pip install lxml ‐i https://pypi.douban.com/simplefrom lxml import etree html_tree = etree.parse('XX.html')html_tree = etree.HTML(response.read().decode('utf‐8')1. Path query
//: Find all descendant nodes , Regardless of hierarchy
/ : Find the direct child node
2. Predicate query
//div[@id]
//div[@id="maincontent"]
3. Property query
//@class
4. Fuzzy query
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
5. Content query
//div/h1/text()
6. Logical operations
//div[@id="head" and @class="s_down"]
//title | //price
xpath.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="class1"> Beijing </li>
<li id="l2" class="class2"> Shanghai </li>
<li id="d1"> Guangzhou </li>
<li> Shenzhen </li>
</ul>
</body>
</html>
from lxml import etree
# xpath analysis
# Local files : etree.parse
# Server corresponding data response.read().decode('utf-8') etree.HTML()
tree = etree.parse('xpath.html')
# lookup url The lower one li
li_list = tree.xpath('//body/ul/li')
print(len(li_list)) # 4
# Get the content in the tag
li_list = tree.xpath('//body/ul/li/text()')
print(li_list) # [' Beijing ', ' Shanghai ', ' Guangzhou ', ' Shenzhen ']
# Get the belt id Attribute li
li_list = tree.xpath('//ul/li[@id]')
print(len(li_list)) # 3
# obtain id by l1 Label content of
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list) # [' Beijing ']
# obtain id by l1 Of class Property value
c1 = tree.xpath('//ul/li[@id="l1"]/@class')
print(c1) # ['class1']
# obtain id Contained in the l The label of
li_list = tree.xpath('//ul/li[contains(@id, "l")]/text()')
print(li_list) # [' Beijing ', ' Shanghai ']
# obtain id With d Label at the beginning
li_list = tree.xpath('//ul/li[starts-with(@id,"d")]/text()')
print(li_list) # [' Guangzhou ']
# obtain id by l2 also class by class2 The label of
li_list = tree.xpath('//ul/li[@id="l2" and @class="class2"]/text()')
print(li_list) # [' Shanghai ']
# obtain id by l2 or id by d1 The label of
li_list = tree.xpath('//ul/li[@id="l2"]/text() | //ul/li[@id="d1"]/text()')
print(li_list) # [' Shanghai ', ' Guangzhou ']
import urllib.request
from lxml import etree
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
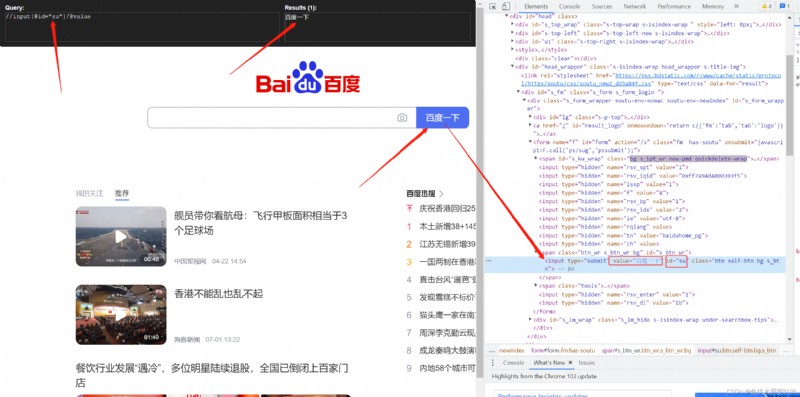
value = tree.xpath('//input[@id="su"]/@value')
print(value)
# demand The pictures of the first ten pages downloaded
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):
if (page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# Download the pictures
# urllib.request.urlretrieve(' Picture address ',' Name of file ')
tree = etree.HTML(content)
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# Generally, websites that design pictures will load lazily
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
print(src_list)
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url, filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input(' Please enter the starting page number '))
end_page = int(input(' Please enter the end page number '))
for page in range(start_page, end_page + 1):
# (1) Request object customization
request = create_request(page)
# (2) Access to the source page
content = get_content(request)
# (3) download
down_load(content)
pip install jsonpath
obj = json.load(open('json file ', 'r', encoding='utf‐8'))
ret = jsonpath.jsonpath(obj, 'jsonpath grammar ')
JSONPath Grammatical elements and correspondences XPath Contrast of elements :
Example :
jsonpath.json
{
"store": {
"book": [
{
"category": " Fix true ",
"author": " Six ways ",
"title": " How bad guys are trained ",
"price": 8.95
},
{
"category": " Fix true ",
"author": " Scarab potatoes ",
"title": " Break the vault of heaven ",
"price": 12.99
},
{
"category": " Fix true ",
"author": " Three little Tang family ",
"title": " Doulo land ",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": " Fix true ",
"author": " The third uncle of Nanpai ",
"title": " Star change ",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author": " Old horse ",
"color": " black ",
"price": 19.95
}
}
}
import json
import jsonpath
obj = json.load(open('jsonpath.json', 'r', encoding='utf-8'))
# The author of all the books in the bookstore
author_list = jsonpath.jsonpath(obj, '$.store.book[*].author')
print(author_list) # [' Six ways ', ' Scarab potatoes ', ' Three little Tang family ', ' The third uncle of Nanpai ']
# All the authors
author_list = jsonpath.jsonpath(obj, '$..author')
print(author_list) # [' Six ways ', ' Scarab potatoes ', ' Three little Tang family ', ' The third uncle of Nanpai ', ' Old horse ']
# store All the elements below
tag_list = jsonpath.jsonpath(obj, '$.store.*')
print(
tag_list) # [[{'category': ' Fix true ', 'author': ' Six ways ', 'title': ' How bad guys are trained ', 'price': 8.95}, {'category': ' Fix true ', 'author': ' Scarab potatoes ', 'title': ' Break the vault of heaven ', 'price': 12.99}, {'category': ' Fix true ', 'author': ' Three little Tang family ', 'title': ' Doulo land ', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': ' Fix true ', 'author': ' The third uncle of Nanpai ', 'title': ' Star change ', 'isbn': '0-395-19395-8', 'price': 22.99}], {'author': ' Old horse ', 'color': ' black ', 'price': 19.95}]
# store Everything in it price
price_list = jsonpath.jsonpath(obj, '$.store..price')
print(price_list) # [8.95, 12.99, 8.99, 22.99, 19.95]
# The third book
book = jsonpath.jsonpath(obj, '$..book[2]')
print(book) # [{'category': ' Fix true ', 'author': ' Three little Tang family ', 'title': ' Doulo land ', 'isbn': '0-553-21311-3', 'price': 8.99}]
# The last book
book = jsonpath.jsonpath(obj, '$..book[(@.length-1)]')
print(book) # [{'category': ' Fix true ', 'author': ' The third uncle of Nanpai ', 'title': ' Star change ', 'isbn': '0-395-19395-8', 'price': 22.99}]
# The first two books
book_list = jsonpath.jsonpath(obj, '$..book[0,1]')
# book_list = jsonpath.jsonpath(obj,'$..book[:2]')
print(
book_list) # [{'category': ' Fix true ', 'author': ' Six ways ', 'title': ' How bad guys are trained ', 'price': 8.95}, {'category': ' Fix true ', 'author': ' Scarab potatoes ', 'title': ' Break the vault of heaven ', 'price': 12.99}]
# Conditional filtering needs to be done in () Add a ?
# Filter out all that contains isbn The book of .
book_list = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
print(
book_list) # [{'category': ' Fix true ', 'author': ' Three little Tang family ', 'title': ' Doulo land ', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': ' Fix true ', 'author': ' The third uncle of Nanpai ', 'title': ' Star change ', 'isbn': '0-395-19395-8', 'price': 22.99}]
# Which book exceeds 10 Yuan
book_list = jsonpath.jsonpath(obj, '$..book[?(@.price>10)]')
print(
book_list) # [{'category': ' Fix true ', 'author': ' Scarab potatoes ', 'title': ' Break the vault of heaven ', 'price': 12.99}, {'category': ' Fix true ', 'author': ' The third uncle of Nanpai ', 'title': ' Star change ', 'isbn': '0-395-19395-8', 'price': 22.99}]
1.BeautifulSoup abbreviation : bs4
2. What is? BeatifulSoup?
BeautifulSoup, and lxml equally , It's a html The parser , The main function is to parse and extract data
3. Advantages and disadvantages ?
shortcoming : There is no efficiency lxml The high efficiency
advantage : User friendly interface design , Easy to use
1. install
pip install bs4
2. Import
from bs4 import BeautifulSoup
3. Create objects
The file generation object of the server response soup = BeautifulSoup(response.read().decode(), 'lxml')
Generate objects from local files soup = BeautifulSoup(open('1.html'), 'lxml')
Be careful : The default encoding format of the open file gbk Therefore, you need to specify the open encoding format utf-8
1. Find nodes by tag name
soup.a 【 notes 】 I can only find the first one a
soup.a.name
soup.a.attrs
2. function
(1).find( Return an object )
find('a'): Only the first a label
find('a', title=' name ')
find('a', class_=' name ')
(2).find_all( Return a list )
find_all('a') Find all a
find_all(['a', 'span']) Return all a and span
find_all('a', limit=2) Just the first two a
(3).select( Get the node object from the selector )【 recommend 】
1.element
eg:p
2..class
eg:.firstname
3.#id
eg:#firstname
4. Attribute selector
[attribute]
eg:li = soup.select('li[class]')
[attribute=value]
eg:li = soup.select('li[class="hengheng1"]')
5. Hierarchy selector
element element
div p
element>element
div>p
element,element
div,p
eg:soup = soup.select('a,span')
(1). Get node content : Applicable to the structure of nested labels in labels
obj.string
obj.get_text()【 recommend 】
(2). Properties of a node
tag.name Get the tag name
eg:tag = find('li)
print(tag.name)
tag.attrs Return the property value as a dictionary
(3). Get node properties
obj.attrs.get('title')【 Commonly used 】
obj.get('title')
obj['title']
bs4.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1"> Zhang San </li>
<li id="l2"> Li Si </li>
<li> Wang Wu </li>
<a href="" id="" class="a1">google</a>
<span> Hey, hey, hey </span>
</ul>
</div>
<a href="" title="a2"> Baidu </a>
<div id="d1">
<span>
Ha ha ha
</span>
</div>
<p id="p1" class="p1"> Ha ha ha </p>
</body>
</html>
from bs4 import BeautifulSoup
# By parsing local files to bs4 To explain the basic grammar of
# The encoding format of the default open file is gbk Therefore, you need to specify the code when opening the file
soup = BeautifulSoup(open('bs4.html', encoding='utf-8'), 'lxml')
# Find nodes by tag name
# The first qualified data is found
print(soup.a) # <a class="a1" href="" id="">google</a>
# Gets the properties and property values of the tag
print(soup.a.attrs) # {'href': '', 'id': '', 'class': ['a1']}
# bs4 Some functions of
# (1)find
# The first qualified data is returned
print(soup.find('a')) # <a class="a1" href="" id="">google</a>
# according to title To find the corresponding label object
print(soup.find('a', title="a2")) # <a href="" title="a2"> Baidu </a>
# according to class To find the corresponding label object Pay attention to is class Underline is required
print(soup.find('a', class_="a1")) # <a class="a1" href="" id="">google</a>
# (2)find_all It returns a list And returned all a label
print(soup.find_all('a')) # [<a class="a1" href="" id="">google</a>, <a href="" title="a2"> Baidu </a>]
# If you want to get the data of multiple tags So you need to find_all The data of the list is added to the parameters of the
print(soup.find_all(['a','span'])) # [<a class="a1" href="" id="">google</a>, <span> Hey, hey, hey </span>, <a href="" title="a2"> hundred </a><spa Ha </span>]
# limit The function of is to find the first few data
print(soup.find_all('li', limit=2)) # [<li id="l1"> Zhang San </li>, <li id="l2"> Li Si </li>]
# (3)select( recommend )
# select Method returns a list And multiple data will be returned
print(soup.select('a')) # [<a class="a1" href="" id="">google</a>, <a href="" title="a2"> Baidu </a>]
# Can pass . representative class We call this operation class selector
print(soup.select('.a1')) # [<a class="a1" href="" id="">google</a>]
print(soup.select('#l1')) # [<li id="l1"> Zhang San </li>]
# Attribute selector --- Find the corresponding tag through the attribute
# Find the li There are tags in the tag. id The label of
print(soup.select('li[id]')) # [<li id="l1"> Zhang San </li>, <li id="l2"> Li Si </li>]
# Find the li In the label id by l2 The label of
print(soup.select('li[id="l2"]')) # [<li id="l2"> Li Si </li>]
# Hierarchy selector
# Descendant selector
# What we found was div Below li
print(soup.select('div li')) # [<li id="l1"> Zhang San </li>, <li id="l2"> Li Si </li>, <li> Wang Wu </li>]
# Descendant selector
# The first level sub tag of a tag
# Be careful : In many computer programming languages If you don't add spaces, you won't output content But in bs4 in No mistake. The content will be displayed
print(soup.select('div > ul > li')) # [<li id="l1"> Zhang San </li>, <li id="l2"> Li Si </li>, <li> Wang Wu </li>]
# find a Labels and li All objects of the tag
print(soup.select(
'a,li')) # [<li id="l1"> Zhang San </li>, <li id="l2"> Li Si </li>, <li> Wang Wu </li>, <a class="a1" href="" id="">google</a>, <a href="" title="a2"> Baidu </a>]
# Node information
# Get node content
obj = soup.select('#d1')[0]
# If the label object Content only that string and get_text() You can use
# If the label object In addition to the content, there are labels that string You can't get data and get_text() Yes, you can get data
# We usually Recommended get_text()
print(obj.string) # None
print(obj.get_text()) # Ha ha ha
# Properties of a node
obj = soup.select('#p1')[0]
# name It's the name of the label
print(obj.name) # p
# Return a dictionary around the attribute value to
print(obj.attrs) # {'id': 'p1', 'class': ['p1']}
# Get the properties of the node
obj = soup.select('#p1')[0]
#
print(obj.attrs.get('class')) # ['p1']
print(obj.get('class')) # ['p1']
print(obj['class']) # ['p1']
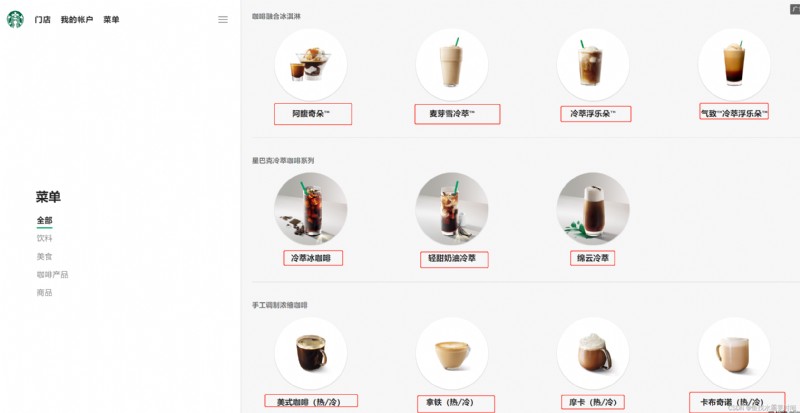
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
# Usually use first xpath Way through google The plug-in writes the parsed expression
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())
Collated from b Station University