何類型)
dir(dict)
output
['__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
......
//,%和**運算符// 運算符執行地板除法,返回結果的整數部分 (向下取整)
% 是取模符號,返回除法後的余數
** 符號表示取冪. a**b 返回 a 的 b 次方
print(5//3)
print(5/3)
print(5%3)
print(5**3)
output
1
1.6666666666666667
2
125
該庫是發起 HTTP 請求的強大類庫,調用簡單,功能強大
import requests
url = "http://www.luobodazahui.top"
response = requests.get(url) # 獲得請求
response.encoding = "utf-8" # 改變其編碼
html = response.text # 獲得網頁內容
binary__content = response.content # 獲得二進制數據
raw = requests.get(url, stream=True) # 獲得原始響應內容
headers = {'user-agent': 'my-test/0.1.1'} # 定制請求頭
r = requests.get(url, headers=headers)
cookies = {"cookie": "# your cookie"} # cookie的使用
r = requests.get(url, cookies=cookies)
dict1 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
dict2 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
def compare_dict(dict1, dict2):
issame = []
for k in dict1.keys():
if k in dict2:
if dict1[k] == dict2[k]:
issame.append(1)
else:
issame.append(2)
else:
issame.append(3)
print(issame)
sum_except = len(issame)
sum_actually = sum(issame)
if sum_except == sum_actually:
print("this two dict are same!")
return True
else:
print("this two dict are not same!")
return False
test = compare_dict(dict1, dict2)
output
[1, 1, 1]
this two dict are same!
input() 函數
def forinput():
input_text = input()
print("your input text is: ", input_text)
forinput()
output
hello
your input text is: hello
enumerate() 函數用於將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,同時列出數據和數據下標,一般用在 for 循環當中
data1 = ['one', 'two', 'three', 'four']
for i, enu in enumerate(data1):
print(i, enu)
output
0 one
1 two
2 three
3 four
pass 是空語句,是為了保持程序結構的完整性。pass 不做任何事情,一般用做占位語句
def forpass(n):
if n == 1:
pass
else:
print('not 1')
forpass(1)
import re
email_list= ["[email protected]","[email protected]", "[email protected]", "[email protected]" ]
for email in email_list:
ret = re.match("[\w]{4,20}@(.*)\.com$",email)
if ret:
print("%s 是符合規定的郵件地址,匹配後結果是:%s" % (email,ret.group()))
else:
print("%s 不符合要求" % email)
output
[email protected] 是符合規定的郵件地址,匹配後結果是:[email protected]
[email protected] 不符合要求
[email protected] 不符合要求
[email protected] 是符合規定的郵件地址,匹配後結果是:[email protected]
str2 = 'werrQWSDdiWuW'
counter = 0
for i in str2:
if i.isupper():
counter += 1
print(counter)
output
6
普通序列化:
import json
dict1 = {'name': '蘿卜', 'age': 18}
dict1_new = json.dumps(dict1)
print(dict1_new)
output
{"name": "\u841d\u535c", "age": 18}
保留中文
import json
dict1 = {'name': '蘿卜', 'age': 18}
dict1_new = json.dumps(dict1, ensure_ascii=False)
print(dict1_new)
output
{"name": "蘿卜", "age": 18}
一個類繼承自另一個類,也可以說是一個孩子類/派生類/子類,繼承自父類/基類/超類,同時獲取所有的類成員(屬性和方法)
繼承使我們可以重用代碼,並且還可以更方便地創建和維護代碼
Python 支持以下類型的繼承:
單繼承- 一個子類類繼承自單個基類
多重繼承- 一個子類繼承自多個基類
多級繼承- 一個子類繼承自一個基類,而基類繼承自另一個基類
分層繼承- 多個子類繼承自同一個基類
混合繼承- 兩種或兩種以上繼承類型的組合
猴子補丁是指在運行時動態修改類和模塊
猴子補丁主要有以下幾個用處:
在運行時替換方法、屬性等
在不修改第三方代碼的情況下增加原來不支持的功能
在運行時為內存中的對象增加 patch 而不是在磁盤的源代碼中增加
help() 函數返回幫助文檔和參數說明:
help(dict)
output
Help on class dict in module builtins:
class dict(object)
| dict() -> new empty dictionary
| dict(mapping) -> new dictionary initialized from a mapping object's
| (key, value) pairs
| dict(iterable) -> new dictionary initialized as if via:
| d = {}
| for k, v in iterable:
| d[k] = v
| dict(**kwargs) -> new dictionary initialized with the name=value pairs
| in the keyword argument list. For example: dict(one=1, two=2)
......
dir() 函數返回對象中的所有成員 (任何類型)
dir(dict)
output
['__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
......
//,%和**運算符// 運算符執行地板除法,返回結果的整數部分 (向下取整)
% 是取模符號,返回除法後的余數
** 符號表示取冪. a**b 返回 a 的 b 次方
print(5//3)
print(5/3)
print(5%3)
print(5**3)
output
1
1.6666666666666667
2
125
使用 raise
def test_raise(n):
if not isinstance(n, int):
raise Exception('not a int type')
else:
print('good')
test_raise(8.9)
output
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
<ipython-input-262-b45324f5484e> in <module>
4 else:
5 print('good')
----> 6 test_raise(8.9)
<ipython-input-262-b45324f5484e> in test_raise(n)
1 def test_raise(n):
2 if not isinstance(n, int):
----> 3 raise Exception('not a int type')
4 else:
5 print('good')
Exception: not a int type
tuple1 = (1, 2, 3, 4)
list1 = list(tuple1)
print(list1)
tuple2 = tuple(list1)
print(tuple2)
output
[1, 2, 3, 4](1, 2, 3, 4)
Python 的斷言就是檢測一個條件,如果條件為真,它什麼都不做;反之它觸發一個帶可選錯誤信息的 AssertionError
def testassert(n):
assert n == 2, "n is not 2"
print('n is 2')
testassert(1)
output
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-268-a9dfd6c79e73> in <module>
2 assert n == 2, "n is not 2"
3 print('n is 2')
----> 4 testassert(1)
<ipython-input-268-a9dfd6c79e73> in testassert(n)
1 def testassert(n):
----> 2 assert n == 2, "n is not 2"
3 print('n is 2')
4 testassert(1)
AssertionError: n is not 2
同步異步指的是調用者與被調用者之間的關系
所謂同步,就是在發出一個功能調用時,在沒有得到結果之前,該調用就不會返回,一旦調用返回,就得到了返回值
異步的概念和同步相對,調用在發出之後,這個調用就直接返回了,所以沒有返回結果。當該異步功能完成後,被調用者可以通過狀態、通知或回調來通知調用者
阻塞非阻塞是線程或進程之間的關系
阻塞調用是指調用結果返回之前,當前線程會被掛起(如遇到io操作)。調用線程只有在得到結果之後才會返回。函數只有在得到結果之後才會將阻塞的線程激活
非阻塞和阻塞的概念相對應,非阻塞調用指在不能立刻得到結果之前也會立刻返回,同時該函數不會阻塞當前線程
Python 中的序列是有索引的,它由正數和負數組成。正的數字使用'0'作為第一個索引,'1'作為第二個索引,以此類推
負數的索引從'-1'開始,表示序列中的最後一個索引,' - 2'作為倒數第二個索引,依次類推
不是的,那些具有對象循環引用或者全局命名空間引用的變量,在 Python 退出時往往不會被釋放
另外不會釋放 C 庫保留的部分內容
Flask 是 “microframework”,主要用來編寫小型應用程序,不過隨著 Python 的普及,很多大型程序也在使用 Flask。同時,在 Flask 中,我們必須使用外部庫
Django 適用於大型應用程序。它提供了靈活性,以及完整的程序框架和快速的項目生成方法。可以選擇不同的數據庫,URL結構,模板樣式等
import os
f = open('test.txt', 'w')
f.close()
os.listdir()
os.remove('test.txt')
logging 模塊是 Python 內置的標准模塊,主要用於輸出運行日志,可以設置輸出日志的等級、日志保存路徑、日志文件回滾等;相比 print,具備如下優點:
可以通過設置不同的日志等級,在 release 版本中只輸出重要信息,而不必顯示大量的調試信息
print 將所有信息都輸出到標准輸出中,嚴重影響開發者從標准輸出中查看其它數據;logging 則可以由開發者決定將信息輸出到什麼地方,以及怎麼輸出
簡單配置:
import logging
logging.debug("debug log")
logging.info("info log")
logging.warning("warning log")
logging.error("error log")
logging.critical("critica log")
output
WARNING:root:warning log
ERROR:root:error log
CRITICAL:root:critica log
默認情況下,只顯示了大於等於WARNING級別的日志。logging.basicConfig()函數調整日志級別、輸出格式等
from collections import Counter
str1 = "nihsasehndciswemeotpxc"
print(Counter(str1))
output
Counter({'s': 3, 'e': 3, 'n': 2, 'i': 2, 'h': 2, 'c': 2, 'a': 1, 'd': 1, 'w': 1, 'm': 1, 'o': 1, 't': 1, 'p': 1, 'x': 1})
re.compile 是將正則表達式編譯成一個對象,加快速度,並重復使用
try..except..else 沒有捕獲到異常,執行 else 語句
try..except..finally 不管是否捕獲到異常,都執行 finally 語句
使用切片:
$ python -m timeit -n 1000000 -s 'import numpy as np' 'mylist=list(np.arange(0, 200))' 'mylist[::-1]'
1000000 loops, best of 5: 15.6 usec per loop
使用 reverse():
$ python -m timeit -n 1000000 -s 'import numpy as np' 'mylist=list(np.arange(0, 200))' 'mylist.reverse()'
1000000 loops, best of 5: 10.7 usec per loop
這兩種方法都可以反轉列表,但需要注意的是內置函數 reverse() 會更改原始列表,而切片方法會創建一個新列表。
顯然,內置函數 reverse() 比列表切片方法更快!
使用 re 正則替換
import re
str1 = '我是周蘿卜,今年18歲'
result = re.sub(r"\d+","20",str1)
print(result)
output
我是周蘿卜,今年20歲阿裡師兄整理的170道Python面試題完整PDF下載地址