1、雙向RNN
2、堆疊的雙向RNN
3、雙向LSTM實現MNIST數據集分類
1、雙向RNN雙向RNN(Bidirectional RNN)的結構如下圖所示。
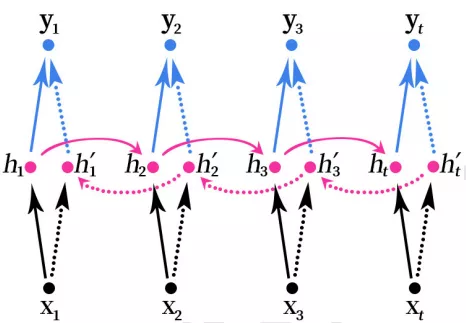
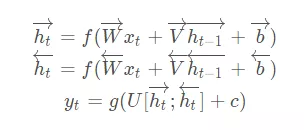

雙向的 RNN 是同時考慮“過去”和“未來”的信息。上圖是一個序列長度為 4 的雙向RNN 結構。

雙向RNN就像是我們做閱讀理解的時候從頭向後讀一遍文章,然後又從後往前讀一遍文章,然後再做題。有可能從後往前再讀一遍文章的時候會有新的不一樣的理解,最後模型可能會得到更好的結果。
2、堆疊的雙向RNN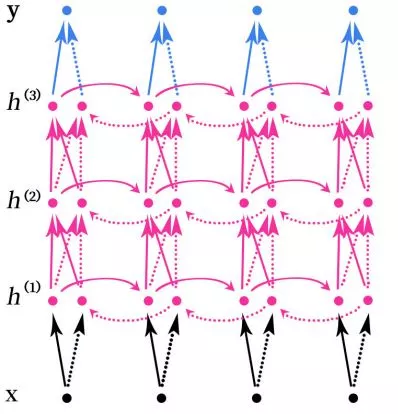
堆疊的雙向RNN(Stacked Bidirectional RNN)的結構如上圖所示。上圖是一個堆疊了3個隱藏層的RNN網絡。
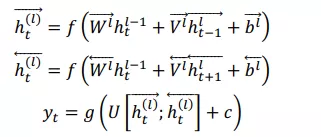
注意,這裡的堆疊的雙向RNN並不是只有雙向的RNN才可以堆疊,其實任意的RNN都可以堆疊,如SimpleRNN、LSTM和GRU這些循環神經網絡也可以進行堆疊。
堆疊指的是在RNN的結構中疊加多層,類似於BP神經網絡中可以疊加多層,增加網絡的非線性。
3、雙向LSTM實現MNIST數據集分類import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densefrom tensorflow.keras.layers import LSTM,Dropout,Bidirectionalfrom tensorflow.keras.optimizers import Adamimport matplotlib.pyplot as plt# 載入數據集mnist = tf.keras.datasets.mnist# 載入數據,數據載入的時候就已經劃分好訓練集和測試集# 訓練集數據x_train的數據形狀為(60000,28,28)# 訓練集標簽y_train的數據形狀為(60000)# 測試集數據x_test的數據形狀為(10000,28,28)# 測試集標簽y_test的數據形狀為(10000)(x_train, y_train), (x_test, y_test) = mnist.load_data()# 對訓練集和測試集的數據進行歸一化處理,有助於提升模型訓練速度x_train, x_test = x_train / 255.0, x_test / 255.0# 把訓練集和測試集的標簽轉為獨熱編碼y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)# 數據大小-一行有28個像素input_size = 28# 序列長度-一共有28行time_steps = 28# 隱藏層memory block個數cell_size = 50 # 創建模型# 循環神經網絡的數據輸入必須是3維數據# 數據格式為(數據數量,序列長度,數據大小)# 載入的mnist數據的格式剛好符合要求# 注意這裡的input_shape設置模型數據輸入時不需要設置數據的數量model = Sequential([ Bidirectional(LSTM(units=cell_size,input_shape=(time_steps,input_size),return_sequences=True)), Dropout(0.2), Bidirectional(LSTM(cell_size)), Dropout(0.2), # 50個memory block輸出的50個值跟輸出層10個神經元全連接 Dense(10,activation=tf.keras.activations.softmax)])# 循環神經網絡的數據輸入必須是3維數據# 數據格式為(數據數量,序列長度,數據大小)# 載入的mnist數據的格式剛好符合要求# 注意這裡的input_shape設置模型數據輸入時不需要設置數據的數量# model.add(LSTM(# units = cell_size,# input_shape = (time_steps,input_size),# ))# 50個memory block輸出的50個值跟輸出層10個神經元全連接# model.add(Dense(10,activation='softmax'))# 定義優化器adam = Adam(lr=1e-3)# 定義優化器,loss function,訓練過程中計算准確率 使用交叉熵損失函數model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])# 訓練模型history=model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test,y_test))#打印模型摘要model.summary()loss=history.history['loss']val_loss=history.history['val_loss']accuracy=history.history['accuracy']val_accuracy=history.history['val_accuracy']# 繪制loss曲線plt.plot(loss, label='Training Loss')plt.plot(val_loss, label='Validation Loss')plt.title('Training and Validation Loss')plt.legend()plt.show()# 繪制acc曲線plt.plot(accuracy, label='Training accuracy')plt.plot(val_accuracy, label='Validation accuracy')plt.title('Training and Validation Loss')plt.legend()plt.show()這個可能對文本數據比較容易處理,這裡用這個模型有點勉強,只是簡單測試下。
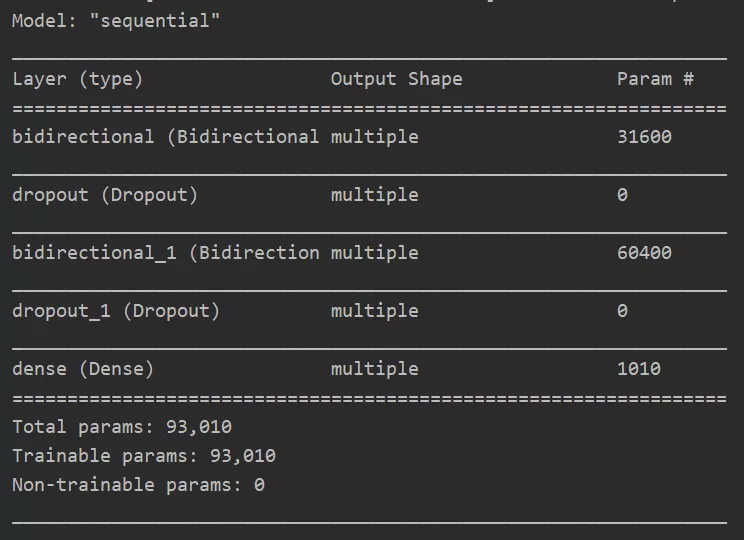
模型摘要:
acc曲線:
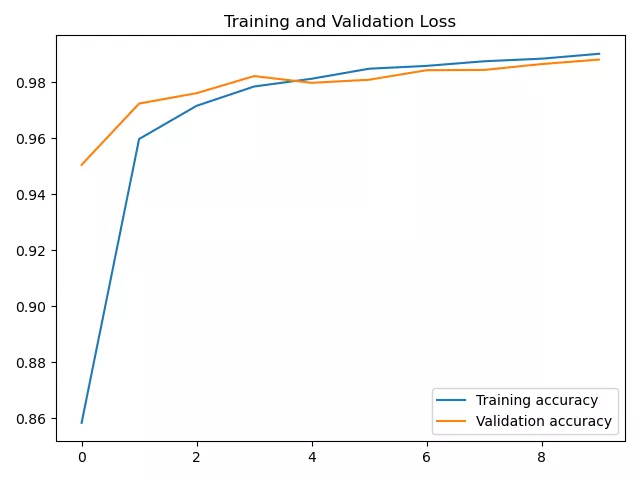
loss曲線:
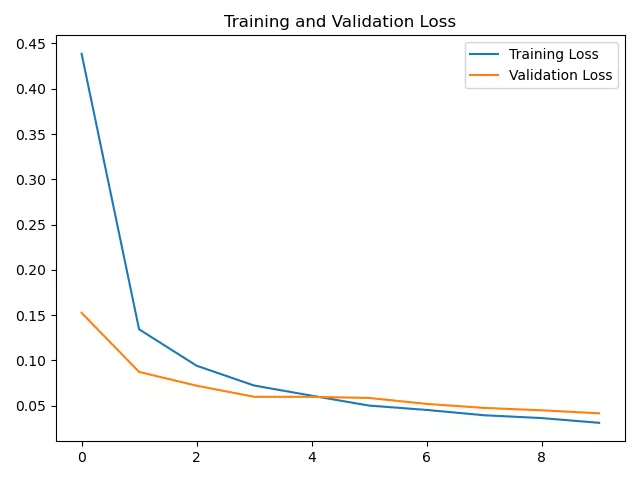

到此這篇關於Python實現雙向RNN與堆疊的雙向RNN的示例代碼的文章就介紹到這了,更多相關Python 雙向RNN內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!