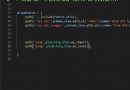
# coding=utf-8
import json
import pandas as pd
import requests
def detail(page_num):
heads = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'} # Request header
url = 'https://static-data.gaokao.cn/www/2.0/special/%s/pc_special_detail.json'#Url
d2 = pd.DataFrame()
# Page crawling 10 individual , Need to be right pandas Installation pip install openpyxl
for i in range(1,page_num):
response = requests.get(url % (i), headers=heads)
if response!=None:
json_data = json.loads(response.text)
my_json = json_data['data'] # get josn The root directory of the data
df3 = pd.DataFrame({#d Yes my_json File in
'id':my_json['id'],
'name':my_json['name'],
' Content ':my_json['content'],
' Work ':my_json['job'],
'code':my_json['code'],
'degree':my_json['degree'],
' Years ':my_json['limit_year'],
' The male to female ratio ':my_json['rate'],
'type':my_json['type'],
'type_detail':my_json['type_detail']
}, index=[0])
d2 = d2.append(df3, ignore_index=True)
print(d2)
d2.to_excel("major.xlsx", index=False)
detail(5)
————————————————
Copyright notice : This paper is about CSDN Blogger 「 Spiral watermelon 」 The original article of , follow CC 4.0 BY-SA Copyright agreement , For reprint, please attach the original source link and this statement .
Link to the original text :https://blog.csdn.net/weixin_45208256/article/details/124950788