Chinese clause , At first glance, it seems to be a very simple job , Generally, we only need to find one 【.!?】 Is it OK to break this kind of typical punctuation symbol .
about Simple text This approach is already feasible ( For example, I see a concise implementation method in this article
Natural language processing learning 3: Chinese clause re.split(),jieba Word segmentation and word frequency statistics FreqDist_zhuzuwei The blog of -CSDN Blog _jieba Clause
NLTK Use notes ,NLTK It is commonly used. Python Natural language processing libraries
However, when I deal with novel texts , Found a loophole in this idea :
This morning, , I went to “ Secret base ” 了 .
therefore , Here I offer a more refined solution , Can solve the above problems :
# Version is python3, If python2 You need to precede the string with u
import re
def cut_sent(para):
para = re.sub('([.!?\?])([^”’])', r"\1\n\2", para) # Single character sentence breaker
para = re.sub('(\.{6})([^”’])', r"\1\n\2", para) # English ellipsis
para = re.sub('(\…{2})([^”’])', r"\1\n\2", para) # Chinese Ellipsis
para = re.sub('([.!?\?][”’])([^,.!?\?])', r'\1\n\2', para)
# If there is a terminator before the double quotation mark , Then double quotation marks are the end of the sentence , Break the sentence \n Put it behind double quotation marks , Note that the previous sentences carefully retain double quotation marks
para = para.rstrip() # If there is extra at the end of the paragraph \n Just get rid of it
# Semicolons are considered in many rules ;, But here I ignore it , Dashes 、 English double quotation marks are also ignored , If necessary, just make some simple adjustments .
return para.split("\n")
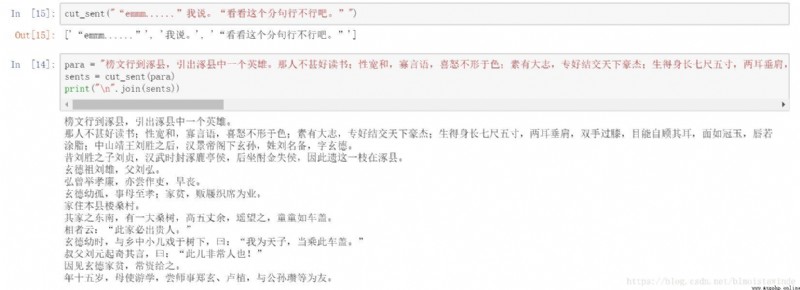
Test the effect
HarvestText Is a focus without ( weak ) Supervision methods , Be able to integrate domain knowledge ( Such as type , Alias ) A library for simple and efficient processing and analysis of texts in specific fields . It is suitable for many text preprocessing and preliminary exploratory analysis tasks , In novel analysis , Network text , Professional literature and other fields have potential application value .
While processing data , In addition to clauses, you may have to clean up special data formats first ,
Such as micro-blog ,HTML Code ,URL,Email etc. ,
Some big guy ! A number of commonly used data preprocessing and cleaning operations are integrated into the developed HarvestText library
github(https://github.com/blmoistawinde/HarvestText)
Code cloud :https://gitee.com/dingding962285595/HarvestText
Using document :Welcome to HarvestText’s documentation! — HarvestText 0.8.1.7 documentation
print(" Various cleaning texts ")
ht0 = HarvestText()
# The default setting can be used to clean Weibo text
text1 = " reply @ Qian Xuming QXM:[ Hee hee ][ Hee hee ] //@ Qian Xuming QXM: Brother Yang [good][good]"
print(" Clean Weibo 【@ And emoticons 】")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1))
# URL Clean-up
text1 = "【# Zhao Wei #: Preparing for the next movie But it's not a youth movie ....http://t.cn/8FLopdQ"
print(" Cleaning website URL")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1, remove_url=True))
# Clean the mailbox
text1 = " My email is [email protected], Welcome to contact "
print(" Clean the mailbox ")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1, email=True))
# Handle URL Escape character
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print("URL Turn to normal characters ")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1, norm_url=True, remove_url=False))
text1 = "www. chinese and space.com"
print(" Normal character to URL[ With Chinese and spaces request We need to pay attention to ]")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1, to_url=True, remove_url=False))
# Handle HTML Escape character
text1 = "<a c> ''"
print("HTML Turn to normal characters ")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1, norm_html=True))
# From traditional Chinese to simplified Chinese
text1 = " Who pays for heartbreak "
print(" From traditional Chinese to simplified Chinese ")
print(" primary :", text1)
print(" After cleaning :", ht0.clean_text(text1, t2s=True))result
Various cleaning texts
Clean Weibo 【@ And emoticons 】
primary : reply @ Qian Xuming QXM:[ Hee hee ][ Hee hee ] //@ Qian Xuming QXM: Brother Yang [good][good]
After cleaning : Brother Yang
Cleaning website URL
primary : 【# Zhao Wei #: Preparing for the next movie But it's not a youth movie ....http://t.cn/8FLopdQ
After cleaning : 【# Zhao Wei #: Preparing for the next movie But it's not a youth movie ....
Clean the mailbox
primary : My email is [email protected], Welcome to contact
After cleaning : My email is , Welcome to contact
URL Turn to normal characters
primary : www.%E4%B8%AD%E6%96%87%20and%20space.com
After cleaning : www. chinese and space.com
Normal character to URL[ With Chinese and spaces request We need to pay attention to ]
primary : www. chinese and space.com
After cleaning : www.%E4%B8%AD%E6%96%87%20and%20space.com
HTML Turn to normal characters
primary : <a c> ''
After cleaning : <a c> ''
From traditional Chinese to simplified Chinese
primary : Who pays for heartbreak
After cleaning : Who pays for heartbreak