大家好,這裡是程序員晚楓。
很多朋友使用Python中的Pandas這個庫進行Excel的數據處理,數據處理從宏觀上分為這麼3個階段:數據讀取、數據處理、數據輸出。
對於大多數新人來說,在數據讀取的這一步就卡住了。
今天我們就來一起學習一下,Pandas官方推薦的6種Excel讀取方式。
本文一共3部分:下載pandas和生成Excel文件、源碼解讀、讀取Excel的6種方式。
如果你是一個熟練的Python使用者,你可以直接跳轉到第3部分。
如果你是剛接觸Python或者剛接觸Pandas,建議你從第1部分開始看。
下文所有代碼,都可以 ←左右→ 滑動查看,也可以直接復制粘貼。
Pandas庫。這樣你才能使用Pandas,這個不難理解吧?Excel文件。為了確保大家和本文的操作統一,建議大家使用和本文同樣的Excel文件。怎麼下載Pandas?怎麼獲取Excel?我們都用1行命令來自動搞定,畢竟我們是自動化辦公社區,如果這些操作不能自動化搞定,那豈不是太過分了?
你直接執行下面這行代碼,就會生成一個和本文一模一樣的Excel文件啦~
在你的電腦終端裡面,執行下面這行命令,就可以自動安裝pandas了~
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-office -UExcel文件也不需要你四處下載,之前我們不是介紹了一個功能嘛,這裡是它的用武之地:1行代碼,自動生成帶模擬數據的Excel文件
以後我們處理Excel的案例和演示,每次都會使用這種自動生成的方法,你當然也可以手動編輯一個,但如果未來我們要學習如何處理10w行的Excel文件呢?不論你是手動生成還是百度雲下載,都是一個及其緩慢的過程。
但用下面這個生成方式,模擬一個10w+數據的Excel文件,也是不過是一瞬間的事情,一定要嘗試一下喲~你會發現新世界的。
import office
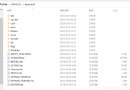
office.excel.fake2excel(columns=['name', 'company_prefix','job'], rows=5)在你的PyCharm裡面,執行上面這行代碼,就可以生成一個如下圖所示,和本文一模一樣的Excel文件啦~
其實學習Pandas很簡單,不用網上東奔西找,所有的代碼功能,創始人和開發者們都通過注釋的方法寫在源代碼裡了。
如何查找pandas的源代碼?
下載好pandas以後,我們就打開pandas的源碼,看看pandas推薦的讀取方式有哪些。pandas源碼的路徑:D:\你的python安裝目錄\Lib\site-packages\pandas\
打開源碼後,pandas文件夾下有多個目錄結構,如下圖所示,我們要的讀取Excel功能,在pandas\io\excel\_base.py文件中的290行-350行。如下圖所示
既然找到了這段源碼,那麼問題來了源碼告訴了我們什麼?
下面我們就根據上文獲取到的pandas源碼,逐個解析一下這6種讀取excel的方式。
這種讀取方式,適合Excel裡的數據,本身有一列表示序號的情況。
pd.read_excel('fake2excel.xlsx', index_col=0)
# 使用index_col=0,指定第1列作為索引列。結果如下圖所示:
這種方式不符合我們這個文件的要求,所以我們可以進行以下修改:不要指定索引列。
代碼和結果如下:
pd.read_excel('fake2excel.xlsx', index_col=None)見名知意。
pd.read_excel(open('fake2excel.xlsx', 'rb'), sheet_name='Sheet2')
# 使用sheet_name=0,指定讀取sheet2裡面的內容。我們在原表裡加入了sheet2,結果如下圖所示:
讀取本身沒有列名的數據。
pd.read_excel('fake2excel.xlsx', index_col=None, header=None)
# 使用header=None,取消header讀取。結果如下圖所示:
這種適合高端玩家,在對數據處理精度要求比較高或者速度要求比較快的情況下。
pd.read_excel('fake2excel.xlsx', index_col=0, dtype={'age': float})
# 使用dtype,指定某一列的數據類型。結果如下圖所示:
這種使用的場景是什麼呢?比如在收集信息的時候據時候,發現有人填的年齡是負數,那就自動給他把年齡清空掉,讓他重新填寫。
pd.read_excel('fake2excel.xlsx', index_col=None,na_values={'name':"龐強"})
# 使用na_values,自己定義不顯示的數據結果如下圖所示:
不僅Python是可以寫注釋的,Excel也是可以寫注釋的。很多人沒有用過,用過的朋友在評論區說一下你為什麼給Excel寫注釋吧~?
pandas提供了處理Excel注釋行的方法。
pd.read_excel('fake2excel.xlsx', index_col=None, comment='#') 結果如下圖所示:
做為Python程序員,平時需要大家閱讀源碼,認清楚代碼背後的原理和邏輯。
最近使用pandas比較多,正好pandas也可以處理excel,所以近期會持續的更新一些pandas使用的文章。
下一篇想看什麼,在評論區告訴我吧