類似於人的眼睛和大腦,OpenCV可以檢測圖像的主要特征並將這
些特征提取到所謂的圖像描述符中。然後,可以將這些特征作為數據
庫,支持基於圖像的搜索。此外,我們可以使用關鍵點將圖像拼接起
來,組成更大的圖像。(想象一下把很多圖片放到一起組成一幅360°
的全景圖。)
本章將展示如何使用OpenCV檢測圖像中的特征,並利用這些特征
匹配和檢索圖像。在本章的學習過程中,我們會獲取樣本圖像並檢測
其主要特征,然後試著在另一幅圖像中找到與樣本圖像匹配的區域。
我們還將找到樣本圖像和另一幅圖像匹配區域之間的單應性或者空間
關系。
本章將介紹以下主題:
·利用任意一種算法(Harris角點、SIFT、SURF或者ORB)檢測
關鍵點並提取關鍵點周圍的局部描述符。
·使用蠻力算法或者FLANN算法匹配關鍵點。
·使用KNN和比率檢驗過濾糟糕的匹配結果。
·求兩組匹配關鍵點之間的單應性。
·搜索一組圖像,確定哪一幅圖像包含參考圖像的最佳匹配。
我們將通過構建一個“概念–驗證”的司法鑒定應用程序來完成
本章的內容。給定一個文身的參考圖像,我們將搜索一組人的圖像,
以便找出與文身匹配的人。
6.1 技術需求
本章使用了Python、OpenCV以及NumPy。關於OpenCV,我們使用了
可選的opencv_contrib模塊,包括關鍵點檢測和匹配的附加算法。要
啟用SIFT和SURF算法(擁有專利,商業使用不免費),我們必須在
CMake中配置具有OPENCV_ENABLE_NONFREE標志的opencv_contrib模
塊。安裝說明請參閱第1章。此外,如果你還沒有安裝Matplotlib,可
以運行$ pip install matplotlib(或$ pip3 install matplotlib,
取決於環境)安裝Matplotlib。
本章的完整代碼可以在本教程的GitHub庫
(https://github.com/PacktPublishing/Learning-OpenCV-4-
Computer-Vision-with-Python-Third-Edition)的chapter06文件夾
中找到。示例圖像可以在images文件夾中找到。
6.2 理解特征檢測和匹配的類型
有許多算法可以用來檢測和描述特征,本節將探討其中一些算
法。OpenCV中最常用的特征檢測和描述符提取算法如下:
·Harris:該算法適用於角點檢測。
·SIFT:該算法適用於斑點檢測。
·SURF:該算法適用於斑點檢測。
·FAST:該算法適用於角點檢測。
·BRIEF:該算法適用於斑點檢測。
·ORB:它是Oriented FAST和Rotated BRIEF的聯合縮寫。ORB對
於角點和斑點的組合檢測很有用。
可以通過下列方法進行特征匹配:
·蠻力匹配。
·基於FLANN的匹配。
可以通過單應性進行空間驗證。
我們剛剛介紹了很多新的術語和算法。現在,我們來討論它們的
基本定義。
特征定義
究竟什麼是特征?為什麼圖像的某個特定區域可以歸類為特征,
而其他區域則不能分類為特征呢?廣義地說,特征是圖像中獨特或容
易識別的一個感興趣區域。具有高密度紋理細節的角點和區域是好的
特征,而在低密度區域(如藍天)不斷重復出現的模式就不是好的特
征。邊緣是好的特征,因為它們傾向於把圖像分割成兩個區域。斑點
(與周圍區域有很大差別的圖像區域)也是一個有趣的特征。
大多數特征檢測算法都圍繞著角點、邊緣和斑點的識別展開,有
些還關注嶺(ridge)的概念,其中嶺可以概念化為細長物體的對稱
軸。(例如,想象一下識別圖像中的道路。)
有些算法更擅長識別和提取特定類型的特征,所以了解輸入圖像
是什麼很重要,這樣就可以利用OpenCV中的最佳工具了。
6.3 檢測Harris角點
我們首先介紹Harris角點檢測算法。我們通過一個示例來完成角
點檢測任務。如果你在閱讀本教程之後,還繼續學習OpenCV,那麼你會
發現棋盤是計算機視覺分析的一個常見主體,部分原因是棋盤模式適
用於多種類型的特征檢測,還有部分原因是下棋是一種流行的消遣方
式,尤其是在俄羅斯——那裡有許多OpenCV開發人員。
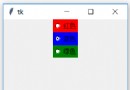
圖6-1是棋盤和棋子的示例圖像。

OpenCV有一個名為cv2.cornerHarris的方便函數,用於檢測圖像
中的角點。在下面的基本示例中,我們可以看一下該函數的工作情
況:

我們來分析一下代碼。常規導入之後,加載棋盤圖像並將其轉換
成灰度圖像。接下來,調用cornerHarris函數:
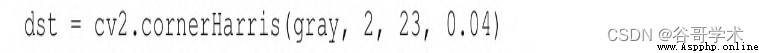 這裡最重要的參數是第3個參數,定義了索貝爾(Sobel)算子的
這裡最重要的參數是第3個參數,定義了索貝爾(Sobel)算子的
孔徑或核大小。索貝爾算子通過測量鄰域像素值之間的水平和垂直差
異來檢測邊緣,並使用核來實現這一任務。cv2.cornerHarris函數使
用的索貝爾算子的孔徑由此參數定義。簡單地說,這些參數定義了角
點檢測的靈敏度。這個參數值必須是在3~31之間的奇數值。對於3這
樣的低值(高靈敏度),棋盤上黑色方格中所有斜線接觸到方格邊界
時,都將記錄為角點。對於23這樣的高值(低靈敏度),只有每個方
格的角才會被檢測為角點。
cv2.cornerHarris返回浮點格式的圖像。該圖像中的每個值表示
源圖像對應像素的一個分值。中等的分值或者高的分值表明像素很可
能是一個角點。相反,分值最低的像素可以視為非角點。考慮下面的
代碼行:
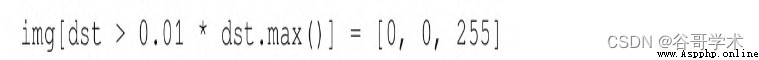
這裡,我們選取的像素的分值至少是最高分值的1%,並在原始圖
像中將這些像素塗成紅色,結果如圖6-2所示。

太棒了!幾乎所有檢測到的角點都標記為紅色。標記的點包括棋
盤方格上幾乎所有的角點。
如果調整cv2.cornerHarris中的第2個參數,我們將看到較小的
區域(對應於較小的參數值)或者較大的區域(對應於較大的參數
值)被檢測為角點。這個參數稱為塊大小。
6.4 檢測DoG特征並提取SIFT描述符
上述技術使用cv2.cornerHarris,能很好地檢測角點且有明顯的
優勢,因為角就是角點,即使旋轉圖像也能檢測到這些角點。但是,
如果將圖像縮放到更小或者更大的尺寸,圖像的某些部分可能丟失或
者獲得高質量的角點。
例如,圖6-3是F1意大利大獎賽賽道的一幅圖像的角點檢測結果。

圖6-4是基於同一幅圖像的一個更小版本的角點檢測結果
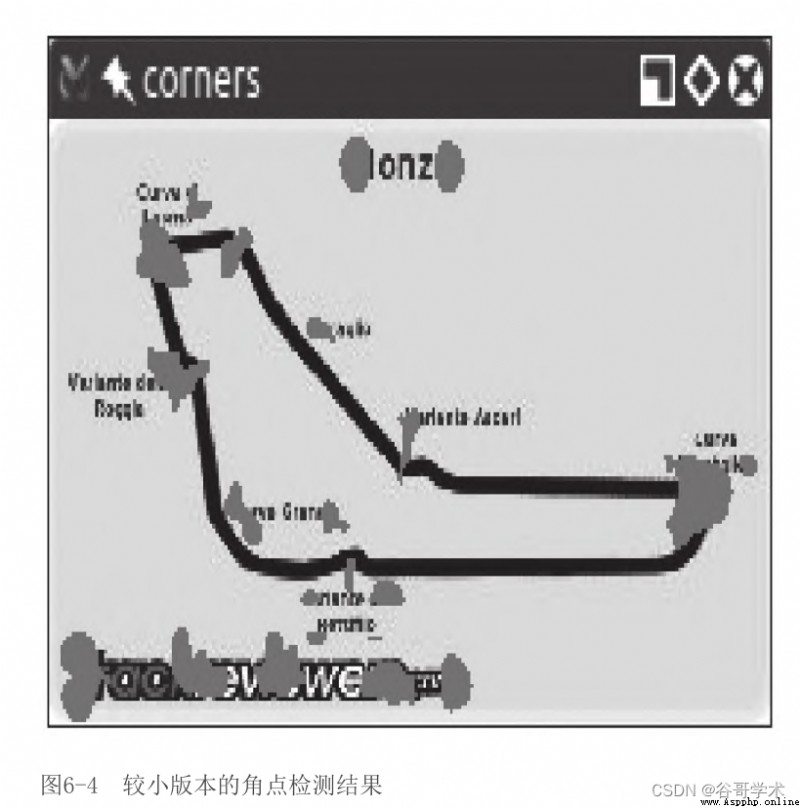
你會注意到角點是如何變得更緊湊的,可是,盡管我們獲得了一
些角點,但是也丟失了一些角點!比如,我們來檢查一下阿斯卡裡
(Variante Ascari)減速彎道,這條位於從西北直到東南的賽道盡頭
的彎道看起來像波形曲線。在大版本的圖像中,雙彎道的入口和頂端
都被檢測為角點。在縮小版本的圖像中,沒有檢測到這樣的頂端。如
果進一步縮小圖像,在某種程度上我們還會丟失彎道入口的角點。
這種特征的丟失引發了一個問題:我們需要一種算法,不管圖像
大小都能工作。於是尺度不變特征變換(Scale-Invariant Feature
Transform,SIFT)登場了。雖然這個名字聽起來有點神秘,但是既然
我們知道了要解決什麼問題,它實際上就是有意義的。我們需要一個
函數(變換)來檢測特征(特征變換),並且不會因圖像尺度的不同
而輸出不同的結果(尺度不變特征變換)。請注意,SIFT不檢測關鍵
點(用高斯差分(Difference of Gaussian,DoG)來完成),而是通
過特征向量描述其周圍的區域。
接下來快速浏覽一下DoG。在第3章中,我們討論過低通濾波器和
模糊運算,特別是cv2.GaussianBlur()函數。DoG是對同一幅圖像應用
不同的高斯濾波器的結果。之前,我們將這類技術應用於邊緣檢測,
這裡的思路也一樣。DoG運算的最終結果包含感興趣區域(關鍵點),
然後通過SIFT進行描述。
我們來看DoG和SIFT在圖6-5中的表現,這幅圖像充滿了角點和特
征。

這裡使用了瓦雷茲(位於意大利的倫巴第)的漂亮全景圖,此圖
在計算機視覺領域作為一個主體而聲名鵲起。下面是生成經過處理的
圖像的代碼:

常規導入後,加載想要處理的圖像。然後,把圖像轉換成灰度圖
像。至此,你可能已經發現OpenCV中的很多方法都需要灰度圖像作為
輸入。下一步是創建SIFT檢測對象,並計算灰度圖像的特征和描述
符:

在後台,這些簡單的代碼行執行了一個復雜的過程:創建一個
cv2.SIFT對象,該對象使用DoG檢測關鍵點,再計算每個關鍵點周圍區
域的特征向量。正如detectAndCompute方法的名字清楚表明的那樣,
該方法主要執行兩項操作:特征檢測和描述符計算。該操作的返回值
是一個元組,包含一個關鍵點列表和另一個關鍵點的描述符列表。
最後,用cv2.drawKeypoints函數在圖像上繪制關鍵點,然後用常
規的cv2.imshow函數對其進行顯示。作為其中一個參數,
cv2.drawKeypoints函數接受一個指定想要的可視化類型的標志。這
裡,我們指定cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINT,以便繪
制出每個關鍵點的尺度和方向的可視化效果。
關鍵點剖析
每個關鍵點都是cv2.KeyPoint類的一個實例,具有以下屬性:
·pt(點)屬性包括圖像中關鍵點的x和y坐標。
·size屬性表示特征的直徑。
·angle屬性表示特征的方向,如前面處理過的圖像中的徑向線所
示。
·response屬性表示關鍵點的強度。由SIFT分類的一些特征比其他
特征更強,response可以評估特征強度。
·octave屬性表示發現該特征的圖像金字塔層。我們簡單回顧一下
5.2節中介紹過的圖像金字塔的概念。SIFT算法的操作方式類似於人臉
檢測算法,迭代處理相同的圖像,但是每次迭代時都會更改輸入。具
體來說,圖像尺度是在算法每次迭代(octave)時都變化的一個參數。
因此,octave屬性與檢測到關鍵點的圖像尺度有關。
·class_id屬性可以用來為一個關鍵點或者一組關鍵點分配自定義
的標識符。
6.5 檢測快速Hessian特征並提取SURF描述符
計算機視覺是計算機科學中相對較新的一個分支,因此許多著名
的算法和技術都是最近才出現的。實際上,SIFT是在1999年由David
Lowe發布的,才只有20多年的歷史。
SURF是在2006年由Herbert Bay發布的一種特征檢測算法。SURF要
比SIFT快幾倍,而且是受到了SIFT的啟發。
請注意,SIFT和SURF都是授權專利算法,因此,只有在
opencv_contrib構建中使用了OPENCV_ENABLE_NONFREE CMake標
志時才可用。
對於本教程來說,了解SURF的工作原理並不是特別重要,我們可以
將其應用到應用程序中並對其進行充分利用。重要的是理解cv2.SURF
是一個OpenCV類,用快速Hessian算法進行關鍵點檢測,並用SURF進行
描述符提取,就像cv2.SIFT類一樣(用DoG進行關鍵點檢測,用SIFT進
行描述符提取)。
此外,好消息是OpenCV為它所支持的所有特征檢測和描述符提取
算法提供了標准的API。因此,只需要做一些細微的改變,就可以修改
前面的代碼示例來使用SURF(而不是SIFT)。下面是修改後的代碼,
修改部分用粗體表示:

cv2.xfeatures2d.SURF_create的參數是快速Hessian算法的一個
阈值。通過增加阈值,可以降低保留下來的特征數量。阈值為8000
時,得到的結果如圖6-6所示。

試著調整阈值,看看阈值對結果的影響。作為練習,你可能希望
構建帶有控制阈值的滑塊的GUI應用程序。通過這種方式,用戶可以調
整阈值,查看以反比的形式增加和減少的特征數量。在4.7節中,我們
構建了一個帶有滑塊的GUI應用程序,因此可以參考那部分內容。
接下來,我們將研究FAST角點檢測器、BRIEF關鍵點描述符和
ORB(把FAST和BRIEF結合在一起使用)。
6.6 使用基於FAST特征和BRIEF描述符的ORB
如果說SIFT還很年輕,SURF更年輕,那麼ORB就還處於嬰兒期。
ORB首次發布於2011年,作為SIFT和SURF的一個快速代替品。
該算法發表在論文“ORB:an efficient alternative to SIFT or
SURF”上,可以在
http://www.willowgarage.com/sites/default/files/orb_final.pdf
處找到PDF格式的論文。
ORB融合了FAST關鍵點檢測器和BRIEF關鍵點描述符,所以有必要
先了解一下FAST和BRIEF。接下來,我們將討論蠻力匹配(用於特征匹
配的算法)並舉一個特征匹配的例子。
6.6.1 FAST
加速分割測試的特征(Feature from Accelerated Segment
Test,FAST)算法是通過分析16個像素的圓形鄰域來實現的。FAST算
法把鄰域內每個像素標記為比特定阈值更亮或更暗,該阈值是相對於
圓心定義的。如果鄰域包含若干標記為更亮或更暗的一系列連續像
素,那麼這個鄰域就被視為角點。
FAST還使用了一種高速測試,有時可以通過只檢查2個或者4個像
素(而不是16個像素)來確定鄰域不是角點。要了解這個測試如何工
作,我們來看一下圖6-7(選自OpenCV文檔)。

在圖6-7中兩個不同的放大倍數下,我們可以看到一個16像素的鄰
域。位於1、5、9和13處的像素對應於圓形鄰域邊緣的4個方位基點。
如果鄰域是一個角點,那麼預計在這4個像素中,剛好有3個像素或者1
個像素比阈值亮。(另一種說法是剛好有1個或者3個像素比阈值
暗。)如果其中剛好有2個比阈值亮,那麼該領域是一條邊,而不是一
個角點。如果其中剛好有4個或者0個比阈值亮,那麼該領域相對一
致,既不是角點也不是邊。
FAST是一個智能算法,但是它並不是沒有缺點,為了彌補這些缺
點,從事圖像分析的開發人員可以實現一種機器學習算法,以便為算
法提供一組(與給定應用程序相關的)圖像,從而優化阈值等參數。
不管開發人員是直接指定參數,還是為機器學習方法提供一個訓練
集,FAST都是對輸入很敏感的一種算法,也許比SIFT更敏感。
6.6.2 BRIEF
另外,二值魯棒獨立基本特征(Binary Robust Independent
Elementary Feature,BRIEF)並非特征檢測算法,而是一個描述符。
我們來更深入地研究一下描述符的概念,然後再來研究BRIEF。
在前面用SIFT和SURF分析圖像時,整個過程的核心是調用
detectAndCompute函數。此函數執行兩個不同的步驟——檢測和計
算,它們返回2個不同的結果(耦合到一個元組中)。
檢測結果是一組關鍵點,計算結果是這些關鍵點的一組描述符。
這意味著OpenCV的cv2.SIFT和cv2.SURF類都實現了檢測和描述算法。
請記住,原始的SIFT和SURF不是特征檢測算法。OpenCV的cv2.SIFT實
現了DoG特征檢測和SIFT描述,而OpenCV的cv2.SURF實現了快速
Hessian特征檢測和SURF描述。
關鍵點描述符是圖像的一種表示,充當特征匹配的通道,因為你
可以比較兩幅圖像的關鍵點描述符並發現它們的共性。
BRIEF是目前最快的描述符之一。BRIEF背後的理論相當復雜,但
是可以這樣說,BRIEF采用一系列優化,使其成為特征匹配的一個非常
好的選擇。
6.6.3 蠻力匹配
蠻力匹配器是一個描述符匹配器,它比較兩組關鍵點描述符並生
成匹配列表。之所以稱為蠻力匹配,是因為在該算法中幾乎不涉及優
化。對於第一個集合中的每個關鍵點描述符,匹配器將之與第二個集
合中的每個關鍵點描述符進行比較。每次比較產生一個距離值,並基
於最小距離選擇最佳匹配。
概括地說,在計算中,“蠻力”一詞是指將所有可能組合(例
如,破解已知長度密碼的所有可能的字符組合)的窮舉按優先級排序
的方法。相反,優先考慮速度的算法可能會跳過一些可能性,並試圖
走一條捷徑來找到看似最合理的解決方案。
OpenCV提供了一個cv2.BFMatcher類,支持幾種蠻力特征匹配的方
法。
6.6.4 匹配兩幅圖像中的標識
既然我們已經大致了解了什麼是FAST和BRIEF,我們就可以理解為
什麼ORB背後的團隊(由Ethan Rublee、Vincent Rabaud、Kurt
Konolige和Gary R.Bradski組成)選擇這兩種算法作為ORB的基礎了。
在其論文中,作者的目標是實現以下結果:
·為FAST增加一個快速且准確的定位組件。
·面向BRIEF特征的高效計算。
·面向BRIEF特征的方差和相關性分析。
·在旋轉不變性下去相關BRIEF特征的一種學習方法,在最近鄰應
用中產生更好的性能。
要點很清晰:ORB的目標是優化和加速操作,包括非常重要的以旋
轉感知的方式利用BRIEF的步驟,這樣匹配就得以改善,即使在訓練圖
像與查詢圖像有非常不同的旋轉狀態的情況下也是如此。
不過,在這個階段,你可能已經了解了足夠的理論,希望深入研
究一些特征匹配,我們來看一些代碼。下面的腳本試圖將標識中的特
征與包含該標識的照片中的特征進行匹配:

我們一步一步地查看這段代碼。在通常的導入語句之後,我們以
灰度格式加載兩幅圖像(查詢圖像和場景)。圖6-8是查詢圖像,它是
美國國家航空航天局標識。圖6-9是肯尼迪航天中心的照片。


現在,我們繼續創建ORB特征檢測器和描述符:
 與使用SIFT和SURF的方式類似,我們檢測並計算這兩幅圖像的關
與使用SIFT和SURF的方式類似,我們檢測並計算這兩幅圖像的關
鍵點和描述符。
從這裡開始,概念非常簡單:遍歷描述符並確定是否匹配,然後
計算匹配的質量(距離),並對匹配進行排序,這樣就可以在一定程
度上顯示前n個匹配,它們實際上匹配了兩幅圖像上的特征。
cv2.BFMatcher可以實現這一任務:

在此階段,我們已經有了需要的所有信息,但是作為計算機視覺
愛好者,我們非常重視數據的可視化表示,所以我們在matplotlib圖
表中繪制這些匹配:

Python的切片語法非常健壯。如果matches列表中包含的項少
於25個,那麼matches[:25]切片命令將正常運行,並提供與原始列表包含
同樣多元素的列表。
匹配結果如圖6-10所示。
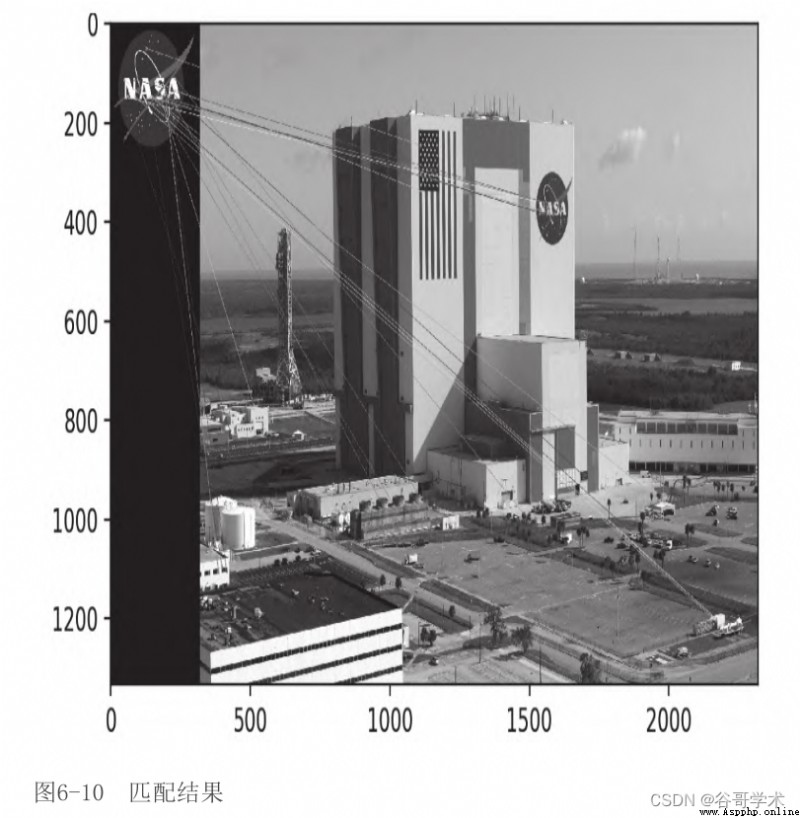
你可能會認為這是一個令人失望的結果。實際上,我們可以看到
大多數匹配都是假匹配。不幸的是,這很典型。為了改善匹配結果,
我們需要應用其他技術來過濾糟糕的匹配。接下來我們將把注意力轉
向這項任務。
6.7 使用K最近鄰和比率檢驗過濾匹配
想象一下,一大群知名哲學家邀請你評判他們關於對生命、宇宙
和一切事物都很重要的一個問題的辯論。在每位哲學家輪流發言時,
你都會認真聽。最後,在所有哲學家都發表完他們所有的論點時,你
浏覽筆記,會發現以下兩件事:
·每位哲學家都不贊同其他哲學家的觀點。
·沒有哲學家比其他哲學家更有說服力。
根據最初的觀察,你推斷最多只有一位哲學家的觀點是正確的,
但事實上,也有可能所有哲學家的觀點都是錯誤的。然後,根據第二
次觀察,即使其中一位哲學家的觀點是正確的,你也會開始擔心可能
會選擇一個觀點錯誤的哲學家。不管你怎麼看,這些人都會讓你的晚
宴遲到。你稱其為平局,並說辯論中仍有最重要的問題尚未解決。
我們可以對判斷哲學家辯論的假想問題與過濾糟糕關鍵點匹配的
實際問題進行比較。
首先,假設查詢圖像中的每個關鍵點在場景中最多有一個正確的
匹配。也就是說,如果查詢圖像是NASA標識,那麼就假定另一幅圖像
(場景)最多包含一個NASA標識。假設一個查詢關鍵點最多有一個正
確或者良好的匹配,那麼在考慮所有可能的匹配時,我們主要觀察糟
糕的匹配。因此,蠻力匹配器計算每個可能匹配的距離分值,可以提
供大量的對糟糕匹配的距離分值的觀察。與無數糟糕的匹配相比,我
們期望良好的匹配會有明顯更好(更低)的距離分值,因此糟糕的匹
配分值可以幫助我們為針對良好的匹配選擇一個阈值。這樣的阈值不
一定能很好地推廣到不同的查詢關鍵點或者不同的場景,但是至少在
具體案例上會有所幫助。
現在,我們來考慮修改後的蠻力匹配算法的實現,該算法以上述
方式自適應地選擇距離阈值。在上一節的示例代碼中,我們使用
cv2.BFMatcher類的match方法來獲得包含每個查詢關鍵點的單個最佳
匹配(最小距離)的列表。這樣的實現丟棄了有關所有可能的糟糕匹
配的距離分值的信息,而這類信息是自適應方法所需要的。幸運的
是,cv2.BFMatcher還提供了knnMatch方法,該方法接受一個參數k,
可以指定希望為每個查詢關鍵點保留的最佳(最短距離)匹配的最大
數量。(在某些情況下,得到的匹配數可能比指定的數量最大值更
少。)KNN表示K最近鄰(K-Nearest Neighbor)。
我們會使用knnMatch方法為每個查詢關鍵點請求兩個最佳匹配的
列表。基於每個查詢關鍵點至多有一個正確匹配的假設,我們確信次
優匹配是錯誤的。次優匹配的距離分值乘以一個小於1的值,就可以獲
得阈值。
然後,只有當距離分值小於阈值時,才將最佳匹配視為良好的匹
配。這種方法被稱為比率檢驗(ratio test),最先是由David
Lowe(SIFT算法的作者)提出來的。他在論文“Distinctive Image
Features from Scale-Invariant Keypoints”(網址為
https://www.cs.ubc.cs/~lowe/papers/ijcv04.pdf)中描述了比率檢
驗。具體來說,在“Application to object recognition”部分,他
聲明如下:
一個匹配正確的概率可以根據最近鄰到第2近鄰的距離比例來確
定。
我們可以用與前面代碼示例相同的方式加載圖像、檢測關鍵點,
並計算ORB描述符。然後,使用下面兩行代碼執行蠻力KNN匹配:

knnMatch返回列表的列表,每個內部列表至少包含一個匹配項,
且不超過k個匹配項,各匹配項從最佳(最短距離)到最差依次排序。
下列代碼行根據最佳匹配的距離分值對外部列表進行排序:

我們來畫出前25個最佳匹配,以及knnMatch可能與之配對的所有
次優匹配。不能使用cv2.drawMatches函數,因為該函數只接受一維匹
配列表,相反,必須使用cv2.drawMatchesKnn。下面的代碼用來選
擇、繪制,並顯示匹配:

到目前為止,我們還沒有過濾掉所有糟糕的匹配——實際上,還
故意包含了我們認為是糟糕的次優匹配——因此,結果看起來有點
亂,如圖6-11所示。
現在,我們來應用比率檢驗,把阈值設置為次優匹配距離分值的
0.8倍。如果knnMatch無法提供次優匹配,那麼就拒絕最佳匹配,因為
無法對其應用檢驗。下面的代碼應用了這些條件,並提供通過測試的
最佳匹配列表:

應用比率檢驗後,只需處理最佳匹配(而非最佳和次優匹配
對),這樣就可以用cv2.drawMatches(而非cv2.drawMatchesKnn)對
其進行繪制。同樣,從列表中選擇前25個匹配項。下面的代碼用於選
擇、繪制,並顯示匹配項:

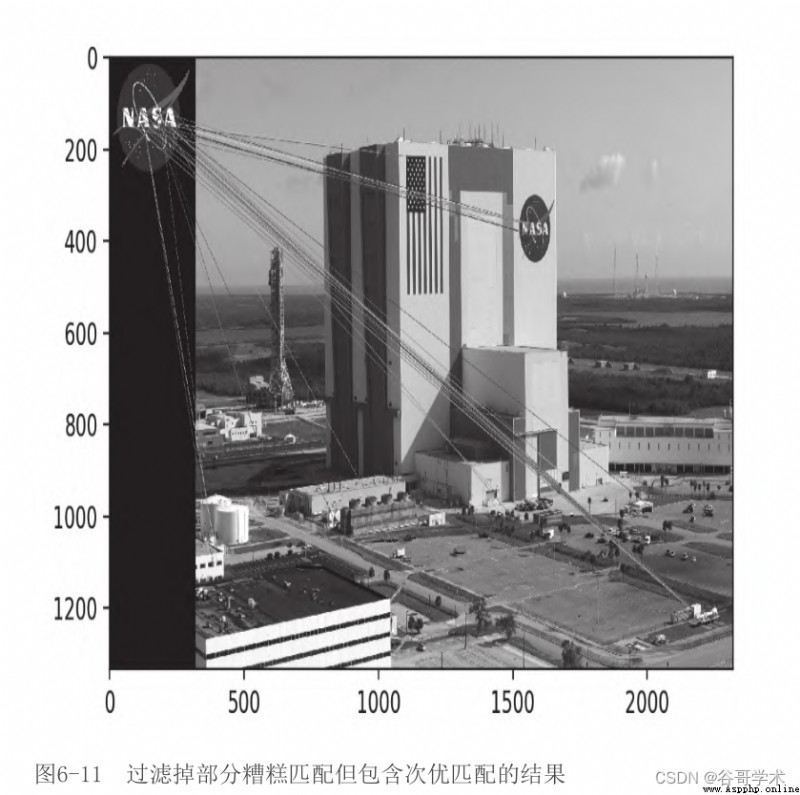
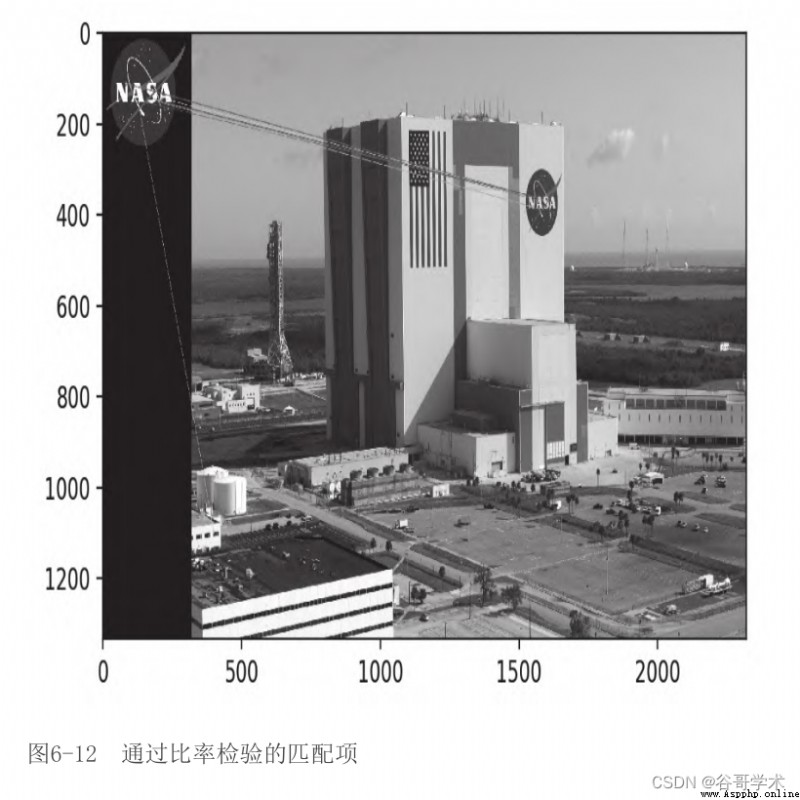
在圖6-12中,我們可以看到通過比率檢驗的匹配項。
將此輸出圖像與上一節中的輸出圖像進行比較,可以看到使用KNN
和比率檢驗可以過濾掉很多糟糕的匹配項。剩余的匹配項並不完美,
但是幾乎所有的匹配項都指向了正確的區域——肯尼迪航天中心一側
的NASA標識。
我們有了一個良好的開始。接下來,我們將用名為FLANN的更快的
匹配器來代替蠻力匹配器。在此之後,我們將學習如何根據單應性描
述一組匹配,即表示匹配對象的位置、旋轉角度、比例以及其他幾何
特征的二維變換矩陣。
6.8 基於FLANN的匹配
FLANN代表快速近似最近鄰庫(Fast Library for Approximate
Nearest Neighbor),是2條款BSD許可下的一個開源庫。FLANN的官方
網站是http://www.cs.ubc.ca/research/flann/。以下內容摘自該網
站:
FLANN是在高維空間執行快速近似最近鄰搜索的一個庫,包含最
適合最近鄰搜索的一個算法集,以及根據數據集自動選擇最佳算法和
最優參數的一個系統。
FLANN是用C++編寫的,包含C、MATLAB和Python等語言的綁
定。
或者說,FLANN有一個很大的工具箱,知道如何根據任務選擇好的
工具,而且會幾種語言。這些特性使庫更方便、快捷。事實上,FLANN
的作者聲稱:對於很多數據集來說,FLANN比其他最近鄰搜索軟件要快
10倍。
作為一個獨立的庫,FLANN可以在GitHub平台
(https://github.com/mariusmuja/flann/)上找到。但是,我們會
將FLANN作為OpenCV的一部分來使用,因為OpenCV為其提供了一個方便
的封裝包。
要開始FLANN匹配的實際示例,需先導入NumPy、OpenCV和
Matplotlib,並從文件加載兩幅圖像。下面是相關代碼:
圖6-13是腳本加載的第一幅圖像(查詢圖像)。
這件藝術作品是保羅·高更(Paul Gauguin)於1889年創作完成
的Entre les lys(Among the lilies)。我們將在包含多幅高更作品
以及本教程一位作者所畫的一些隨意形狀的更大圖像(見圖6-14)中搜
索匹配關鍵點。
在大圖像內,Entre les lys位於第3行第3列。查詢圖像和大圖像
中對應區域不一致,它們用略微不同的顏色和不同的尺度描繪了Entre
les lys。盡管如此,對於我們的匹配器來說,這應該是一種比較簡單
的情況。
我們使用cv2.SIFT類來檢測必要的關鍵點,並提取特征:



到目前為止,代碼看起來應該很熟悉,因為本章的前幾節已專門
討論過SIFT以及其他描述符。在前面的示例中,我們將描述符送入
cv2.BFMatcher,用於蠻力匹配。這次,我們將使用
cv2.FlannBasedMatcher。下列代碼使用自定義參數執行基於FLANN的
匹配:

可以看到,FLANN匹配器接受2個參數:indexParams對象和
searchParams對象。這些參數以Python中字典(和C++中結構體)的形
式傳遞,確定FLANN內部用於計算匹配的索引和搜索對象的行為。我們
選擇的參數提供了精度和處理速度之間的合理平衡。具體來說,我們
使用了包含5棵樹的核密度樹(kernel density tree,kd-tree)索引
算法,FLANN可以並行處理此算法。FLANN文檔建議在1棵樹(不提供並
行性)和16棵樹(如果系統可以利用的話,那麼就可以提供高度的並
行性)之間進行選擇。
我們對每棵樹執行50次檢查或者遍歷。檢查次數越多,可以提供
的精度也越高,但是計算成本也就更高。
在進行基於FLANN的匹配之後,我們應用乘數為0.7的勞氏比率檢
驗。為了展示不同的編碼風格,與上一節的代碼示例相比,我們將以
一種稍有不同的方式使用比率檢驗的結果。之前,我們組建了一個新
的列表,其中只包含好的匹配項。這次,我們將組建名為
mask_matches的列表,其中每個元素都是長度為k(與傳給knnMatch的
k是一樣的)的子列表。如果匹配成功,則將子列表中對應的元素設為
1,否則將其設置為0。
例如,如果mask_matches=[[0,0],[1,0]],這意味著有兩個匹配
的關鍵點:對於第一個關鍵點,最優和次優匹配項都是糟糕的;而對
於第二個關鍵點,最佳匹配是好的,次優匹配是糟糕的。請注意,我
們假設了所有次優匹配都是糟糕的。使用下列代碼來應用比率檢驗,
並建立掩模:

現在是繪制並顯示良好匹配項的時候了。把mask_matches列表傳
遞給cv2.drawMatchesKnn作為可選參數,如下列代碼段中粗體所示:


cv2.drawMatchesKnn只繪制掩模中標記為好的匹配(值為1)。腳
本生成的基於FLANN匹配的可視化結果如圖6-15所示。
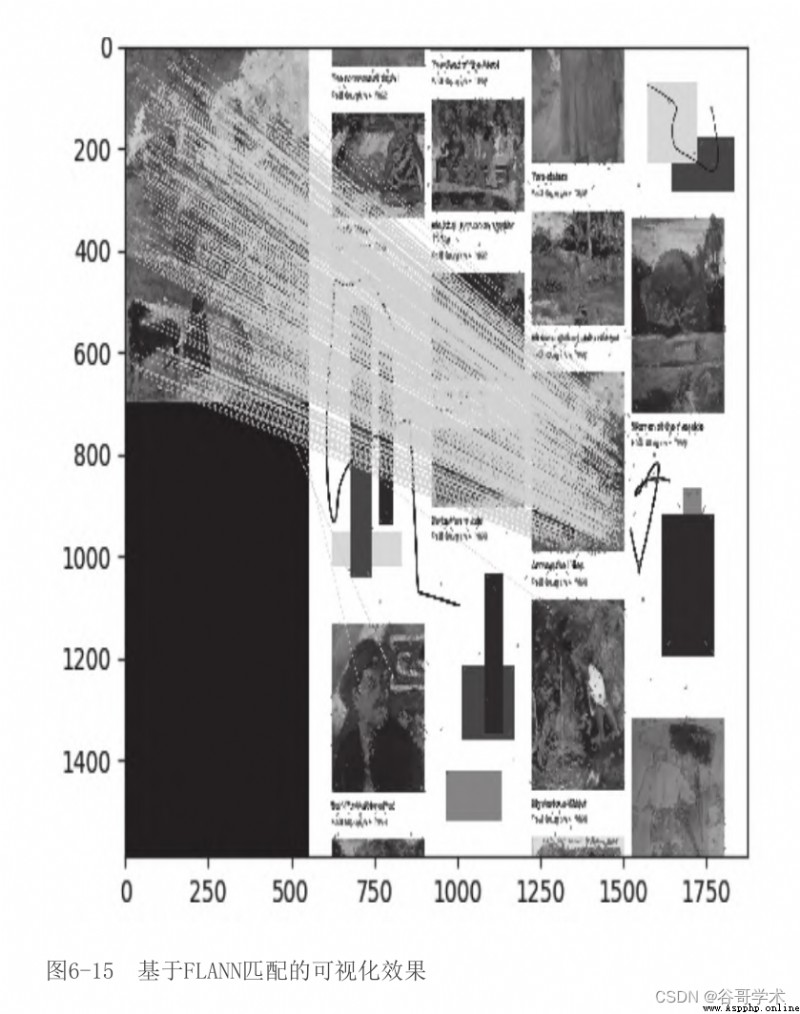
結果令人鼓舞:看上去幾乎所有的匹配項都處於正確的位置。接
下來,我們試著把這種類型的結果簡化為更簡潔的幾何表示——單應
性,它將描述整個匹配對象的姿態,而不是一堆不連續的匹配點。
6.9 基於FLANN進行單應性匹配
首先,什麼是單應性(homography)?來自網絡的一個定義是:
兩張圖之間的一種關系,一張圖的任意一點與另一張圖的一個點
相對應,反之亦然。因此,在圓上滾動的一條切線將圓的兩條固定切
線切成兩組同形點。
如果你像本教程的作者一樣對前面的定義並不了解,你可能會發現
下面的解釋可能更清楚一些:單應性是當一張圖是另一張圖的一個透
視畸變時,在兩張圖中尋找彼此的一種情況。
首先,我們來看想要實現什麼,這樣就可以完全理解什麼是單應
性。然後,再檢查代碼。
假設,我們想搜索圖6-16中的文身。
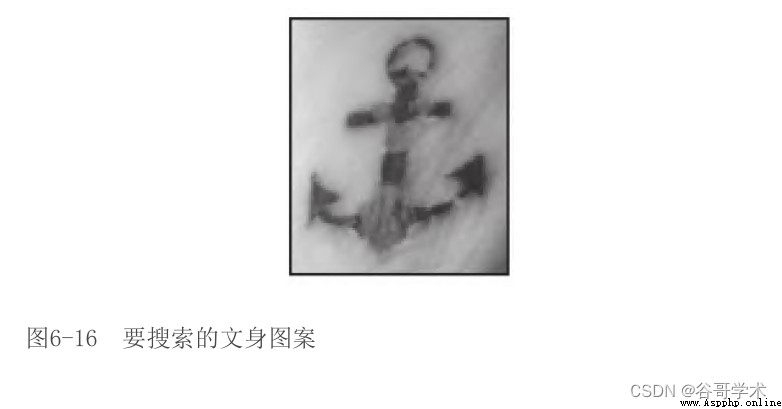
對於我們人來說,很容易在圖6-17中找到文身,盡管存在一些旋
轉角度上的不同。

作為計算機視覺領域的一個練習,我們想要編寫一個腳本生成以
下關鍵點匹配和單應性可視化結果,如圖6-18所示。
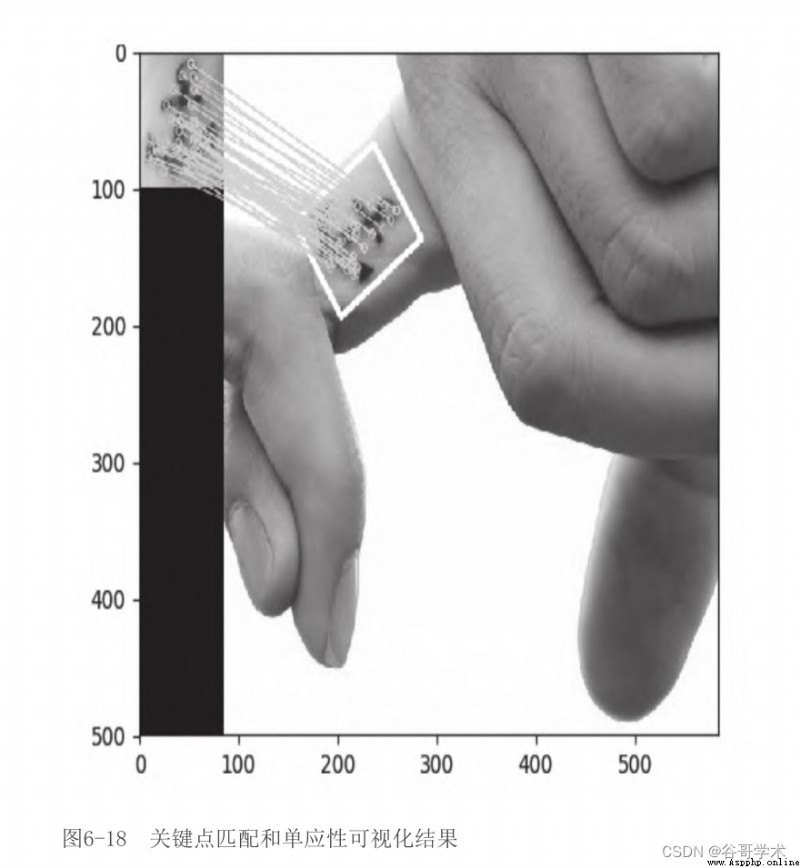
在圖6-18中,我們在第一張圖中選取了主體,在第二張圖中正確
地識別了主體,在關鍵點之間繪制了匹配線,甚至在第二張圖中畫了
一個白色邊框,顯示相對於第一張圖的主體透視畸變。
你可能已經猜到了,腳本的實現從導入庫開始,讀取灰度格式的
圖像,檢測特征並計算SIFT描述符。我們在前面的例子中完成過了所
有這些內容,因此這裡不再重復。我們來看接下來做些什麼吧!
(1)我們組建一個通過了勞氏比率檢驗的匹配列表,代碼如下:

(2)從技術上講,我們最少可以用4個匹配項來計算單應性。但
是,如果這4個匹配項中的任意一個有缺陷,都將會破壞結果的准確
性。實際中最少用到10個匹配項。對於額外的匹配項,單應性查找算
法可以丟棄一些異常值,以便產生與大部分匹配項子集緊密匹配的結
果。因此,我們繼續檢查是否至少有10個好的匹配項:

(3)如果滿足這個條件,那麼就查找匹配的關鍵點的二維坐標,
並把這些坐標放入浮點坐標對的兩個列表中。一個列表包含查詢圖像
中的關鍵點坐標,另一個列表包含場景中匹配的關鍵點坐標:

(4)尋找單應性:

請注意,我們創建了mask_matches列表,將用於最終的匹配繪
制,這樣只有滿足單應性的點才會繪制匹配線。
(5)在這個階段,必須執行一個透視轉換,取查詢圖像的矩形角
點,並將其投影到場景中,這樣就可以畫出邊界:


然後,繼續繪制關鍵點並顯示可視化效果,正如前面的例子那
樣。
6.10 示例應用程序:文身取證
我們以一個實際生活(或者幻想生活)中的例子來結束這一章。
假設你在某市法醫部門工作,需要鑒定一個文身。你有罪犯文身的原
始圖片(可能是在閉路電視錄像中拍攝到的),但是不知道這個人的
身份。可是,你擁有一個文身數據庫,它以文身所屬人的名字為索
引。
我們把這個任務分成兩部分:
·通過將圖像描述符保存到文件中來構建數據庫。
·加載數據庫並掃描查詢圖像的描述符和數據庫中描述符之間的
匹配項。
在接下來的兩個小節中,我們將介紹這些任務。
6.10.1 將圖像描述符保存到文件
我們要做的第一件事情是將圖像描述符保存到外部文件。這樣,
我們就不必在每次掃描兩個要匹配的圖像時都重新創建描述符。
就本示例而言,我們掃描一個圖像文件夾,並創建對應的描述符
文件,這樣在未來的搜索中就可以隨時使用這些內容。要創建描述
符,我們將使用本章已經多次使用過的方法:加載圖像、創建特征檢
測器、檢測特征並計算描述符。要將描述符保存到文件,我們將使用
名為save的NumPy數組的便利方法,以優化的方式將數組數據轉儲到文
件中。
在Python標准庫中,pickle模塊提供了更通用的序列化功能,
支持任何Python對象,不僅僅是NumPy數組。可是,NumPy的數組序列
化對於數字數據來說是一個很好的選擇。
我們將腳本分解為函數。主函數將被命名為
create_descriptors,它將遍歷給定文件夾中的文件。對於每個文
件,create_descriptors將調用名為create_descriptor的輔助函數,
該函數將計算並保存給定圖像文件的描述符。
(1)首先,create_descriptors的實現如下:


注意,create_descriptors創建了特征檢測器,因為我們只需要
創建一次,而不是每次加載文件時都要創建。輔助函數
create_descriptor接收特征檢測器作為參數。
(2)現在,我們來看輔助函數的實現:

注意,我們將描述符文件保存在與圖像相同的文件夾中。此外,
我們假設圖像文件具有png擴展名。為了使腳本更加魯棒,可以對其進
行修改,使腳本支持額外的圖像文件擴展名,如jpg。如果文件有一個
意想不到的擴展名,就跳過它,因為它可能是描述符文件(來自之前
的腳本運行)或其他非圖像文件。
(3)我們已經完成了函數的實現。為了完成腳本,我們將調用
create_descriptors,用文件夾名稱作為參數:

運行這個腳本時,它將生成NumPy數組文件格式的必要描述符文
件,文件擴展名為npy。這些文件構成了文身描述符數據庫,按名字索
引。(每個文件名都是一個人名。)接下來,我們將編寫一個獨立的
腳本,這樣就可以對數據庫進行查詢了。
6.10.2 掃描匹配
既然已經將描述符保存到文件,我們只需要對每個描述符集執行
匹配,以確定哪個集合最匹配查詢圖像。
以下是將實施的過程:
(1)加載查詢圖像(query.png)。
(2)掃描包含描述符文件的文件夾。打印描述符文件的名稱。
(3)為查詢圖像創建SIFT描述符。
(4)對於每個描述符文件,加載SIFT描述符,並搜索基於FLANN
的匹配項。基於比率檢驗過濾匹配。打印這個人的名字和匹配項的數
量。如果匹配項的數量超過了任意阈值,則打印“此人是嫌疑人”。
(請記住,我們在調查一起犯罪活動。)
(5)打印主要嫌疑人的名字(匹配次數最多的那個人)。
我們來考慮其實現:
(1)首先,用下面的代碼塊加載查詢圖像:

(2)匯編並打印描述符文件列表:

(3)建立典型的cv2.SIFT和cv2.FlannBasedMatcher對象,並且
生成查詢圖像的描述符:

(4)尋找嫌疑人,將嫌疑人定義為至少有10個與查詢文身良好匹
配的人。搜索過程包括遍歷描述符文件、加載描述符、執行基於FLANN
的匹配,以及基於比率檢驗過濾匹配項。打印每個人(每個描述符文
件)的匹配結果:

注意np.load方法的用法,它將指定的NPY文件加載到NumPy
數組中。
(5)最後,打印主要嫌疑人的名字(如果找到了嫌疑人的話):

運行上述腳本,產生的輸出如下:
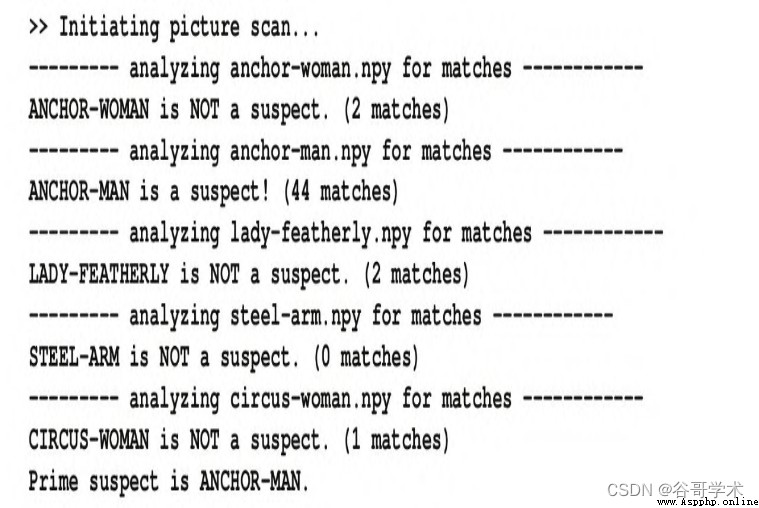
如果願意,就像在前一節中所完成的那樣,也可以用圖形表示匹
配項和單應性。
6.11 本章小結
本章中,我們介紹了關鍵點檢測、關鍵點描述符的計算、描述符
的匹配、糟糕匹配的過濾,以及兩組匹配關鍵點之間單應性的尋找。
我們討論了OpenCV中可用於完成上述任務的一些算法,並將這些算法
應用到各種圖像和用例中。
如果把關於關鍵點的新知識和攝像頭以及透視的知識相結合,我
們就能夠跟蹤三維空間中的物體。這將是第9章的主題。如果你非常渴
望進入三維領域,那麼可以先跳到第9章進行學習。
相反,如果你認為接下來的內容對於你完善有關物體檢測、識別
以及跟蹤的二維解決方案的知識有幫助,那麼可以繼續學習第7章和第
8章的內容。最好了解一下二維和三維組合技術,這樣就可以選擇為給
定應用程序提供正確輸出類型和恰當計算速度的方法。