str=encode([encoding="utf-8]"[,error="strict"])
默認是utf-8 如果想用簡體中文也可以用gb2312
strict:遇到錯誤的時候就拋出異常
也可以是ignore(忽視) 還可以是replace
if __name__ == '__main__':
value='你好,我是代碼浪人,浪裡浪'
byte=value.encode('GBK')
print(value)
print(byte)
》》》
你好,我是代碼浪人,浪裡浪
b'\xc4\xe3\xba\xc3\xa3\xac\xce\xd2\xca\xc7\xb4\xfa\xc2\xeb\xc0\xcb\xc8\xcb\xa3\xac\xc0\xcb\xc0\xef\xc0\xcb'
str=decode([encoding="utf-8]"[,error="strict"])
默認是utf-8 如果想用簡體中文也可以用gb2312
strict:遇到錯誤的時候就拋出異常
也可以是ignore(忽視) 還可以是replace
if __name__ == '__main__':
value='你好,我是代碼浪人,浪裡浪'
byte=value.encode('GBK')
print(value)
print(byte)
print(byte.decode('GBK'))
》》》
你好,我是代碼浪人,浪裡浪
b'\xc4\xe3\xba\xc3\xa3\xac\xce\xd2\xca\xc7\xb4\xfa\xc2\xeb\xc0\xcb\xc8\xcb\xa3\xac\xc0\xcb\xc0\xef\xc0\xcb'
你好,我是代碼浪人,浪裡浪
直接使用加號(同類型,不同類型會報錯)
if __name__ == '__main__':
value1="你好"
value2=123
print(value1+value2)

漢字在GBK/GB2312編碼占2個字節
在UTF-8.uncode占3個字節(或者4個字節)
計算長度提供len(string) 函數計算方法
if __name__ == '__main__':
value1="你好"
print(len(value1))
print(len(value1.encode('GBK')))
》》》
2
4
string[startstep]
start:開始位置,默認為0
end:結束位置,不包含
step:步長,默認為1
if __name__ == '__main__':
value1="你好345678"
print(value1[2:])
print(value1[:2])
print(value1[0:8:2])
》》》
345678
你好
你357
str.split(sep,maxsplit)
str:要分割的字符串
sep:指定分隔符,默認為None
maxsplit: 可選參數,默認為-1-> 分割次數
strnew=str.join(iterable)
strnew:新的字符串
string:用於合並時候的分隔符號
iterable:可迭代對象,將迭代對象中的所有元素按照分個字符串進行拼接
list_str=['我','愛','你']
list_new='*'.join(list_str)
print(list_new)
》》》
我*愛*你
str.count(sub[,start[,end]])
str檢索的字符串
sub:需要檢索的子字符串
start:開始位置
end:結束位置
str='123456'
print(str.count(6))
》》》
1
str.find(sub[,start[,end]])
str檢索的字符串
sub:需要檢索的子字符串
start:開始位置
end:結束位置
str='123456'
print(str.find(6))
》》》
5
if __name__ == '__main__':
list_str=['我','愛','你']
print('愛' in list_str)
》》》
True
str.index(sub[,start[,end]])
str檢索的字符串
sub:需要檢索的子字符串
start:開始位置
end:結束位置
str.startswitch(prefix[,start[,end]])
str檢索的字符串
prefix:需要檢索的子字符串
start:開始位置
end:結束位置
if __name__ == '__main__':
list_str=['我','愛','你']
print(list_str.startswitch('我'))
》》》
True
str.endswitch(prefix[,start[,end]])
str檢索的字符串
prefix:需要檢索的子字符串
start:開始位置
end:結束位置
if __name__ == '__main__':
list_str=['我','愛','你']
print(list_str.endswitch('你'))
》》》
True
if __name__ == '__main__':
str='ABC'
print(str.lower())
str='abc'
print(str.upper())
》》》
abc
ABC
str.strip([char])//默認為是去除首尾空字符和特殊字符串,char是可選,可指定多個
str.lstrip([char])//默認為是去除左邊空字符和特殊字符串,char是可選,可指定多個,
str.rstrip([char])//默認為是去除右邊空字符和特殊字符串,char是可選,可指定多個
Python 支持格式化字符串的輸出 。盡管這樣可能會用到非常復雜的表達式,但最基本的用法是將一個值插入到一個有字符串格式符 %s 的字符串中。
print ("我叫 %s 今年 %d 歲!" % ('小明', 10))
我叫 小明 今年 10 歲!
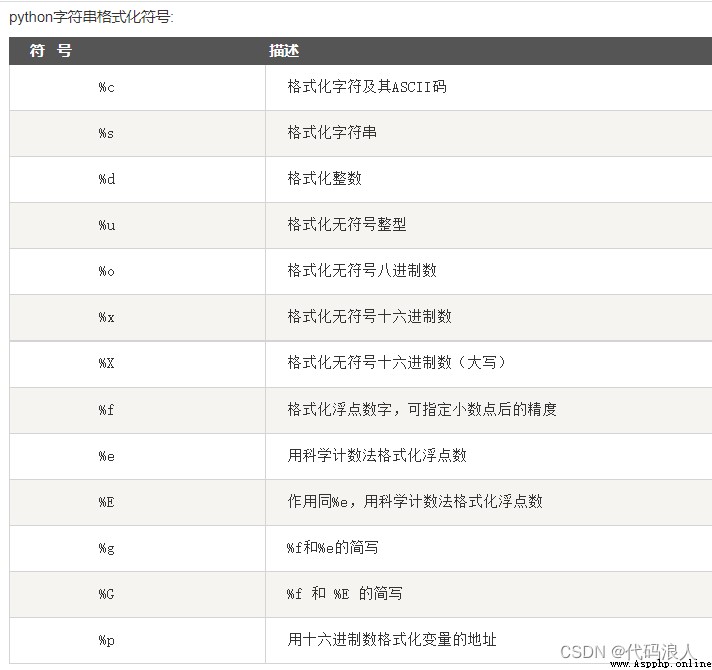
格式化操作符輔助指令:
Python2.6 開始,新增了一種格式化字符串的函數 str.format(),它增強了字符串格式化的功能。
基本語法是通過 {} 和 : 來代替以前的 % 。
format 函數可以接受不限個參數,位置可以不按順序
>>>"{} {}".format("hello", "world") # 不設置指定位置,按默認順序
'hello world'
>>> "{0} {1}".format("hello", "world") # 設置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 設置指定位置
'world hello world'
也可以設置參數
# -*- coding: UTF-8 -*-
print("網站名:{name}, 地址 {url}".format(name="菜鳥教程", url="www.runoob.com"))
# 通過字典設置參數
site = {"name": "菜鳥教程", "url": "www.runoob.com"}
print("網站名:{name}, 地址 {url}".format(**site))
# 通過列表索引設置參數
my_list = ['菜鳥教程', 'www.runoob.com']
print("網站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必須的
網站名:菜鳥教程, 地址 www.runoob.com
網站名:菜鳥教程, 地址 www.runoob.com
網站名:菜鳥教程, 地址 www.runoob.com
也可以向 str.format() 傳入對象:
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 為: {0.value}'.format(my_value)) # "0" 是可選的
數字
>>> print("{:.2f}".format(3.1415926))
3.14
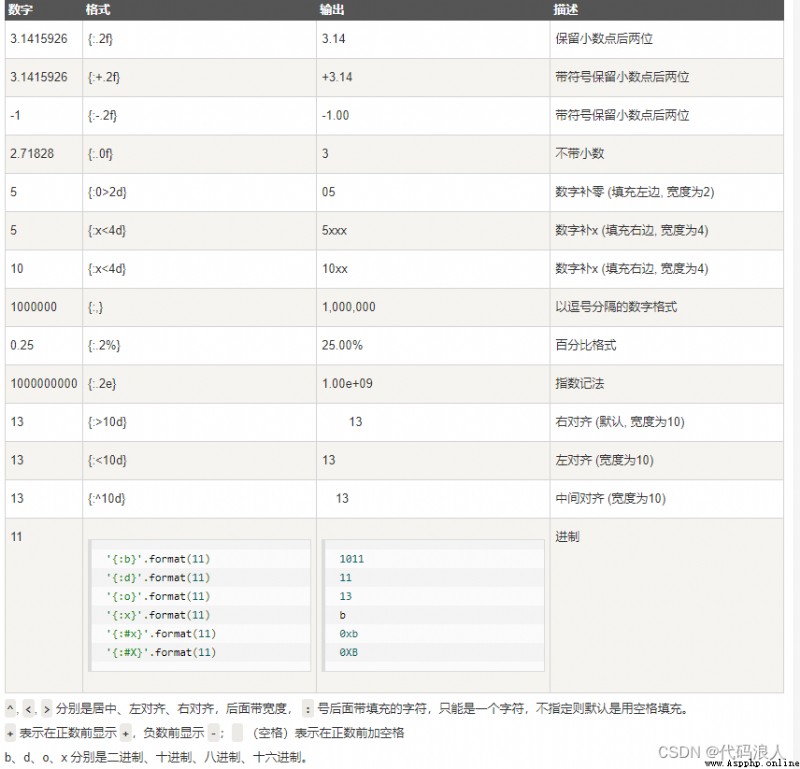
此外我們可以使用大括號 {} 來轉義大括號,如下實例:
print ("{} 對應的位置是 {
{0}}".format("runoob"))
》》》
runoob 對應的位置是 {0}