最近在學習使用python寫優化算法求解tsp問題,因此會導入一些.tsp類型的算例,如:berbin8等、berlin52等、a208.tsp等,那麼如何用python導入.tsp文件呢?淺淺記錄一下問題。
1.先來看看berlin8.tsp文件的數據格式,可以看到,第7行開始記錄節點的坐標,最後一行是結束標志也沒有用,基本所有的算例都是這樣的格式;
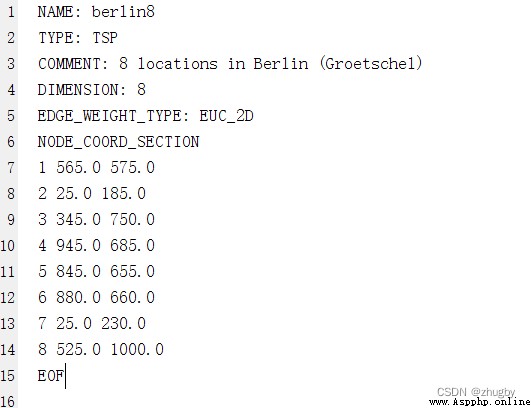
2.這裏我使用pandas導入數據,注意需要跳過前六行不讀取(skiprows=6)
df = pd.read_csv(r".\組合優化學習\demo_tsp\berlin8.tsp",sep=" ",skiprows=6,header=None,encoding='utf8')
然後再讀取節點和坐標,代碼如下所示:
df = pd.read_csv(r".\組合優化學習\demo_tsp\berlin8.tsp",sep=" ",skiprows=6,header=None,encoding='utf8')
node=list(df[0][0:-1])
num_points=len(node)
city_x = np.array(df[1][0:-1])
city_y = np.array(df[2][0:-1])
points= list(zip(city_x, city_y))打印一下讀入的節點坐標,成功啦,接下來就可以寫算法解決tsp問題了。

3.還沒有完,,,,,我用了同樣的方法打開berlin52.tsp文件時,報錯了!這句報錯的意思是在讀取文件的17行的時候期待3個字段,即df有三列,但是出現了四個字段,源文件的字段出了問題。
ParserError: Error tokenizing data. C error: Expected 3 fields in line 17, saw 44.在網上找了很多辦法都比較繁瑣且不一定有用,我用了一個簡單粗暴的方法。先設置error_bad_lines=False,然後讀取文件時會print哪幾行有錯直接跳過沒讀取,以及錯誤的原因。
df = pd.read_csv(r".\組合優化學習\demo_tsp\berlin52.tsp",sep=" ",skiprows=6,header=None,error_bad_lines=False)結果:
b'Skipping line 17: expected 3 fields, saw 4\nSkipping line 25: expected 3 fields, saw 5\n
結果可以看出第17行和第25行有多出來了幾個字符,是換行符\n;
最簡單的辦法是直接打開.tsp文件,找到17和25行,刪掉該行,再重新輸入一遍保存就好了。
5.再運行第四步的代碼重新讀取不再報錯,全部讀入。