In daily work , We often use tasks that need to be performed periodically , One way is to use Linux System native crond Combined with the command line . Another way is to use... Directly Python. The next step is to sort out the common Python Implementation of scheduled tasks .
utilize while True: + sleep() Achieve timed tasks
Use Timeloop The library runs scheduled tasks
utilize threading.Timer Achieve timed tasks
Use built-in modules sched Achieve timed tasks
Using scheduling module schedule Achieve timed tasks
Use the task framework APScheduler Achieve timed tasks
Job Homework
Trigger trigger
Executor actuator
Jobstore Job storage
Event event
Scheduler
APScheduler An important concept in
Scheduler workflow
Using a distributed messaging system Celery Achieve timed tasks
Use data flow tools Apache Airflow Achieve timed tasks
Airflow The background
Airflow The core concept
Airflow The architecture of
be located time Module sleep(secs) function , You can pause the currently executing thread secs Continue in seconds . The so-called pause , That is, the current thread enters the blocking state , When reach sleep() After the time specified by the function , Then it changes from blocking state to ready state , wait for CPU Dispatch .
Based on this feature, we can use while Dead cycle +sleep() The way to achieve a simple scheduled task .
Code example :
import datetime
import time
def time_printer():
now = datetime.datetime.now()
ts = now.strftime('%Y-%m-%d %H:%M:%S')
print('do func time :', ts)
def loop_monitor():
while True:
time_printer()
time.sleep(5) # Pause 5 second
if __name__ == "__main__":
loop_monitor()
Main drawback :
Only the interval can be set , You cannot specify a specific time , Like every morning 8:00
sleep It's a blocking function , in other words sleep This period of time , The program can't do anything .
Timeloop Is a library , Can be used to run multi cycle tasks . This is a simple library , It USES decorator Mode runs marker functions in threads .
Sample code :
import time
from timeloop import Timeloop
from datetime import timedelta
tl = Timeloop()
@tl.job(interval=timedelta(seconds=2))
def sample_job_every_2s():
print "2s job current time : {}".format(time.ctime())
@tl.job(interval=timedelta(seconds=5))
def sample_job_every_5s():
print "5s job current time : {}".format(time.ctime())
@tl.job(interval=timedelta(seconds=10))
def sample_job_every_10s():
print "10s job current time : {}".format(time.ctime())
threading Module Timer Is a non blocking function , Than sleep A little better ,timer The most basic understanding is timer , We can start multiple scheduled tasks , These timer tasks are executed asynchronously , So there is no waiting sequence execution problem .
Timer(interval, function, args=[ ], kwargs={ })
interval: Specified time
function: The method to be executed
args/kwargs: Method parameters
Code example :
remarks :Timer It can only be executed once , Here you need to call , Otherwise, it can only be executed once
sched The module implements a general event scheduler , In the scheduler class, a delay function is used to wait for a specific time , Perform tasks . Support multithreaded applications at the same time , The delay function is called immediately after each task is executed , To ensure that other threads can also execute .
class sched.scheduler(timefunc, delayfunc) This class defines a common interface for scheduling events , It needs to pass in two parameters externally ,timefunc Is a function that returns a time type number without parameters ( Commonly used, such as time In the module time),delayfunc It should be a call that requires a parameter 、 And timefunc The output of is compatible 、 And acts as a function of delaying multiple time units ( Commonly used as time Modular sleep).
Code example :
import datetime
import time
import sched
def time_printer():
now = datetime.datetime.now()
ts = now.strftime('%Y-%m-%d %H:%M:%S')
print('do func time :', ts)
loop_monitor()
def loop_monitor():
s = sched.scheduler(time.time, time.sleep) # Generate scheduler
s.enter(5, 1, time_printer, ())
s.run()
if __name__ == "__main__":
loop_monitor()
scheduler Object main method :
enter(delay, priority, action, argument), Schedule an event to delay delay Time units .
cancel(event): Delete event from queue . If the event is not in the current queue , Then the method will run a ValueError.
run(): Run all scheduled events . This function will wait ( Use the... Passed to the constructor delayfunc() function ), Then execute the event , Until there are no more scheduled events .
Personal comments : Than threading.Timer Better , There is no need to call... In a loop .
schedule It is a third-party lightweight task scheduling module , In seconds , branch , Hours , Date or custom event execution time .schedule Allow users to use simple 、 Humanized syntax runs regularly at predetermined intervals Python function ( Or other callable functions ).
Let's look at the code first , Can you understand what it means without looking at the document ?
import schedule
import time
def job():
print("I'm working...")
schedule.every(10).seconds.do(job)
schedule.every(10).minutes.do(job)
schedule.every().hour.do(job)
schedule.every().day.at("10:30").do(job)
schedule.every(5).to(10).minutes.do(job)
schedule.every().monday.do(job)
schedule.every().wednesday.at("13:15").do(job)
schedule.every().minute.at(":17").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Decorator : adopt @repeat() Decorated static method
import time
from schedule import every, repeat, run_pending
@repeat(every().second)
def job():
print('working...')
while True:
run_pending()
time.sleep(1)
Pass parameters :
import schedule
def greet(name):
print('Hello', name)
schedule.every(2).seconds.do(greet, name='Alice')
schedule.every(4).seconds.do(greet, name='Bob')
while True:
schedule.run_pending()
Decorators can also pass parameters :
from schedule import every, repeat, run_pending
@repeat(every().second, 'World')
@repeat(every().minute, 'Mars')
def hello(planet):
print('Hello', planet)
while True:
run_pending()
Cancel the task :
import schedule
i = 0
def some_task():
global i
i += 1
print(i)
if i == 10:
schedule.cancel_job(job)
print('cancel job')
exit(0)
job = schedule.every().second.do(some_task)
while True:
schedule.run_pending()
Run a task :
import time
import schedule
def job_that_executes_once():
print('Hello')
return schedule.CancelJob
schedule.every().minute.at(':34').do(job_that_executes_once)
while True:
schedule.run_pending()
time.sleep(1)
Retrieve tasks from tags :
# Retrieve all tasks :schedule.get_jobs()
import schedule
def greet(name):
print('Hello {}'.format(name))
schedule.every().day.do(greet, 'Andrea').tag('daily-tasks', 'friend')
schedule.every().hour.do(greet, 'John').tag('hourly-tasks', 'friend')
schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
schedule.every().day.do(greet, 'Derek').tag('daily-tasks', 'guest')
friends = schedule.get_jobs('friend')
print(friends)
Cancel the task according to the label :
# Cancel all tasks :schedule.clear()
import schedule
def greet(name):
print('Hello {}'.format(name))
if name == 'Cancel':
schedule.clear('second-tasks')
print('cancel second-tasks')
schedule.every().second.do(greet, 'Andrea').tag('second-tasks', 'friend')
schedule.every().second.do(greet, 'John').tag('second-tasks', 'friend')
schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
schedule.every(5).seconds.do(greet, 'Cancel').tag('daily-tasks', 'guest')
while True:
schedule.run_pending()
Run the task to a certain time :
import schedule
from datetime import datetime, timedelta, time
def job():
print('working...')
schedule.every().second.until('23:59').do(job) # today 23:59 stop it
schedule.every().second.until('2030-01-01 18:30').do(job) # 2030-01-01 18:30 stop it
schedule.every().second.until(timedelta(hours=8)).do(job) # 8 Stop in an hour
schedule.every().second.until(time(23, 59, 59)).do(job) # today 23:59:59 stop it
schedule.every().second.until(datetime(2030, 1, 1, 18, 30, 0)).do(job) # 2030-01-01 18:30 stop it
while True:
schedule.run_pending()
Run all tasks now ( Mainly used for testing ):
import schedule
def job():
print('working...')
def job1():
print('Hello...')
schedule.every().monday.at('12:40').do(job)
schedule.every().tuesday.at('16:40').do(job1)
schedule.run_all()
schedule.run_all(delay_seconds=3) # Inter task delay 3 second
Run in parallel : Use Python Built in queue implementation :
import threading
import time
import schedule
def job1():
print("I'm running on thread %s" % threading.current_thread())
def job2():
print("I'm running on thread %s" % threading.current_thread())
def job3():
print("I'm running on thread %s" % threading.current_thread())
def run_threaded(job_func):
job_thread = threading.Thread(target=job_func)
job_thread.start()
schedule.every(10).seconds.do(run_threaded, job1)
schedule.every(10).seconds.do(run_threaded, job2)
schedule.every(10).seconds.do(run_threaded, job3)
while True:
schedule.run_pending()
time.sleep(1)
APScheduler(advanceded python scheduler) be based on Quartz One of the Python Timing task framework , Realized Quartz All functions of , It's very convenient to use . Provided based on date 、 Fixed intervals and crontab Type of task , And it can persist tasks . Based on these functions , We can easily implement a Python Timed task system .
It has three characteristics :
Be similar to Liunx Cron The scheduler for ( Optional start / End time )
Execution scheduling based on time interval ( Periodic scheduling , Optional start / End time )
One time mission ( On the set date / Time to run a task )
APScheduler There are four components :
trigger (trigger) Contains scheduling logic , Each job has its own trigger , Used to decide which job will run next . Except for their own initial configuration , Triggers are completely stateless .
Job storage (job store) Store scheduled jobs , The default job store is simply to save jobs in memory , Other job stores store jobs in databases . The data of a job is serialized when it is stored in a persistent job store , And is deserialized on load . The scheduler cannot share the same job store .
actuator (executor) Process the run of the job , They usually submit the specified callable objects to a thread or pool in the job . When the work is done , The actuator will inform the scheduler .
Scheduler (scheduler) It's other components . You usually have only one scheduler in your application , Application developers usually don't deal with job storage directly 、 Scheduler and trigger , contrary , The scheduler provides the right interface to handle this . Configuring job storage and executors can be done in the scheduler , Such as adding 、 Modify and remove jobs . By configuring executor、jobstore、trigger, Use thread pool (ThreadPoolExecutor The default value is 20) Or process pool (ProcessPoolExecutor The default value is 5) And the default is up to 3 individual (max_instances) Task instances are running at the same time , Realize to job Scheduling control such as addition, deletion, modification and query of

Sample code :
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
# Output time
def job():
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# BlockingScheduler
sched = BlockingScheduler()
sched.add_job(my_job, 'interval', seconds=5, id='my_job_id')
sched.start()
Job Homework
Job As APScheduler The smallest execution unit . establish Job Specifies the function to execute when , Required arguments in function ,Job Some setting information during execution .
Build instructions :
id: Specifies the unique name of the job ID
name: Specify the name of the job
trigger:apscheduler Defined trigger , Used to determine the Job Execution time of , By setup trigger The rules , Calculate the next execution of this job Time for , When satisfied, will execute
executor:apscheduler Defined actuators ,job Set the name of the actuator when creating , According to the string, your name goes to scheduler Get to execute this job Of actuator , perform job Specified function
max_instances: Execute this job Maximum number of instances ,executor perform job when , according to job Of id To calculate the number of execution , Determine whether it is executable according to the set maximum number of instances
next_run_time:Job Next execution time , establish Job You can specify a time [datetime], If it is not specified, it defaults to trigger Get trigger time
misfire_grace_time:Job Delayed execution time , for example Job The planned execution time is 21:00:00, However, due to service restart or other reasons 21:00:31 To perform , If you set this key by 40, Then job Will continue to execute , Otherwise, this... Will be discarded job
coalesce:Job Whether to merge execution , It's a bool value . for example scheduler stop it 20s Restart after , and job The trigger for is set to 5s Do it once , So this job Missed 4 Two execution times , If set to yes , Will be merged into one execution , Otherwise, it will be executed one by one
func:Job Executed function
args:Job Position parameters required to execute the function
kwargs:Job Keyword parameters required to execute the function
Trigger trigger
Trigger Bound to the Job, stay scheduler Scheduling filter Job when , Calculate... According to the rules of the trigger Job Trigger time of , Then compare with the current time to determine this Job Whether it will be executed , In short, it is based on trigger The rule calculates the next execution time .
at present APScheduler Support triggers :
Specified time DateTrigger
Specify the interval IntervalTrigger
image Linux Of crontab Same CronTrigger.
Trigger parameters :date
date timing , The job is executed only once .
run_date (datetime|str) – the date/time to run the job at
timezone (datetime.tzinfo|str) – time zone for run_date if it doesn’t have one already
sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text'])
sched.add_job(my_job, 'date', run_date=datetime(2019, 7, 6, 16, 30, 5), args=['text'])
Trigger parameters :interval
interval Interval scheduling
weeks (int) – A few weeks apart
days (int) – A few days apart
hours (int) – A few hours apart
minutes (int) – A few minutes apart
seconds (int) – How many seconds apart
start_date (datetime|str) – Start date
end_date (datetime|str) – End date
timezone (datetime.tzinfo|str) – The time zone
sched.add_job(job_function, 'interval', hours=2)
Trigger parameters :cron
cron Dispatch
(int|str) The parameter can be either int type , It can also be str type
(datetime | str) The parameter can be either datetime type , It can also be str type
year (int|str) – 4-digit year -( Represents a four digit year , Such as 2008 year )
month (int|str) – month (1-12) -( Indicates that the value range is 1-12 month )
day (int|str) – day of the (1-31) -( Indicates that the value range is 1-31 Japan )
week (int|str) – ISO week (1-53) -( Gregorian calendar 2006 year 12 month 31 The day can be written as 2006 year -W52-7( stretched form ) or 2006W527( Compact form ))
day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) – ( Represents the day of the week , You can use 0-6 It can also be expressed by its English abbreviation )
hour (int|str) – hour (0-23) – ( Indicates that the value range is 0-23 when )
minute (int|str) – minute (0-59) – ( Indicates that the value range is 0-59 branch )
second (int|str) – second (0-59) – ( Indicates that the value range is 0-59 second )
start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) – ( Indicates the start time )
end_date (datetime|str) – latest possible date/time to trigger on (inclusive) – ( Indicates the end time )
timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -( Represents the time zone value )
CronTrigger Available expressions :
# 6-8,11-12 The third Friday of the month 00:00, 01:00, 02:00, 03:00 function
sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# Run every Monday to Friday until 2024-05-30 00:00:00
sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2024-05-30'
Executor actuator
Executor stay scheduler In the initialization , In addition, it can also be through scheduler Of add_executor Dynamic addition Executor. Every executor Will be bound to a alias, This is bound as a unique identifier to Job, In actual implementation, it will be based on Job The binding of executor Find the actual actuator object , Then execute... According to the actuator object Job.
Executor The type of will be selected according to different scheduling , If you choose AsyncIO As a scheduling Library , So choose AsyncIOExecutor, If you choose tornado As a scheduling Library , choice TornadoExecutor, If you choose to start the process as the schedule , choice ThreadPoolExecutor perhaps ProcessPoolExecutor Fine .
Executor The choice of needs to be based on the actual scheduler To select different actuators . at present APScheduler Supported by Executor:
executors.asyncio: Sync io, Blocking
executors.gevent:io Multiplexing , Non blocking
executors.pool: Threads ThreadPoolExecutor And processes ProcessPoolExecutor
executors.twisted: Based on event driven
Jobstore Job storage
Jobstore stay scheduler In the initialization , In addition, it can also be through scheduler Of add_jobstore Dynamic addition Jobstore. Every jobstore Will be bound to a alias,scheduler stay Add Job when , According to the designation jobstore stay scheduler Find the corresponding jobstore, And will job Add to jobstore in . Job memory determines how tasks are saved , Stored in memory by default (MemoryJobStore), No more after restart .APScheduler Supported task memories are :
jobstores.memory: Memory
jobstores.mongodb: Stored in mongodb
jobstores.redis: Stored in redis
jobstores.rethinkdb: Stored in rethinkdb
jobstores.sqlalchemy: Support sqlalchemy Database such as mysql,sqlite etc.
jobstores.zookeeper:zookeeper
Different task memories can be configured in the configuration of the scheduler ( See scheduler )
Event event
Event yes APScheduler The corresponding event is triggered when certain operations are performed , Users can customize some functions to listen to these events , When some... Are triggered Event when , Do some specific operations . Common examples are .Job Execute exception event EVENT_JOB_ERROR.Job Execution time miss event EVENT_JOB_MISSED.
at present APScheduler Defined Event:
EVENT_SCHEDULER_STARTED
EVENT_SCHEDULER_START
EVENT_SCHEDULER_SHUTDOWN
EVENT_SCHEDULER_PAUSED
EVENT_SCHEDULER_RESUMED
EVENT_EXECUTOR_ADDED
EVENT_EXECUTOR_REMOVED
EVENT_JOBSTORE_ADDED
EVENT_JOBSTORE_REMOVED
EVENT_ALL_JOBS_REMOVED
EVENT_JOB_ADDED
EVENT_JOB_REMOVED
EVENT_JOB_MODIFIED
EVENT_JOB_EXECUTED
EVENT_JOB_ERROR
EVENT_JOB_MISSED
EVENT_JOB_SUBMITTED
EVENT_JOB_MAX_INSTANCES
Listener Represents some of the user-defined listening Event, For example, when Job Triggered EVENT_JOB_MISSED When an event occurs, you can do some other processing as required .
Scheduler
Scheduler yes APScheduler At the heart of , All relevant components are defined by them .scheduler After starting , Will start scheduling according to the configured tasks . Except according to all definitions Job Of trigger The generated time to be scheduled is outside the wake-up schedule . Happen when Job Scheduling will also be triggered when the information changes .
APScheduler The supported scheduler modes are as follows , The more commonly used is BlockingScheduler and BackgroundScheduler
BlockingScheduler: The scheduler is the only running process in the process , call start Function to block the current thread , Can't go back immediately .
BackgroundScheduler: It is suitable for the scheduler to run in the background of the application , call start The post main thread will not block .
AsyncIOScheduler: Applicable to the use of asyncio Module application .
GeventScheduler: Suitable for use gevent Module application .
TwistedScheduler: For building Twisted Applications for .
QtScheduler: For building Qt Applications for .
Scheduler add to job technological process :

Scheduler Scheduling process :

Celery It's a simple , flexible , Reliable distributed system , Used to process large amounts of messages , At the same time, it provides the necessary tools for the operation to maintain such systems , It can also be used for task scheduling .Celery The configuration of is troublesome , If you just need a lightweight scheduling tool ,Celery It won't be a good choice .
Celery It's a powerful distributed task queue , It allows task execution to be completely separated from the main program , It can even be assigned to run on other hosts . We usually use it for asynchronous tasks (async task) And timing tasks (crontab). Asynchronous tasks, such as sending mail 、 Or file upload , Image processing and other time-consuming operations , A scheduled task is a task that needs to be executed at a specific time .
We need to pay attention to ,celery It does not have the storage function of tasks , When scheduling tasks, you must save the tasks , So in use celery It also needs to be equipped with some storage 、 Tools for accessing functions , such as : Message queue 、Redis cache 、 Database etc. . The official recommendation is message queuing RabbitMQ, Sometimes use Redis It's also a good choice .
Its architecture is shown in the figure below :
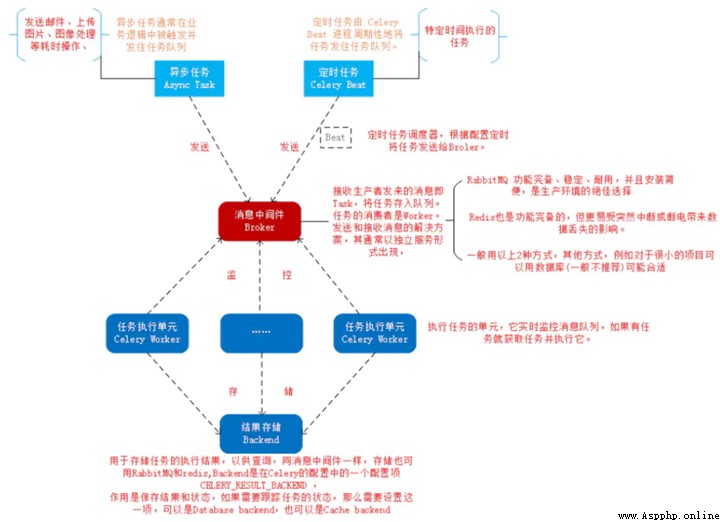
Celery framework , It uses typical producers - Consumer model , It is mainly composed of the following parts :
Celery Beat, Task scheduler ,Beat The process reads the contents of the configuration file , Periodically send the due tasks in the configuration to the task queue .
Producer: Tasks that need to be done in the queue , Usually by the user 、 Triggers or other actions queue tasks , And then leave it to workers To deal with . Called Celery Provided API、 Function or decorator to generate tasks and give them to task queue for processing are all task producers .
Broker, Message middleware , This refers to the task queue itself ,Celery Play the role of producer and consumer ,brokers Producers and consumers / Where to get the product ( queue ).
Celery Worker, The consumer performing the task , Take the task out of the queue and execute . It is common to run multiple consumers on multiple servers to improve execution efficiency .
Result Backend: After the task is processed, the status information and results are saved , For the query .Celery Supported by default Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy Methods such as .
Practical application , User from Web The front end initiates a request , We just need to drop the task to be processed by the request into the task queue broker in , By the idle worker Just deal with the task , The result of processing will be temporarily stored in the background database backend in . We can play multiple... On one or more machines at the same time worker Process to achieve distributed parallel processing tasks .
Celery Examples of timed tasks :
Python Celery & RabbitMQ Tutorial
Celery Configuration practice notes
Apache Airflow yes Airbnb An open source data flow tool , At present, it is Apache Incubation projects . Support the of data in a very flexible way ETL The process , At the same time, it also supports many plug-ins to complete tasks such as HDFS monitor 、 Email notification and other functions .Airflow Support stand-alone and distributed modes , Support Master-Slave Pattern , Support Mesos Wait for resource scheduling , It has very good expansibility . Adopted by a large number of companies .
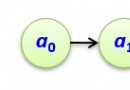
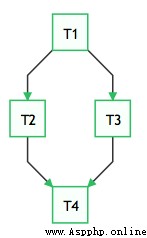
Airflow Use Python Development , It passes through DAGs(Directed Acyclic Graph, Directed acyclic graph ) To express the tasks to be performed in a workflow , And the relationships and dependencies between tasks . such as , In the following workflow , Mission T1 Execution completed ,T2 and T3 To start execution ,T2 and T3 All completed ,T4 To start execution .
Airflow A variety of Operator Realization , Can complete a variety of tasks to achieve :
BashOperator – perform bash Command or script .
SSHOperator – Perform remote bash Command or script ( The principle is the same as paramiko modular ).
PythonOperator – perform Python function .
EmailOperator – send out Email.
HTTPOperator – Send a HTTP request .
MySqlOperator, SqliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, JdbcOperator, etc. , perform SQL Mission .
DockerOperator,HiveOperator,S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator…
In addition to the above Operators You can also easily customize Operators Meet the needs of personalized tasks .
In some cases , We need to perform different tasks according to the execution results , In this way, the workflow will generate branches . Such as :
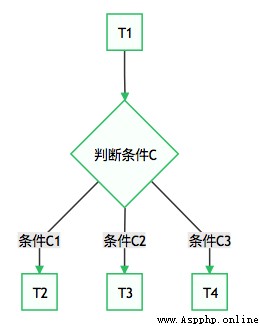
This requirement can be used BranchPythonOperator To achieve .
Usually , In an O & M system , data analysis system , Or test system , We will have all kinds of dependency needs . Including but not limited to :
Time dependence : The task needs to wait for a certain point in time to trigger .
External system dependencies : Tasks depend on external systems and need to call interfaces to access .
Inter task dependency : Mission A Need to be in the task B Start after completion , The two tasks will have an impact on each other .
Resource environment dependence : Tasks consume a lot of resources , Or it can only be executed on a specific machine .
crontab It can well deal with the need to execute tasks regularly , But it can only manage time dependence .Airflow Core concept of DAG( Directed acyclic graph )—— To represent workflow .
Airflow It's a kind of WMS, namely : It treats tasks and their dependencies as code , Follow those plans to standardize the task , And distribute the tasks to be performed between the actual work processes .
Airflow Provides an excellent tool for displaying the status of current active tasks and past tasks UI, It also allows users to manually manage the execution and status of tasks .
Airflow Workflow in is a collection of tasks with directional dependence .
DAG Each node in the is a task ,DAG The edges in represent dependencies between tasks ( Force to directed acyclic , Therefore, there will be no circular dependencies , This results in an infinite execution loop ).
DAGs: The directed acyclic graph (Directed Acyclic Graph), All that needs to be run tasks Organized according to dependencies , It describes all tasks Execution order .
Operators: It can be simply understood as a class, It describes DAG One of the task Specific things to do . among ,airflow Built in a lot operators, Such as BashOperator Execute one bash command ,PythonOperator Call any Python function ,EmailOperator For sending mail ,HTTPOperator Used for sending HTTP request , SqlOperator Used to perform SQL Orders, etc , meanwhile , Users can customize it Operator, This provides users with great convenience .
Tasks:Task yes Operator An example of , That is to say DAGs One of them node.
Task Instance:task A run of .Web You can see task instance It has its own state , Include ”running”, “success”, “failed”, “skipped”, “up for retry” etc. .
Task Relationships:DAGs Different in Tasks There can be dependencies between , Such as Task1 >> Task2, indicate Task2 Depend on Task2 了 . By way of DAGs and Operators Combine , Users can create all kinds of complex workflow (workflow).
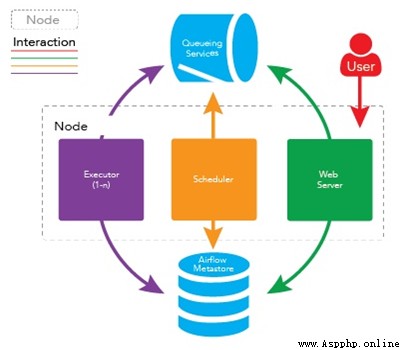
In a scalable production environment ,Airflow Contains the following components :
Meta database : This database stores information about the status of tasks .
Scheduler :Scheduler It's a use DAG Define the process of determining which tasks need to be executed and the priority of task execution according to the task status in metadata . The scheduler usually runs as a service .
actuator :Executor Is a message queuing process , It's bound to the scheduler , The work process used to determine the actual execution of each task plan . There are different types of actuators , Each executor uses a class that specifies the work process to perform the task . for example ,LocalExecutor Use a parallel process running on the same machine as the scheduler process to perform tasks . Other images CeleryExecutor The executor of the uses work processes that exist in a separate cluster of work machines to perform tasks .
Workers: These are the processes that actually execute the task logic , Determined by the actuator in use .
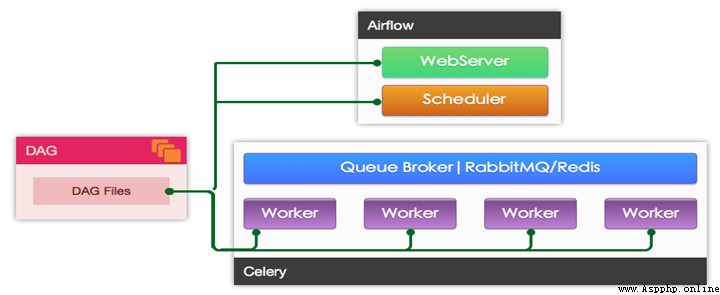
Worker The specific implementation of the configuration file consists of executor To specify the ,airflow Support for multiple Executor:
SequentialExecutor: Single process sequential execution , Generally only used to test
LocalExecutor: Local multiprocess execution
CeleryExecutor: Use Celery Distributed task scheduling
DaskExecutor: Use Dask Distributed task scheduling
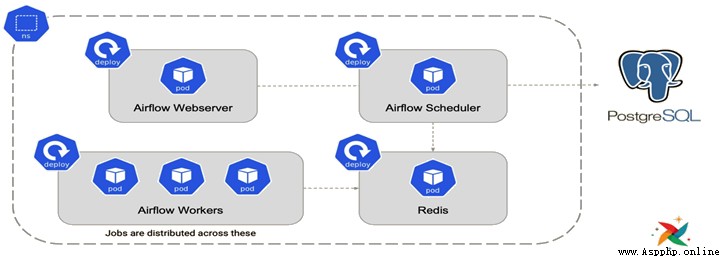
KubernetesExecutor: 1.10.0 newly added , Create a temporary POD Perform each task
The production environment generally uses CeleryExecutor and KubernetesExecutor.
Use CeleryExecutor The structure of is as shown in the figure :
Use KubernetesExecutor The structure of is as shown in the figure :
Other references :
Getting started with Apache Airflow
Understanding Apache Airflow’s key concepts
【python Study 】
learn Python The partners , Welcome to join the new exchange 【 Junyang 】:1020465983
Discuss programming knowledge together , Become a great God , There are also software installation packages in the group , Practical cases 、 Learning materials