How to use Python Quickly and efficiently count the total number of large files , Here are some implementation methods and performance comparisons .
Use readlines Method to read all lines :
def readline_count(file_name):
return len(open(file_name).readlines())
Read the contents of each line of the file in turn and count :
def simple_count(file_name):
lines = 0
for _ in open(file_name):
lines += 1
return lines
Use sum Function count :
def sum_count(file_name):
return sum(1 for _ in open(file_name))
def enumerate_count(file_name):
with open(file_name) as f:
for count, _ in enumerate(f, 1):
pass
return count
Fixed size for each read , Then count the number of rows :
def buff_count(file_name):
with open(file_name, 'rb') as f:
count = 0
buf_size = 1024 * 1024
buf = f.read(buf_size)
while buf:
count += buf.count(b'\n')
buf = f.read(buf_size)
return count
Call to use wc Command calculation line :
def wc_count(file_name):
import subprocess
out = subprocess.getoutput("wc -l %s" % file_name)
return int(out.split()[0])
stay buff_count Based on the introduction partial:
def partial_count(file_name):
from functools import partial
buffer = 1024 * 1024
with open(file_name) as f:
return sum(x.count('\n') for x in iter(partial(f.read, buffer), ''))
stay buff_count Based on the introduction itertools modular :
''' No one answers the problems encountered in learning ? Xiaobian created a Python Exchange of learning QQ Group :153708845 Looking for small partners who share the same aspiration , Help each other , There are also good video tutorials and PDF e-book ! '''
def iter_count(file_name):
from itertools import (takewhile, repeat)
buffer = 1024 * 1024
with open(file_name) as f:
buf_gen = takewhile(lambda x: x, (f.read(buffer) for _ in repeat(None)))
return sum(buf.count('\n') for buf in buf_gen)
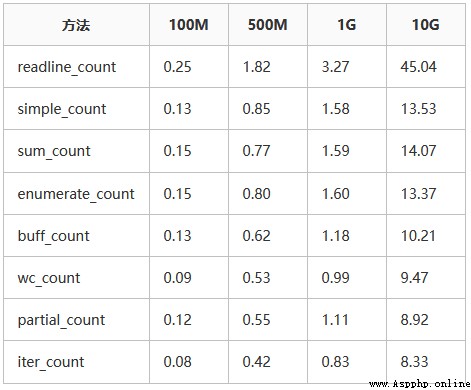
The following is on my computer 4c8g python3.6 Under the environment of , The test respectively 100m、500m、1g、10g The running time of large and small files , Unit second :