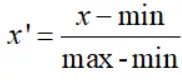有時候在進行匯總計算時,我們需要將處理前的數據轉換為處理後的數據。
處理前: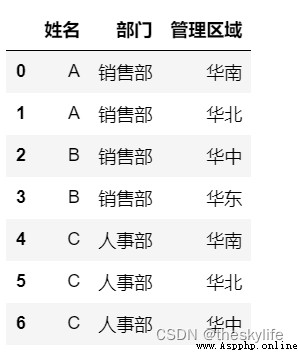
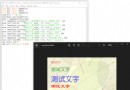
處理後: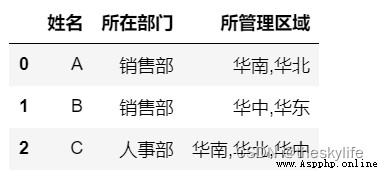
提前做好數據准備工作:
import pandas as pd
#准備數據
df = pd.DataFrame({
'姓名': ['A', 'A', 'B', 'B', 'C', 'C', 'C'],
'部門':['銷售部', '銷售部', '銷售部', '銷售部', '人事部', '人事部', '人事部'],
'管理區域':['華南', '華北', '華中', '華東', '華南', '華北', '華中']})
df
result=df.groupby(df['姓名']).agg(所在部門=('部門',lambda x:','.join(x.unique())),
所管理區域=('管理區域',lambda x:','.join(x.unique()))).reset_index()
按照2.1裡的方法我們就可以達到預期,但是當聚合的字段非常多的時候,我們就要面臨寫多個匿名函數的麻煩,不是很方便,那麼該如何解決這個問題?
def string_concat(column_name,sep=','):
return sep.join(column_name.unique())
result=df.groupby(df['姓名']).agg(所在部門=('部門',string_concat),
所管理區域=('管理區域',string_concat)).reset_index()
result
基於2.2我們解決了重復寫匿名函數的麻煩,但實際情況中,如果我們對多列采取不同的分隔符時,又不是很人性化,那又該如何解決這一問題?
def custome_str_cat(sep='|'):
def str_cat(column_name):
return sep.join(column_name.unique())
if sep:
return str_cat
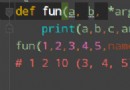
result=df.groupby(df['姓名']).agg(所在部門=('部門', custome_str_cat('*')), 所管理區域=('管理區域',
custome_str_cat()), 所管理區域2=('管理區域', custome_str_cat('—'))).reset_index()
實現後效果圖如下: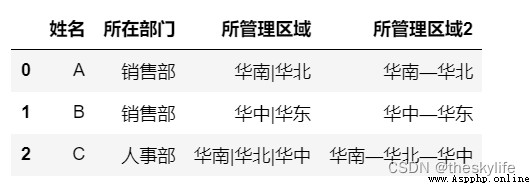
以上就是關於文本類的聚合函數,相當於postgresql數據庫中的string_agg函數,Oracle中的wm_concat函數,MySQL中的GROUP_CONCAT函數。那麼如何在pandas中將一行轉為多行?即將本篇文章中處理後的數據轉為處理前的數據,可以參考本篇博客,傳送門:https://blog.csdn.net/qq_41780234/article/details/121623812?spm=1001.2014.3001.5502