Given a function as shown in the figure , How to program through computer algorithm to find f(x)min?
The traditional approach is Numerical solution , As shown in the figure
Follow the following steps to iterate the cycle until optimal :
1. Any given initial value x0;
2. Randomly generate incremental direction , Combined step size generation Δx;
3. Calculation comparison f(x0) And f(x0+Δx) Size , if f(x0+Δx)<f(x0) Update location , Otherwise regenerate Δx;
4. repeat ②③ Until it converges to the optimal f(x)min.
The biggest advantage of numerical solution is the simplicity of programming , But the flaws are obvious :
1. The setting of the initial value has a great influence on the convergence speed of the result ;
2. Incremental direction random generation , Low efficiency ;
3. It is easy to fall into local optimal solution ;
4. Unable to deal with “ plateau ” Type function .
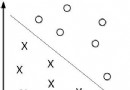
So-called Fall into local optimal solution It refers to when the iteration enters a minimum or its neighborhood , Because the step size is not selected properly , Whether positive or negative , The learning effect is not as good as the current , As a result, it is impossible to iterate to the global optimum . For this problem, it is shown in the figure , When iteration falls into x=xj when , Because of the learning step step The limitation of , Unable to make f(xj±Step)<f(xj), Therefore, the iteration is locked in the red section of the graph . It can be seen that x=xj It is not the desired global optimum .
If the following figure appears “ plateau ” function , It may also prevent the iteration from being updated .
Gradient descent algorithm It can be regarded as an improvement of numerical solution , The explanation is as follows :
Note No k After iteration , The argument is updated to x=xk, Let the objective function f(x) stay x=xk Taylor expansion :
f(x)=f(xk)+f′(xk)(x−xk)+o(x)Investigate f(x)min, Expect f(xk+1)<f(xk), thus :
f(xk+1)−f(xk)=f′(xk)(xk+1−xk)<0if f′(xk)>0 be xk+1<xk, That is, the iteration direction is negative ; The opposite is positive . Might as well set xk+1−xk=−f′(xk), To ensure that f(xk+1)−f(xk)<0. It must be pointed out , Taylor's formula holds only if x→x0, so ∣f′(xk)∣ Not too big , otherwise xk+1 And xk The distance is too far, resulting in residual error . So introduce Learning rate γ∈(0,1) To reduce the offset , namely xk+1−xk=−γf′(xk)
On the engineering , Learning rate γ We should make a reasonable choice in combination with practical application ,==γ Too large an amount makes the iteration oscillate on both sides of the minimum , The algorithm can't converge ;γ Too small will reduce learning efficiency , The algorithm converges slowly ==.
For vector , The above iterative formula is extended to
xk+1=xk−γ∇xkamong ∇x=(∂x1∂f(x),∂x2∂f(x),⋯⋯,∂xn∂f(x))T Is the gradient of multivariate function , Therefore, this iterative algorithm is also called Gradient descent algorithm
The gradient descent algorithm determines the direction and step size of each iteration through the function gradient , Improved algorithm efficiency . But in principle, we can know , This algorithm cannot solve the initial value setting in numerical solution 、 The problem of local optimal collapse and partial function locking .
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib as mpl
from Logit import Logit
''' * @breif: from CSV Load the specified data in * @param[in]: file -> file name * @param[in]: colName -> Column name to load * @param[in]: mode -> Load mode , set: A dictionary consisting of a column name and its data , df: df type * @retval: mode Return value in mode '''
def loadCsvData(file, colName, mode='df'):
assert mode in ('set', 'df')
df = pd.read_csv(file, encoding='utf-8-sig', usecols=colName)
if mode == 'df':
return df
if mode == 'set':
res = {}
for col in colName:
res[col] = df[col].values
return res
if __name__ == '__main__':
# ============================
# Read CSV data
# ============================
csvPath = os.path.abspath(os.path.join(__file__, "../../data/dataset3.0alpha.csv"))
dataX = loadCsvData(csvPath, [" Sugar content ", " density "], 'df')
dataY = loadCsvData(csvPath, [" Good melon "], 'df')
label = np.array([
1 if i == " yes " else 0
for i in list(map(lambda s: s.strip(), list(dataY[' Good melon '])))
])
# ============================
# Draw sample points
# ============================
line_x = np.array([np.min(dataX[' density ']), np.max(dataX[' density '])])
mpl.rcParams['font.sans-serif'] = [u'SimHei']
plt.title(' Log probability regression simulation \nLogistic Regression Simulation')
plt.xlabel('density')
plt.ylabel('sugarRate')
plt.scatter(dataX[' density '][label==0],
dataX[' Sugar content '][label==0],
marker='^',
color='k',
s=100,
label=' Bad melon ')
plt.scatter(dataX[' density '][label==1],
dataX[' Sugar content '][label==1],
marker='^',
color='r',
s=100,
label=' Good melon ')
# ============================
# Instantiate log probability regression model
# ============================
logit = Logit(dataX, label)
# Gradient descent method
logit.logitRegression(logit.gradientDescent)
line_y = -logit.w[0, 0] / logit.w[1, 0] * line_x - logit.w[2, 0] / logit.w[1, 0]
plt.plot(line_x, line_y, 'b-', label=" Gradient descent method ")
# mapping
plt.legend(loc='upper left')
plt.show()
Copy code