目錄
一、什麼是Q learning算法?
1.Q table
2.Q-learning算法偽代碼
二、Q-Learning求解TSP的python實現
1)問題定義
2)創建TSP環境
3)定義 DeliveryQAgent類
4)定義每個episode下agent學習的過程
5) 定義訓練的主函數
6)實驗結果
1. 環境創建
2.實例化agent類
3.agent訓練學習
Q-learning算法非常適合新手入門理解強化學習,它是最容易編碼和理解的。 Q-learning算法是一種model-free、off-policy/value_based的強化學習算法,即不考慮環境的特征,通過Q函數尋找最優的動作選擇策略。Q值(action value function)計算的是當前狀態下采取該動作的未來獎勵期望,公式推導如下:
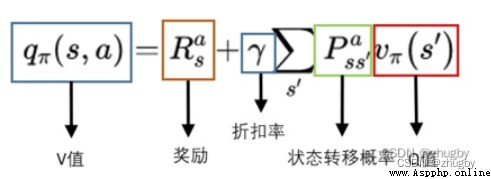
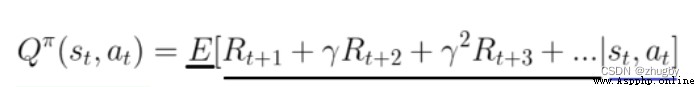
更多強化學習基本原理和概念見強化學習系列(一):基本原理和概念
Q代表quality,即動作的質量。創建一個表格Q,將state-action-Q估計值存儲進去,通過檢索Q表,就能獲取在當前state下選取各個action能夠獲得的未來獎勵期望的估計值,Q-learning中最核心的就是不停更新Q表給出越來越好的近似。

步驟一:創建並初始化一個action-space*state space大小的Q表,一般初始化設置所有值為0;
步驟二:進入循環,直到達到迭代條件:
步驟三:檢索Q表,在當前狀態 s下根據Q的估計值和Policy選擇一個action a;
步驟四:執行action a,檢索Q表,轉移到的狀態 對應的Q最大值加上該動作得到的實時獎勵reward是狀態 s價值的真實值;
對應的Q最大值加上該動作得到的實時獎勵reward是狀態 s價值的真實值;
步驟五:根據貝爾曼方程更新Q表。
那麼,開始時Q值都為0,我們該怎麼選擇下一個動作呢?這個時候就體現Policy的重要性了,常見做法是引入一個參數 ,取值在0-1之間,體現了探索/利用(exploration/exploitation)的權衡。越大,隨機性/探索性越強,通常初始情況下接近或等於1隨機選擇下一個動作進行大量的探索;隨著agent的不斷學習,對Q的估計越來越准確,我們將逐漸減小的值,更多依賴利用當前的Q值。
,取值在0-1之間,體現了探索/利用(exploration/exploitation)的權衡。越大,隨機性/探索性越強,通常初始情況下接近或等於1隨機選擇下一個動作進行大量的探索;隨著agent的不斷學習,對Q的估計越來越准確,我們將逐漸減小的值,更多依賴利用當前的Q值。
旅行商問題( TSP)是一個典型的優化問題,目的是找到訪問各個城市的最短路線。要使用RL的方法解決TSP問題,就需要把TSP問題轉化為RL問題,定義RL的各要素:
agent:送貨人;
environment:要交付的商品和要訪問的城市節點位置;
state:當前送貨員所在的城市節點;
action:在每個節點要做出的決策,下一步去哪一個節點;
reward:實時的獎勵,兩個節點之間的距離多長。
RL的目標goal是使得reward的求和最大,即訪問路線的距離最短。
在python中創建一個簡單的TSP環境非常簡單,指定城市節點數量,隨機生成城市節點坐標;並計算不同城市間的距離作為reward值。python具體實現代碼如下,創建了一個DeliveryEnvironment類,默認的城市節點數是10個,隨機選擇一個節點作為出發點,定義了一個畫圖的函數展示TSP的Environment。
#導入需要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import time
from tqdm import tqdm_notebook
from scipy.spatial.distance import cdist
import imageio
from matplotlib.patches import Rectangle
from matplotlib.collections import PatchCollection
plt.style.use("seaborn-dark")
import sys
sys.path.append("../")
from rl.agents.q_agent import QAgent
class DeliveryEnvironment(object): #初始化環境
def __init__(self,n_stops = 10,max_box = 10,method = "distance",**kwargs):
print(f"Initialized Delivery Environment with {n_stops} random stops")
print(f"Target metric for optimization is {method}")
# 參數初始化
self.n_stops = n_stops
self.action_space = self.n_stops
self.observation_space = self.n_stops
self.max_box = max_box
self.stops = []
self.method = method
# 產生城市節點
self._generate_constraints(**kwargs)
self._generate_stops()
self._generate_q_values()
self.render()
# 初始化環境
self.reset()
def _generate_stops(self): #產生城市節點
# Generate geographical coordinates
xy = np.random.rand(self.n_stops,2)*self.max_box #產生客戶點坐標
self.x = xy[:,0]
self.y = xy[:,1]
def _generate_q_values(self,box_size = 0.2): #計算不同節點之間的距離充當reward
# Generate actual Q Values corresponding to time elapsed between two points
if self.method in ["distance"]:
xy = np.column_stack([self.x,self.y])
self.q_stops = cdist(xy,xy) #計算距離矩陣充當reward
else:
raise Exception("Method not recognized")
#畫圖的函數
def render(self,return_img = False):
fig = plt.figure(figsize=(7,7))
ax = fig.add_subplot(111)
ax.set_title("Delivery Stops")
# Show stops
ax.scatter(self.x,self.y,c = "red",s = 50)
# Show START
if len(self.stops)>0:
xy = self._get_xy(initial = True) #生成的第一個點作為start點,文本位置在xy[1]-0.05
xytext = xy[0]+0.1,xy[1]-0.05
ax.annotate("START",xy=xy,xytext=xytext,weight = "bold")
# Show itinerary
if len(self.stops) > 1:
ax.plot(self.x[self.stops],self.y[self.stops],c = "blue",linewidth=1,line)
# 路徑結尾要回到出發點
xy = self._get_xy(initial = False)
xytext = xy[0]+0.1,xy[1]-0.05
ax.annotate("END",xy=xy,xytext=xytext,weight = "bold")
if hasattr(self,"box"):
left,bottom = self.box[0],self.box[2]
width = self.box[1] - self.box[0]
height = self.box[3] - self.box[2]
rect = Rectangle((left,bottom), width, height)
collection = PatchCollection([rect],facecolor = "red",alpha = 0.2)
ax.add_collection(collection)
plt.xticks([])
plt.yticks([])
if return_img:
# From https://ndres.me/post/matplotlib-animated-gifs-easily/
fig.canvas.draw_idle()
image = np.frombuffer(fig.canvas.tostring_rgb(), dtype='uint8')
image = image.reshape(fig.canvas.get_width_height()[::-1] + (3,))
plt.close()
return image
else:
plt.show()
#重置進入下一輪迭代
def reset(self):
# Stops placeholder
self.stops = []
# Random first stop
first_stop = np.random.randint(self.n_stops) #隨機生成第一個初始節點
self.stops.append(first_stop)
return first_stop
#根據reward選擇下一個動作
def step(self,destination):
# Get current state 得到當前的state
state = self._get_state()
new_state = destination
# Get reward for such a move 每個action得到reward
reward = self._get_reward(state,new_state)
# Append new_state to stops 進入下一個state
self.stops.append(destination)
done = len(self.stops) == self.n_stops
return new_state,reward,done
#得到當前狀態 即當前到達的節點位置
def _get_state(self):
return self.stops[-1]
#得到每個坐標的X和Y值
def _get_xy(self,initial = False):
state = self.stops[0] if initial else self._get_state()
x = self.x[state]
y = self.y[state]
return x,y
#定義reward函數
def _get_reward(self,state,new_state): #
base_reward = self.q_stops[state,new_state] #base_reward是兩個節點之間的距離
if self.method == "distance":
return base_reward
@staticmethod
def _calculate_point(x1,x2,y1,y2,x = None,y = None):
if y1 == y2:
return y1
elif x1 == x2:
return x1
else:
a = (y2-y1)/(x2-x1)
b = y2 - a * x2
if x is None:
x = (y-b)/a
return x
elif y is None:
y = a*x+b
return y
else:
raise Exception("Provide x or y")
決定選擇下一個節點的Policy,隨機產生一個0-1之間的值,如果比大,選擇Q值最大的action,否則隨機選擇一個未訪問過的節點去訪問。
class DeliveryQAgent(QAgent):
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
self.reset_memory()
def act(self,s):
# Get Q Vector copyq表
q = np.copy(self.Q[s,:])
# Avoid already visited states 屏蔽已經走過的節點 這個地方應該可以加約束條件起到mask一些節點的作用
q[self.states_memory] = -np.inf
if np.random.rand() > self.epsilon:
a = np.argmax(q)
else:
a = np.random.choice([x for x in range(self.actions_size) if x not in self.states_memory])
return a
def remember_state(self,s):
self.states_memory.append(s)
def reset_memory(self):
self.states_memory = []每一次迭代需要將環境reset到初始狀態,隨機選擇一個節點作為初始節點,然後根據Policy不斷去選擇下一個節點並更新Q值。
#每一個episode學習的函數
def run_episode(env,agent,verbose = 1):
s = env.reset()
agent.reset_memory()
max_step = env.n_stops
episode_reward = 0
i = 0
while i < max_step: #節點個數
# Remember the states 存儲已經走過的點
agent.remember_state(s)
# Choose an action 選擇一個action
a = agent.act(s)
# Take the action, and get the reward from environment 得到一個reward
s_next,r,done = env.step(a)
# Tweak the reward 加負號最小化問題變成最大化問題
r = -1 * r
if verbose: print(s_next,r,done)
# Update our knowledge in the Q-table 更新reward在Q表中
agent.train(s,a,r,s_next)
# Update the caches 累加reward
episode_reward += r
s = s_next
# If the episode is terminated
i += 1
if done:
break
return env,agent,episode_reward 在導入的QAgent.py裡定義了更新Q值的函數如下,也就是貝爾曼公式,通常epsilon_decay小於1,也就是隨著學習的不斷進行,的值在不斷減小,探索性降低。
def train(self,s,a,r,s_next):
self.Q[s,a] = self.Q[s,a] + self.lr * (r + self.gamma*np.max(self.Q[s_next,a]) - self.Q[s,a])
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay並輸出訓練過程的動圖及迭代訓練過程中reward值得變化趨勢。
#模型訓練的函數
def run_n_episodes(env,agent,name="training.gif",n_episodes=1000,render_each=10,fps=10): #訓練1000次,10次畫圖一次
# Store the rewards 存儲下reward和圖形
rewards = []
imgs = []
# Experience replay
for i in tqdm_notebook(range(n_episodes)):
# Run the episode 迭代學習
env,agent,episode_reward = run_episode(env,agent,verbose = 0)
rewards.append(episode_reward)
if i % render_each == 0:
img = env.render(return_img = True)
imgs.append(img)
# Show rewards 畫出reward的變化趨勢
plt.figure(figsize = (15,3))
plt.title("Rewards over training")
plt.plot(rewards)
plt.show()
# Save imgs as gif
imageio.mimsave(name,imgs,fps = fps) #輸出動圖,fps是幀率(每秒播放的幀數)
return env,agent調用以上定義的類和函數,現簡單實現一個規模為500個旅行商的TSP問題。
指定規模為500,選定衡量reward的方法是distance;
env = DeliveryEnvironment(n_stops = 500,method = "distance") #隨機生成500個節點輸出環境如下:
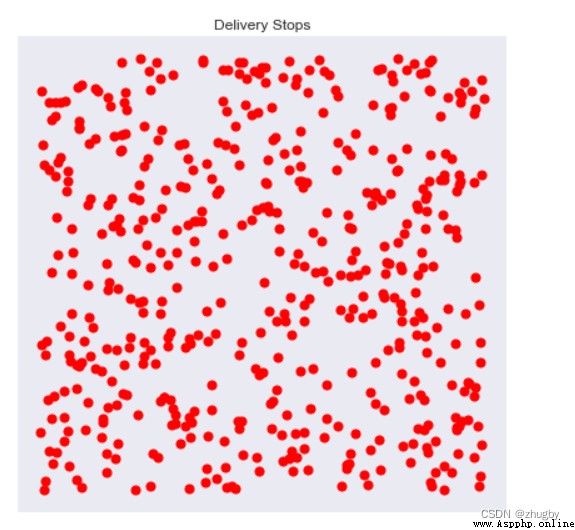
還可以通過在各個走過的節點之間畫線可視化路徑,距離畫出路徑的前幾個點:
for i in [0,1,2,3]: #畫出接下來幾步要走的路徑
env.step(i)
env.render()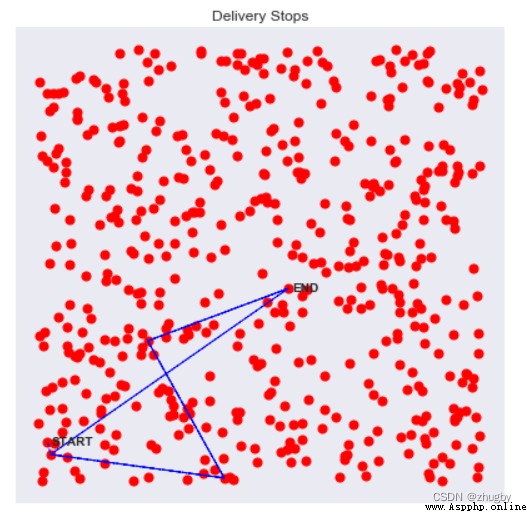
agent = DeliveryQAgent(env.observation_space,env.action_space) #env.observation_space和action_space都是節點數默認迭代學習1000次,可以根據需求更改;記錄訓練的時間。
start=time.time()
run_n_episodes(env,agent,"training_500_stops.gif") #訓練1000次reward的變化趨勢 前400次基本上是在隨機選擇一個節點行走,後面就用到了之前行走的經驗,Q表中沒有的就設置reward,有的就更新
end=time.time()
print('運行時間',end-start)模型輸出的reward變化趨勢及運行時間如下:
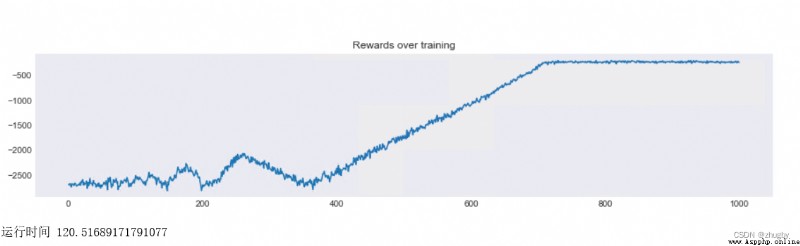
前400次迭代,基本都在探索新的不同的路線,隨機性很強;400次迭代往後,agent開始利用自己所學到的東西,越來越少的采取隨機行動而是傾向於選擇Q值最大的行動;800次左右開始基本收斂到一個可接受的路線。
迭代訓練過程的動圖也能反映出開始雜亂無章不斷探索然後趨於收斂到一個可接受的路線。







