although scrapy There are many things that can be done , But it's hard to achieve large-scale distributed applications . Someone who can change scrapy Queue scheduling for , Change the starting URL from start_urls It's separated from me , Instead of from redis Read , Multiple clients can read the same data at the same time redis, Thus, the distributed crawler . Even on the same computer , You can also run crawlers with multiple processes , It is very effective in the process of large-scale capture .
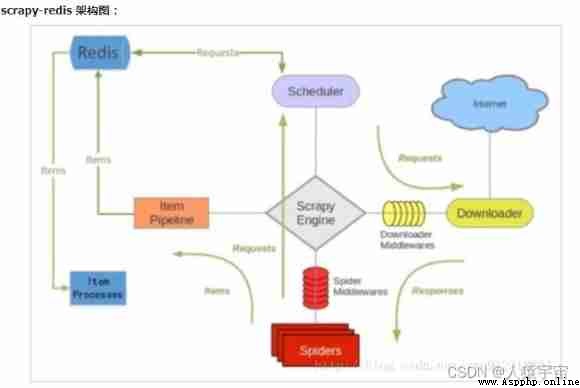
One more. redis Components , It mainly affects two places : The first is the scheduler . The second is data processing .
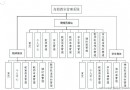
Scrapy-Redis Distributed strategy .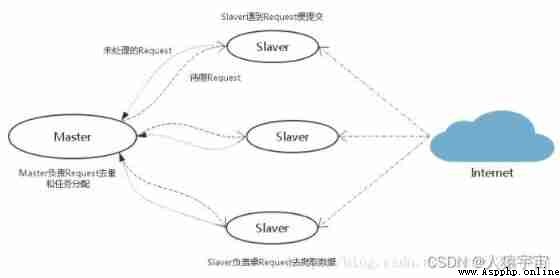
As a distributed crawler , There needs to be a Master End ( Core server ) Of , stay Master End , Will build a Redis database , Used to store start_urls、request、items.Master Is responsible for url Fingerprint weight ,Request The distribution of , And data storage ( Generally in Master One will be installed at the end mongodb Used to store redis Medium items). It's out Master outside , Another role is slaver( Crawler execution end ), It is mainly responsible for executing crawler programs to crawl data , And will crawl in the process of new Request Submitted to the Master Of redis In the database .
Pictured above , Suppose we have four computers :A, B, C, D , Any computer can be used as Master End or Slaver End . The whole process is :
First Slaver End slave Master Take the task (Request、url) Grab data ,Slaver While grabbing data , To create a new task Request Then submit it to Master Handle ;
Master There is only one end Redis database , Be responsible for taking care of what is not handled Request De duplication and task allocation , Will deal with the Request Join queue to be crawled , And store the crawled data .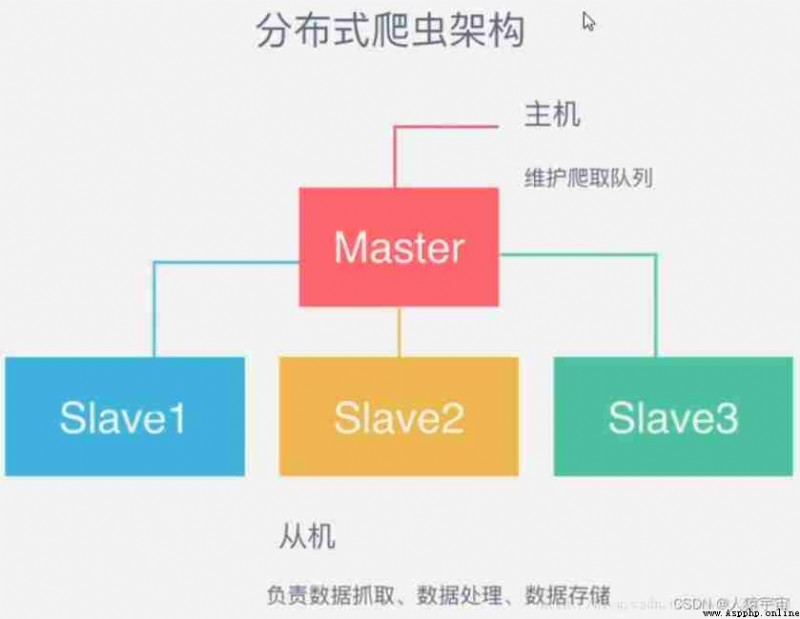
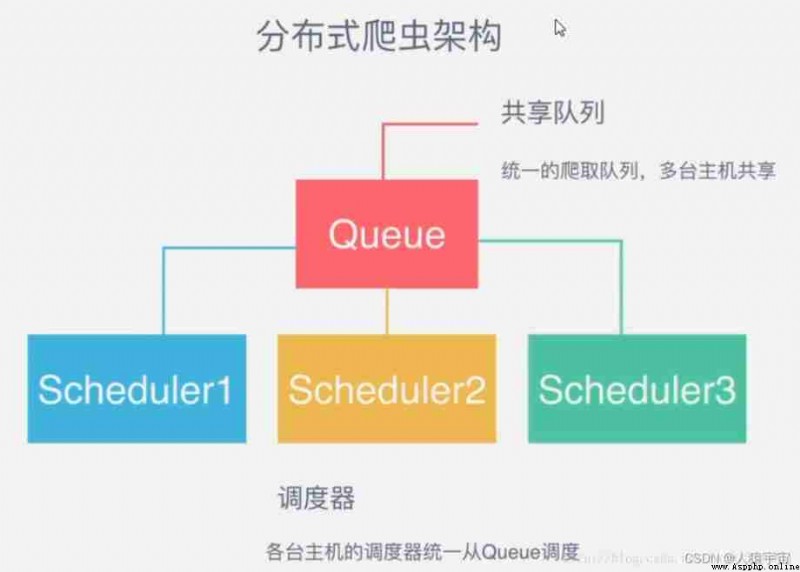
Scrapy-Redis The default is this strategy , It's easy for us to realize , Because of task scheduling and so on Scrapy-Redis It's all done for us , We just need to inherit RedisSpider、 Appoint redis_key That's it .
The disadvantage is that ,Scrapy-Redis The scheduled task is Request object , There's a lot of information in it ( It's not just about url, also callback function 、headers Etc ), The possible result is that it will slow down the speed of the reptiles 、 And will occupy Redis A lot of storage space , So if we want to ensure efficiency , Then we need a certain level of hardware .
1、windows a ( from :scrapy)
2、linux a ( Lord :scrapy\redis\mongo)
ip:192.168.184.129
3、python3.6
linux Next scrapy Configuration steps :
1、 install python3.6
yum install openssl-devel -y solve pip3 Problems that cannot be used (pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available)
download python software package ,Python-3.6.1.tar.xz, After decompressing
./configure --prefix=/python3
make
make install
Add environment variables :
PATH=/python3/bin:$PATH:$HOME/bin
export PATH
After installation ,pip3 By default, the installation has been completed ( Before installation yum gcc)
2、 install Twisted
download Twisted-17.9.0.tar.bz2, After decompressing cd Twisted-17.9.0, python3 setup.py install
3、 install scrapy
pip3 install scrapy
pip3 install scrapy-redis
4、 install redis
See Bowen redis Installation and simple use
error :You need tcl 8.5 or newer in order to run the Redis test
1、wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz
2、tar -xvf tcl8.6.1-src.tar.gz
3、cd tcl8.6.1/unix ; make; make install
cp /root/redis-3.2.11/redis.conf /etc/
start-up :/root/redis-3.2.11/src/redis-server /etc/redis.conf &
5、pip3 install redis
6、 install mongodb
start-up :# mongod --bind_ip 192.168.184.129 &
7、pip3 install pymongo
windows On scrapy Deployment steps :
1、 install wheel
pip install wheel
2、 install lxml
https://pypi.python.org/pypi/lxml/4.1.0
3、 install pyopenssl
https://pypi.python.org/pypi/pyOpenSSL/17.5.0
4、 install Twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/
5、 install pywin32
https://sourceforge.net/projects/pywin32/files/
6、 install scrapy
pip install scrapy
Take the movie crawling of XXX heaven as a simple example , Talk about distributed implementation , Code linux and windows Put one on each , The configuration is the same , Both can run crawling at the same time .
Only list the places that need to be modified :
Set the storage database for crawling data (mongodb), Fingerprints and queue Stored database (redis)
ROBOTSTXT_OBEY = False # prohibit robot
CONCURRENT_REQUESTS = 1 # scrapy debugging queue Maximum concurrency , Default 16
ITEM_PIPELINES = {
'meiju.pipelines.MongoPipeline': 300,
}
MONGO_URI = '192.168.184.129' # mongodb Connection information
MONGO_DATABASE = 'mj'
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # Use scrapy_redis The scheduling
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # stay redis De duplication in the library (url)
# REDIS_URL = 'redis://root:[email protected]:6379' # If redis Password , Use this configuration
REDIS_HOST = '192.168.184.129' #redisdb Connection information
REDIS_PORT = 6379
SCHEDULER_PERSIST = True # Don't empty fingerprints
Store in MongoDB Code for
import pymongo
class MeijuPipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
collection_name = 'movies'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item
data structure
import scrapy
class MeijuItem(scrapy.Item):
movieName = scrapy.Field()
status = scrapy.Field()
english = scrapy.Field()
alias = scrapy.Field()
tv = scrapy.Field()
year = scrapy.Field()
type = scrapy.Field()
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
class MjSpider(scrapy.Spider):
name = 'mj'
allowed_domains = ['meijutt1.com']
# start_urls = ['http://www.example1.com/file/list1.html']
def start_requests(self):
yield Request(url='http://www.example1.com/file/list1.html', callback=self.parse)
def parse(self, response):
from meiju.items import MeijuItem
movies = response.xpath('//div[@class="cn_box2"]')
for movie in movies:
item = MeijuItem()
item['movieName'] = movie.xpath('./ul[@class="list_20"]/li[1]/a/text()').extract_first()
item['status'] = movie.xpath('./ul[@class="list_20"]/li[2]/span/font/text()').extract_first()
item['english'] = movie.xpath('./ul[@class="list_20"]/li[3]/font[2]/text()').extract_first()
item['alias'] = movie.xpath('./ul[@class="list_20"]/li[4]/font[2]/text()').extract_first()
item['tv'] = movie.xpath('./ul[@class="list_20"]/li[5]/font[2]/text()').extract_first()
item['year'] = movie.xpath('./ul[@class="list_20"]/li[6]/font[2]/text()').extract_first()
item['type'] = movie.xpath('./ul[@class="list_20"]/li[7]/font[2]/text()').extract_first()
yield item
for i in response.xpath('//div[@class="cn_box2"]/ul[@class="list_20"]/li[1]/a/@href').extract():
yield Request(url='http://www.example1.com' + i)
# next = 'http://www.example1.com' + response.xpath("//a[contains(.,' The next page ')]/@href")[1].extract()
# print(next)
# yield Request(url=next, callback=self.parse)
Insert picture description here 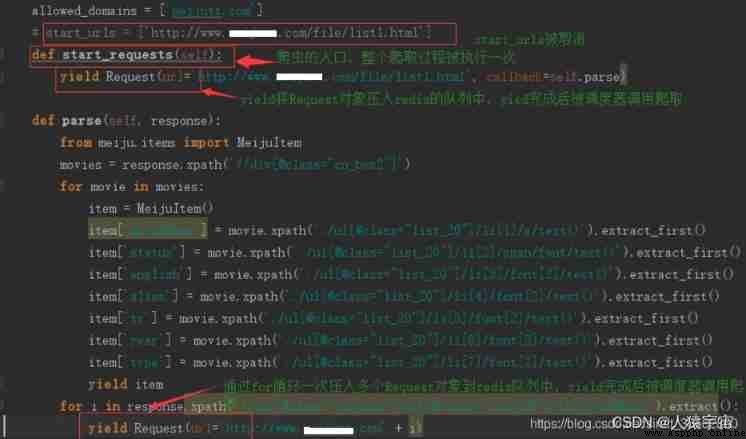
to glance at redis Situation in :
have a look mongodb Data in :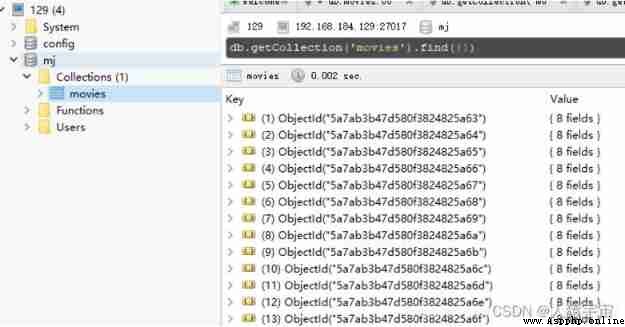
 Graduation project based on python+vue+elementui+django college classroom management system (front and back end separation)
Graduation project based on python+vue+elementui+django college classroom management system (front and back end separation)
With the development of societ