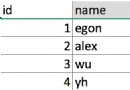
Redis 支持5種數據類型:
1.String 字符串數據類型
String 是最常用的一種數據類型,普通的 key/value 存儲都可以歸為此類,即可以完全實現目前 Memcached 的功能,並且效率更高。
還可以享受 Redis 的定時持久化,操作日志及 Replication 等功能。
2.Hash哈希數據類型
Redis hash 是一個鍵值(key => value)對集合。
Redis hash 是一個 string 類型的 field 和 value 的映射表,hash 特別適合用於存儲對象。
舉個實例來描述下 hash 的應用場景,比如我們要存儲一個用戶信息對象數據,就可以使用 Redis hash。
3.List數據類型
Redis list 列表是簡單的字符串列表,按照插入順序排序。你可以添加一個元素到列表的頭部(左邊)或者尾部(右邊)。
Redis list 的應用場景非常多,也是 Redis 最重要的數據結構之一。
比如 twitter 的關注列表,粉絲列表等都可以用 Redis 的 list 結構來實現。
4.Set 數據類型
Redis set 是 string 類型的無序集合。集合是通過 hashtable 實現的,概念和數學中的集合基本類似,可以交集,並集,差集等等,set中的元素是沒有順序的。
Redis set 對外提供的功能與 list 類似是一個列表的功能,特殊之處在於 set 是可以自動排重的。
當你需要存儲一個列表數據,又不希望出現重復數據時,set 是一個很好的選擇,並且 set 提供了判斷某個成員是否在一個 set 集合內的重要接口,這個也是 list 所不能提供的。
5.zset 有序集合數據類型
Redis zset 和 set 一樣也是 string 類型元素的集合,且不允許重復的成員。
zadd 命令:添加元素到集合,元素在集合中存在則更新對應score。
Redis sorted set 的使用場景與 set 類似,區別是 set 不是自動有序的,而 sorted set 可以通過用戶額外提供一個優先級(score)的參數來為成員排序,並且是插入有序的,即自動排序。
import redis
#使用連接池方式連接redis
redis_pool=redis.ConnectionPool(host="127.0.0.1",port=6379,db=15,decode_responses=True)
redis_conn=redis.Redis(connection_pool=redis_pool)
#2.1 String字符串
#字符串數據類型的相關命令用於管理 redis 字符串值
#設置指定 key 的值
redis_conn.set("name","tony")
redis_conn.set("age",33)
redis_conn.set('strtest','{"addr":"北京good","phone":13300000000}')
#Setnx(SET if Not eXists) 命令在指定的 key 不存在時,為 key 設置指定的值
redis_conn.setnx("job","computer")
#獲取指定 key 的值
print(redis_conn.get('name'))
print(redis_conn.get('age'))
print(redis_conn.get('strtest'))
#Incr 命令將 key 中儲存的數字值增一
# 如果 key 不存在,那麼 key 的值會先被初始化為 0 ,然後再執行 INCR 操作
# 如果值包含錯誤的類型,或字符串類型的值不能表示為數字,那麼返回一個錯誤
print(redis_conn.incr("age"))
# Decr 命令將 key 中儲存的數字值減一
# 如果 key 不存在,那麼 key 的值會先被初始化為 0 ,然後再執行 DECR 操作
# 如果值包含錯誤的類型,或字符串類型的值不能表示為數字,那麼返回一個錯誤
print(redis_conn.decr("age"))
print(redis_conn.get("job"))
#Strlen 命令用於獲取指定 key 所儲存的字符串值的長度。當 key 儲存的不是字符串值時,返回一個錯誤
print(redis_conn.strlen("strtest"))
print("*"*10)
#2.2 Hash哈希
#hash 是一個 string 類型的 field(字段) 和 value(值) 的映射表,hash 特別適合用於存儲對象。
#Hmget 命令用於返回哈希表中,一個或多個給定字段的值
redis_conn.hset('myhash','f1','v1')
redis_conn.hset('myhash','f2','v2')
#Hget 命令用於返回哈希表中指定字段的值,如果給定的字段或 key 不存在時,返回 None
print(redis_conn.hget("myhash","testhash"))
print(redis_conn.hmget('myhash','f1','f2'))
#Hgetall 命令用於返回哈希表中,所有的字段和值
redis_conn.hset("hashstrtest","student2",'idcard:123456,sex:man,age:33')
print(redis_conn.hgetall("hashstrtest"))
# Hmset 命令用於同時將多個 field-value (字段-值)對設置到哈希表中
redis_conn.hmset('hashjsontest', {'student3': '{"perform": "game","num":123456789}'})
redis_conn.hmset('jsontest',{"id":1,"name":"張三豐","birth":"2000-07-07","age":17,"clazz":"一年1班","createTm":1504856483000})
print(redis_conn.hgetall("hashjsontest"))
print(redis_conn.hgetall("jsontest"))
#獲取所有哈希表中的字段
print(redis_conn.hkeys("jsontest"))
#Hvals 命令返回哈希表所有的值
print(redis_conn.hvals("jsontest"))
#獲取哈希表中字段的數量
print(redis_conn.hlen("jsontest"))
print("*"*20)
#2.3 List列表
# 是簡單的字符串列表,按照插入順序排序。你可以添加一個元素到列表的頭部(左邊)或者尾部(右邊
# 將一個或多個值插入到列表頭部
redis_conn.lpush("teachkey","redis")
redis_conn.lpush("teachkey","mysql")
redis_conn.lpush("teachkey","mongodb")
redis_conn.lpush("teachkey","mq")
redis_conn.lpush("teachkey","job")
#獲取列表指定范圍內的元素
print(redis_conn.lrange('teachkey',1,10))
#Lindex 命令用於通過索引獲取列表中的元素。你也可以使用負數下標,以 -1 表示列表的最後一個元素, -2 表示列表的倒數第二個元素,以此類推
#列表中下標為指定索引值的元素。 如果指定索引值不在列表的區間范圍內,返回None
print(redis_conn.lindex("teachkey",-1))
#獲取列表長度
print(redis_conn.llen("teachkey"))
#移出並獲取列表的第一個元素
print(redis_conn.lpop("teachkey"))
#將一個或多個值插入到列表頭部
print(redis_conn.lpush("teachkey","goodjob"))
print(redis_conn.lrange('teachkey',1,10))
print("*"*30)
#2.4 Set集合
#Set是 String 類型的無序集合。集合成員是唯一的,這就意味著集合中不能出現重復的數據。
#向集合添加一個或多個成員
redis_conn.sadd('lovekey','booking')
redis_conn.sadd('lovekey','booking')
redis_conn.sadd('lovekey','eating')
redis_conn.sadd('lovekey','runing')
redis_conn.sadd('lovekey','jumping','fishing')
redis_conn.sadd("dokey","working","thinking","runing","doing","fishing")
#Scard 命令返回集合中元素的數量,當集合 key 不存在時,返回 0
print(redis_conn.scard("lovekey"))
#Sdiff 命令返回第一個集合與其他集合之間的差異,也可以認為說第一個集合中獨有的元素。不存在的集合 key 將視為空集
print(redis_conn.sdiff("lovekey","dokey"))
#Sinter 命令返回給定所有給定集合的交集。 不存在的集合 key 被視為空集。 當給定集合當中有一個空集時,結果也為空集
print(redis_conn.sinter("lovekey","dokey"))
#Sismember 命令判斷成員元素是否是集合的成員
print(redis_conn.sismember("lovekey","eating"))
#Smembers 命令返回集合中的所有的成員。 不存在的集合 key 被視為空集合
print(redis_conn.smembers("dokey"))
#Spop 命令用於移除集合中的指定 key 的一個或多個隨機元素,移除後會返回移除的元素
print(redis_conn.spop("dokey",2))
#Srem 命令用於移除集合中的一個或多個成員元素,不存在的成員元素會被忽略,被成功移除的元素的數量,不包括被忽略的元素
print(redis_conn.srem("dokey","ok","isok","doing"))
#Sunion 命令返回給定集合的並集。不存在的集合 key 被視為空集
print(redis_conn.sunion("dokey","lovekey"))
#Sunionstore 命令將給定集合的並集存儲在指定的集合 destination 中。如果 destination 已經存在,則將其覆蓋,結果集中的元素數量
print(redis_conn.sunionstore("destkey","dokey","lovekey"))
print("*"*40)
#2.5 sorted set有序集合
# 有序集合和集合一樣也是 string 類型元素的集合,且不允許重復的成員
# 不同的是每個元素都會關聯一個 double 類型的分數。redis 正是通過分數來為集合中的成員進行從小到大的排序
# 有序集合的成員是唯一的,但分數(score)卻可以重復
dict1=dict(lenovo=1)
redis_conn.zadd('computerkey',dict1)
dict2=dict(dell=2)
dict3=dict(asus=2)
redis_conn.zadd('computerkey',dict2)
redis_conn.zadd('computerkey',dict3)
dict4=dict(asustest=4,goodjob=3)
redis_conn.zadd('computerkey',dict4)
#通過索引區間返回有序集合指定區間內的成員
print(redis_conn.zrange('computerkey',0,10))
#Zcard 命令用於計算集合中元素的數量
print(redis_conn.zcard("computerkey"))
#Zscore 命令返回有序集中,成員的分數值。 如果成員元素不是有序集 key 的成員,或 key 不存在,返回 nil
print(redis_conn.zscore("computerkey","dell"))
#Zrank 返回有序集中指定成員的排名。其中有序集成員按分數值遞增(從小到大)順序排列
print(redis_conn.zrank("computerkey","goodjob"))
# Redis Zrem 命令用於移除有序集中的一個或多個成員,不存在的成員將被忽略。當 key 存在但不是有序集類型時,返回一個錯誤, 當key存在時,返回被成功移除的成員的數量,不包括被忽略的成員
print(redis_conn.zrem("computerkey","goodjob"))
tony
33
{"addr":"北京good","phone":13300000000}
34
33
computer
41
None
['v1', 'v2']
{'student2': 'idcard:123456,sex:man,age:33'}
{'student3': '{"perform": "game","num":123456789}'}
{'id': '1', 'name': '張三豐', 'birth': '2000-07-07', 'age': '17', 'clazz': '一年1班', 'createTm': '1504856483000'}
['id', 'name', 'birth', 'age', 'clazz', 'createTm']
['1', '張三豐', '2000-07-07', '17', '一年1班', '1504856483000']
6
['mq', 'mongodb', 'mysql', 'redis']
redis
5
job
5
['mq', 'mongodb', 'mysql', 'redis']
5
{'eating', 'booking', 'jumping'}
{'fishing', 'runing'}
True
{'fishing', 'runing', 'doing', 'thinking', 'working'}
['thinking', 'working']
1
{'jumping', 'fishing', 'runing', 'booking', 'eating'}
5
['lenovo', 'asus', 'dell', 'goodjob', 'asustest']
5
2.0
3
1
end