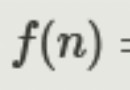“ Used to sql Medium row_number function , Accustomed to his convenience , So in pandas While processing data , Is there a similar function to sort , Of course, there are , such as rank function .”
rank(axis=0, method='average', numeric_only=None,
na_option='keep', ascending=True, pct=False)
By default :axis=0 Indicates sorting by index ;ascending=True Sort sort in ascending order ;pct=False Indicates no output percentage ;na_option='keep' Indicates that null values are not processed .
Next, we will learn from the data rank Functions under various parameters :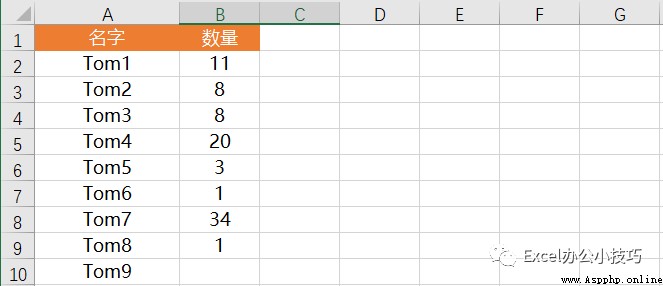
01 method: How do you want to row
Change parameters method Options for , Other default parameters do not change :
first: Means to arrange by numerical value , If the values are the same , Sort by occurrence . Such as 1,2,3,4,5,..., similar SQL Medium row_number function ;
min: Means to arrange by numerical value , If the values are the same , The serial number is the same , But the subsequent serial number is still postponed according to the number of values , Such as 1,2,2,4,5,..., similar SQL Medium rank function ;
dense: Means to arrange by numerical value , If the values are the same , The serial number is the same , At the same time, the subsequent serial number is not affected , Such as 1,2,2,3,4,..., similar SQL Medium dense_rank function ;
data['first']=data[' Number '].rank(method='first' )
data['min']=data[' Number '].rank(method='min' )
data['dense']=data[' Number '].rank(method='dense')give the result as follows :
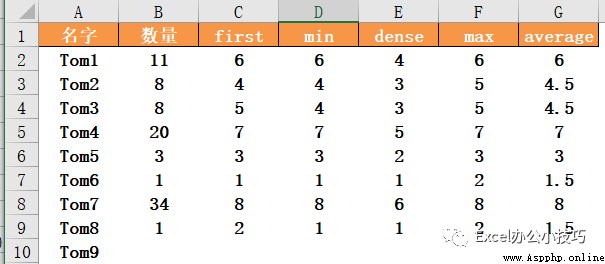
The other two options ,method='max' when , Same value , Output by the largest sequence number . Can be interpreted as , stay first Based on the sorting results , When the values are the same , Both values are output according to the maximum sequence number ; and method='average' when , The two values are output according to the average value of the corresponding serial number .
02 ascending: Whoever is young is reasonable ?
Above introduction method We default to ascending order , If the quantity represents the number of orders completed by the sales , Of course, only those who have completed more will be in the front , therefore ,ascending=False when , Descending order .
data[' Descending ']=data[' Number '].rank(method='min',ascending=False) 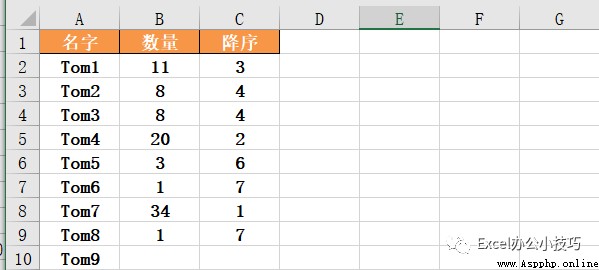
03 na_option: Don't lose the data !
By default ,na_option='keep', Null values are not taken into account , that , If the quantity indicates the number of customer service complaints , If the number is empty, it should be the best . therefore , When na_option='top', Indicates that null values rank first ,na_option='bottom', Indicates that null values rank last .
data['top']=data[' Number '].rank(method='min',na_option='top')
data['bottom']=data[' Number '].rank(method='min',na_option='bottom')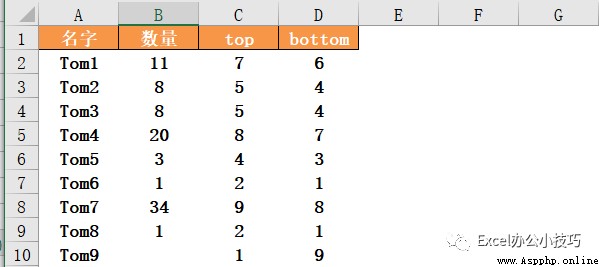
04 pct: Computational distribution ?
pct Default =False, When you want to output the distribution of values ,pct=True that will do .
data['pct']=data[' Number '].rank(method='min',pct=True)give the result as follows :

remarks : Above contents , Only for learning notes ~