python編程規范 PEP8
pycharm 格式化 ctrl + alt + l,可以在這裡看到一些常用的快捷鍵
多行注釋’‘’ 注釋內容 ‘’’
python是弱語言,變量聲明的時候對數據類型不是很嚴格
格式:變量名 = 值
python建議變量名用下劃線
type()查看數據類型
python中變量名更建議用下劃線分割單詞:變量名,函數名和文件名全小寫,使用下劃線連接; 類名遵守大駝峰命名法; 常量名全大寫;
對於字符串,單引號,雙引號都可以,三引號也可以(賦值符號後面)
為什麼要有三種形式來表示字符串呢
是為了嵌套引號的時候進行區分
例如 m = " sdfsdf’dfsdf’"
三引號是為了輸出保持格式: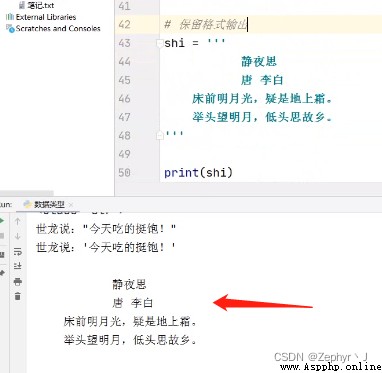
python輸入的類型都是字符串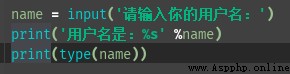

# 浮點型直接轉整型沒問題,小數點後的數字被忽略
a = 9.9
print(int(a)) # 9
# 如果是字符串轉成整型就會有問題
a = '9.9'
print(int(a)) # 報錯
# 字符串轉float可以
a = '9.9'
print(float(a))
# True轉整型對應是1,False是0
# True轉浮點型是1.0,False是0.0
# 布爾轉字符串直接變成字符串
# 只要不是0的數轉換成布爾型bool都是true
# 空字符串轉('')換成bool是False
print(bool(''))
print(bool(""))
print(bool(0))
print(bool({
}))
print(bool([]))
print(bool(()))
print(bool(None))
# 都是false
# 指定輸出中的間隔符號
print(1,2,3,sep='#')
# 輸出結果
# 1#2#3
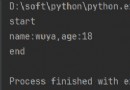
end表示結果加什麼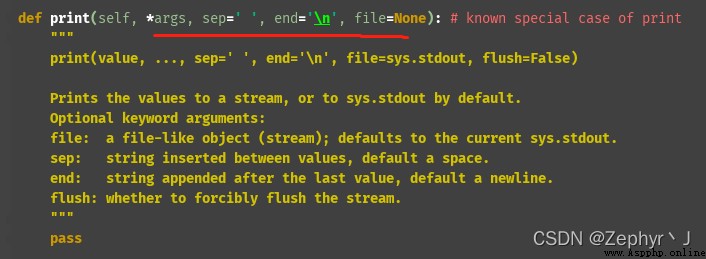
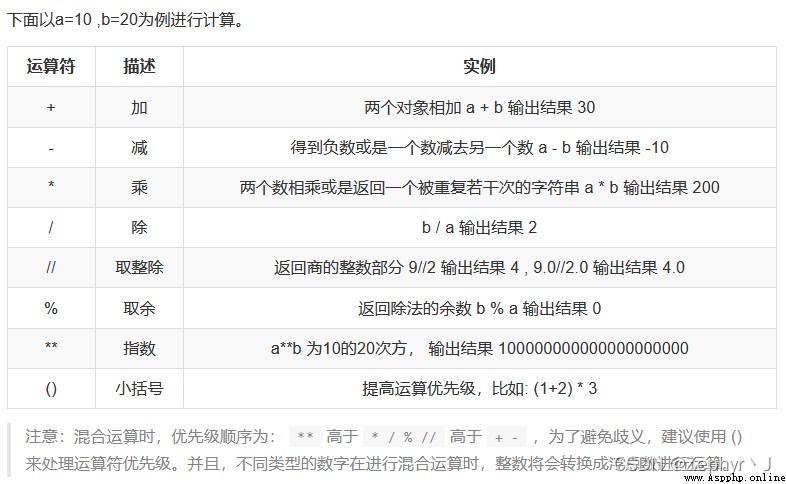
# 多個變量賦值(使用逗號分隔)
>>> num1, f1, str1 = 100, 3.14, "hello"
>>> num1
100
>>> f1
3.14
>>> str1
"hello"
數字和字符串做==運算結果是false,除了 == 以外的邏輯運算時,會直接報錯。
如果是兩個字符串進行比較,會將每個字符都轉換成對應的編碼,然後逐一進行對比。
print(80<=90<100) # True
這裡需要注意,當有很多邏輯運算符連接時,需要注意取的是哪一個值
因為這裡取邏輯時,也是短路與或者短路或,所以是取最後一個成立的值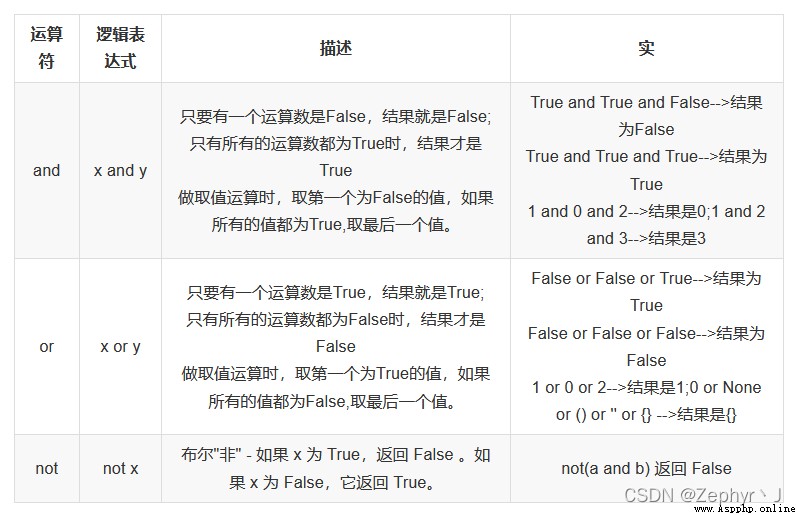
a = 1
b = 3
print(a and b) # 輸出3,取後面的值
print(a or b) # 輸出1,取前面的值
c = 0
print(c and a) # 輸出0
a = 34
a > 10 and print('hello world') # 有輸出
a < 10 and print('hello world') # 無輸出
a >10 or print('你好世界') # 無輸出
a <10 or print('你好世界') # 有輸出

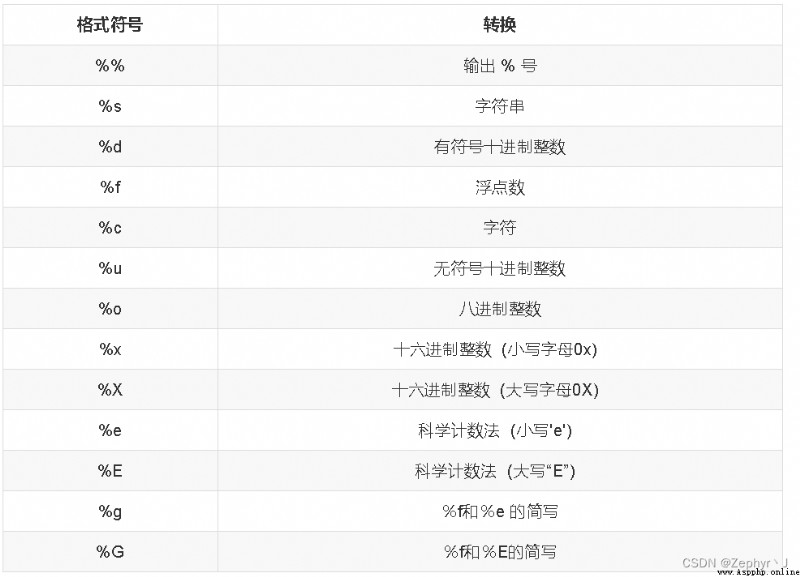
關於格式化輸出,保留多少位小數輸出
money = 99.56
print('我掙了%f塊錢' %money)
# out: 我掙了99.560000塊錢
# 可以看到這裡有很多不必要的零
print('我掙了%.2f塊錢' %money)
# 這裡會五捨六入
money = 99.55
print('我掙了%.1f塊錢' %money)
# 我掙了99.5塊錢
money = 99.56
print('我掙了%.1f塊錢' %money)
# 我掙了99.6塊錢
bin(),oct(),hex()
0b,0o,0x
# 轉二進制
n = 149
r = bin(n)
print(r) # 0b10010101
# 轉8進制
r = oct(n)
print(r) # 0o225
# 轉16進制
r = hex(n)
print(r) # 0x95
# 默認輸出十進制
n = 0x558
print(oct(n)) # 0o2530
# 或者用int轉換
r = int(n) # 1368
這裡需要注意左移不會溢出,會一直變大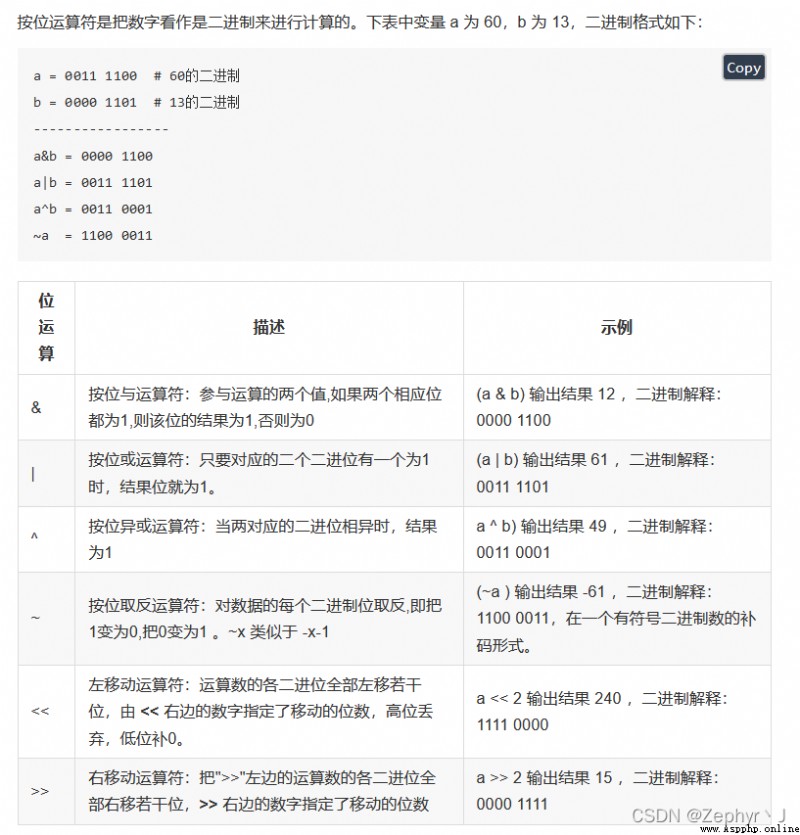
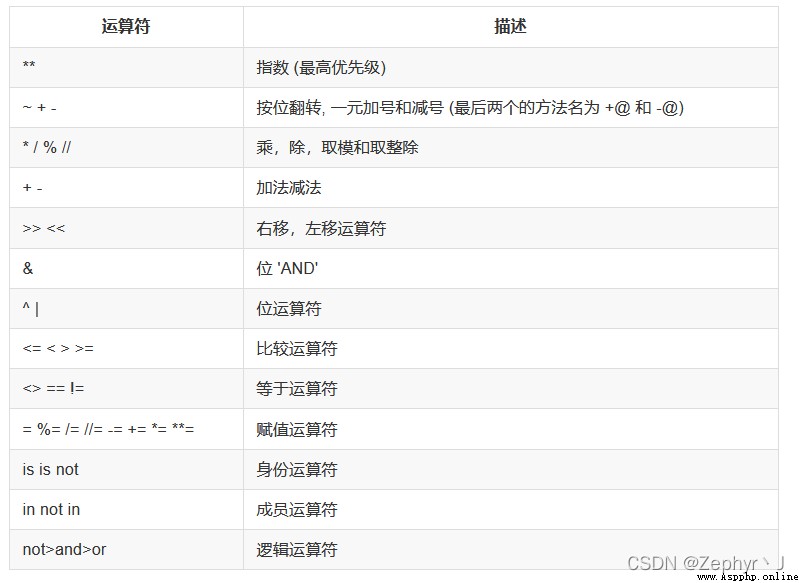
random.randint(1, 10) 產生1到10的隨機數(1和10都包含)
pass關鍵字 是為了支撐結構,比如if寫了條件沒寫內容會報錯,稱為坍塌的結構,寫個pass就可以支撐起這個結構,不至於報錯
在Python中允許類似於 5<a<10 的寫法
在Python中,轉換成為布爾值時,只有 0,“”,‘’,None,(),{},[] 會被轉換成為False,其他都會被轉換成為True
三元運算符
a = 10
b = 30
c = a if a>b else b
相當於
a = 10
b = 30
if a > b:
c = a
else:
c = b
while / for
在Python中 for循環可以遍歷任何序列的項目,如一個列表或者一個字符串等。
for循環格式:
for 臨時變量 in 列表或者字符串等可迭代對象:
循環滿足條件時執行的代碼
range 可以生成數字供 for 循環遍歷,它可以傳遞三個參數,分別表示 起始、結束和步長。
包含起始位置,不包含結束的數值
默認是從0開始的,默認步長是1
>>> range(2, 10, 3)
[2, 5, 8]
>>> for x in range(2, 10, 3):
... print(x)
...
2
5
8
在Python中,break和continue只能用於循環語句中。
break和continue在嵌套循環中使用時,只對最內層循環有效。
在Python中,循環語句還可以和else語句聯合使用
while 判斷條件:
條件成立時,循環體代碼
else:
如果循環一直沒有被中斷,才會被執行;如果執行中跳出了,那麼這裡不會被執行
從上述結構中,我們可以看出,在非死循環中,正常情況下else裡的語句都是會被執行的。那這個else語句到底有什麼作用呢?一般情況下,循環語句和else共同出現時,在循環語句裡都會配合break語句來使用。
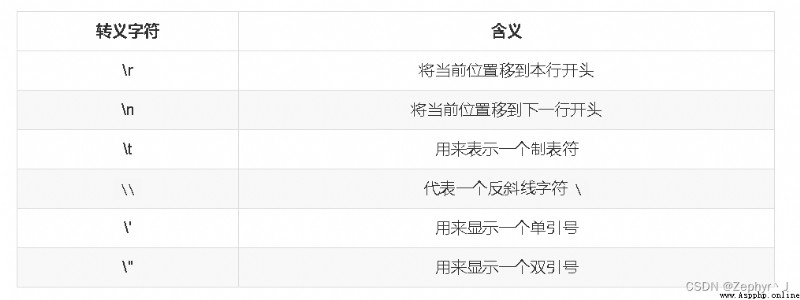
\r表示回退回本行開頭,打印後面的內容
print("abcd\r efg")
-----
print("abcd\n efg")
輸出:
efg
-----
abcd
efg
獲取地址的函數 id()
is 運算符比較的是地址
從下面例子可以看出,相同字符串共用內存,相當於java中的字符串常量池
s1 = 'hello'
s2 = s1
s3 = 'hello'
print(id(s1))
print(id(s2))
print(id(s3))
print(s1 is s2)
s1 = 'word'
print(s1, s2, s3)
輸出:
2035658937544
2035658937544
2035658937544
True
word hello hello
字符串索引可以從前往後,從0開始到len(s) - 1
可以從後往前,從-len(s)開始到-1
切片是指對操作的對象截取其中一部分的操作。字符串、列表、元組都支持切片操作。
切片的語法:[起始:結束:步長],也可以簡化使用 [起始:結束]
注意:選取的區間從"起始"位開始,到"結束"位的前一位結束(不包含結束位本身),步長表示選取間隔,也可以控制方向,負數表示從右向左取。
find查找指定內容在字符串中是否存在,如果存在就返回該內容在字符串中第一次出現的開始位置索引值,如果不存在,則返回-1.
語法格式:([]是可以加的內容)
S.find(sub[, start[, end]]) -> int
end同樣不會被包括
mystr = '今天天氣好晴朗,處處好風光呀好風光'
id_f = mystr.find('風') # 11
print(mystr.find('好風光')) # 10 '好風光'第一次出現時,'好'所在的位置
print(mystr.find('你好')) # -1 '你好'不存在,返回 -1
print(mystr.find('風', 12)) # 15 從下標12開始查找'風',找到風所在的位置試15
print(mystr.find('風', 11)) # 11 從下標12開始查找'風',找到風所在的位置試11
print(mystr.find('風',0,id_f)) # -1 從下標0開始到10查找"風", 未找到,返回 -1
rfind是從右往左找
index跟find()方法一樣,只不過,find方法未找到時,返回-1,而str未找到時,會報一個異常。
startswith判斷字符串是否以指定內容開始。 語法格式:
S.startswith(prefix[, start[, end]]) -> bool
isalpha判斷字符串是否是純字母。
isdigit判斷一個字符串是否是純數字,只要出現非0~9的數字,結果就是False.
isalnum判斷是否由數字和字母組成。只要出現了非數字和字母,就返回False.
isspace如果 mystr 中只包含空格,則返回 True,否則返回 False.
isupper 判斷字符串中的字母是否全部是大寫字母
islower 判斷字符串中的字母是否全部是小寫字母,如下
s = "123dddd"
print(s.islower()) # True
返回 str在start和end之間 在 mystr裡面出現的次數。
語法格式:
S.count(sub[, start[, end]]) -> int
替換字符串中指定的內容,如果指定次數count,則替換不會超過count次。
replace(old, new, count)
mystr = '今天天氣好晴朗,處處好風光呀好風光'
newstr = mystr.replace('好', '壞')
print(mystr) # 今天天氣好晴朗,處處好風光呀好風光 原字符串未改變!
print(newstr) # 今天天氣壞晴朗,處處壞風光呀壞風光 得到的新字符串裡,'好'被修改成了'壞'
newstr = mystr.replace('好','壞',2) # 指定了替換的次數
print(newstr) # 今天天氣壞晴朗,處處壞風光呀好風光 只有兩處的'好'被替換成了'壞'
如果一次要替換兩個詞,可以通過1.正則表達式來處理 2.循環+列表
內容分隔主要涉及到split,rsplit, splitlines,partition和rpartition四個方法。
split(‘分隔符’, maxsplit) 返回結果是一個列表,切maxsplit刀
splitlines按照行分隔,返回一個包含各行作為元素的列表。
partition把mystr以str分割成三部分,str前,str和str後,三部分組成一個元組
mystr = '今天天氣好晴朗,處處好風光呀好風光'
print(mystr.partition('好')) # ('今天天氣', '好', '晴朗,處處好風光呀好風光')
修改大小寫的功能只對英文有效,主要包括,首字母大寫capitalize,每個單詞的首字母大寫title,全小寫lower,全大寫upper.
常用的是strip,去除左右兩邊的空格
ljust返回指定長度的字符串,並在右側使用空白字符補全(左對齊)。
str = 'hello'
print(str.ljust(10)) # hello 在右邊補了五個空格
rjust返回指定長度的字符串,並在左側使用空白字符補全(右對齊)。
str = 'hello'
print(str.rjust(10)) # hello在左邊補了五個空格
center返回指定長度的字符串,並在兩端使用空白字符補全(居中對齊)
str = 'hello'
print(str.center(10)) # hello 兩端加空格,讓內容居中
lstrip刪除 mystr 左邊的空白字符。
mystr = ' he llo '
print(str.lstrip()) #he llo 只去掉了左邊的空格,中間和右邊的空格被保留
rstrip刪除 mystr 右邊的空白字符。
mystr = ' he llo '
print(str.rstrip()) # he llo右邊的空格被刪除
strip刪除兩斷的空白字符。
str = ' he llo '
print(str.strip()) #he llo
把參數進行遍歷,取出參數裡的每一項,然後再在後面加上mystr
語法格式:
S.join(iterable)
示例:
mystr = 'a'
print(mystr.join('hxmdq')) #haxamadaq 把hxmd一個個取出,並在後面添加字符a. 最後的 q 保留,沒有加 a
print(mystr.join(['hi','hello','good'])) #hiahelloagood
作用:可以把列表或者元組快速的轉變成為字符串,並且以指定的字符分隔。
txt = '_'
print(txt.join(['hi','hello','good'])) #hi_hello_good
print(txt.join(('good','hi','hello'))) #good_hi_hello
簡單字段名由三中寫法:
省略字段名:{}
使用非負十進制整數{0}
變量名{name}
大括號內省略字段名,傳遞位置參數。
替換字段形式: {}
注意:大括號個數可以少於位置參數的個數,反之不然。
# 省略字段名傳遞位置參數
print('我叫{},今年{}歲。'.format('小明', 18))
""" 我叫小明,今年18歲。 """
# 大括號個數可以少於位置參數的個數
print('我愛吃{}和{}。'.format('香蕉', '蘋果', '大鴨梨'))
""" 我愛吃香蕉和蘋果。 """
# 大括號個數多於位置參數的個數則會報錯
# print('我還吃{}和{}。'.format('西紅柿'))
""" IndexError: tuple index out of range """
可以通過數字形式的簡單字段名傳遞位置參數。
數字必須是大於等於 0 的整數。
帶數字的替換字段可以重復使用。
數字形式的簡單字段名相當於把 format 中的所有位置參數整體當作一個元組,通過字段名中的數字進行取值。即 {0} 等價於 tuple[0],所以大括號內的數字不能越界。
# 通過數字形式的簡單字段名傳遞位置參數
print('身高{0},家住{1}。'.format(1.8, '銅鑼灣'))
""" 身高1.8,家住銅鑼灣 """
# 數字形式的簡單字段名可以重復使用。
print('我愛{0}。\n她今年{1}。\n我也愛{0}。'.format('阿香', 17))
""" 我愛阿香。 她今年17。 我也愛阿香。 """
# 體會把所有位置參數整體當成元組來取值
print('阿香愛吃{1}、{3}和{0}。'.format(
'榴蓮', '臭豆腐', '皮蛋', '鲱魚罐頭', '螺獅粉'))
""" 阿香愛吃臭豆腐、鲱魚罐頭和榴蓮。 """
# 嘗試一下越界錯誤
# print('{1}'.format('錯誤用法'))
""" IndexError: tuple index out of range """
使用變量名形式的簡單字段名傳遞關鍵字參數。
關鍵字參數的位置可以隨意調換。
# 使用變量名形式的簡單字段名傳遞關鍵字參數
print('我大哥是{name},今年{age}歲。'.format(name='阿飛', age=20))
""" 我大哥是阿飛,今年20歲。 """
# 關鍵字參數的順序可以隨意調換
print('我大哥是{name},今年{age}歲。'.format(age=20, name='阿飛'))
""" 我大哥是阿飛,今年20歲。 """
混合使用數字形式和變量名形式的字段名,可以同時傳遞位置參數和關鍵字參數。
關鍵字參數必須位於位置參數之後。
混合使用時可以省略數字。
省略字段名 {} 不能和數字形式的字段名 {非負整數} 同時使用。
# 混合使用數字形式和變量名形式的字段名
# 可以同時傳遞位置參數和關鍵字參數
print('這是一個關於{0}、{1}和{girl}的故事。'.format(
'小明', '阿飛', girl='阿香'))
""" 這是一個關於小明、阿飛和阿香的故事。 """
# 但是關鍵字參數必須位於位置參數之後
# print('這是一個關於{0}、{1}和{girl}的故事。'.format(
# '小明', girl='阿香' , '阿飛'))
""" SyntaxError: positional argument follows keyword argument """
# 數字也可以省略
print('這是一個關於{}、{}和{girl}的故事。'.format(
'小明', '阿飛', girl='阿香'))
# 但是省略字段名不能和數字形式的字段名同時出現
# print('這是一個關於{}、{1}和{girl}的故事。'.format(
# '小明', '阿飛', girl='阿香'))
""" ValueError: cannot switch from automatic field numbering to manual field specification """
str.format() 方法還可以使用 *元組 和 **字典 的形式傳參,兩者可以混合使用。 位置參數、關鍵字參數、*元組 和 **字典 也可以同時使用,但是要注意,位置參數要在關鍵字參數前面,*元組 要在 **字典 前面。
# 使用元組傳參
infos = '鋼鐵俠', 66, '小辣椒'
print('我是{},身價{}億。'.format(*infos))
""" 我是鋼鐵俠,身家66億。 """
print('我是{2},身價{1}億。'.format(*infos))
""" 我是小辣椒,身家66億。 """
# 使用字典傳參
venom = {
'name': '毒液', 'weakness': '火'}
print('我是{name},我怕{weakness}。'.format(**venom))
""" 我是毒液,我怕火。 """
# 同時使用元組和字典傳參
hulk = '綠巨人', '拳頭'
captain = {
'name': '美國隊長', 'weapon': '盾'}
print('我是{}, 我怕{weapon}。'.format(*hulk, **captain))
print('我是{name}, 我怕{1}。'.format(*hulk, **captain))
""" 我是綠巨人, 我怕盾。 我是美國隊長, 我怕拳頭。 """
# 同時使用位置參數、元組、關鍵字參數、字典傳參
# 注意:
# 位置參數要在關鍵字參數前面
# *元組要在**字典前面
tup = '鷹眼',
dic = {
'weapon': '箭'}
text = '我是{1},我怕{weakness}。我是{0},我用{weapon}。'
text = text.format(
*tup, '黑寡婦', weakness='男人', **dic)
print(text)
""" 我是黑寡婦,我怕男人。我是鷹眼,我用箭。 """
同時使用了數字和變量名兩種形式的字段名就是復合字段名。
復合字段名支持兩種操作符:
. 點號
[] 中括號
傳遞位置參數
替換字段形式:{數字.屬性名}
只有一個替換字段的時候可以省略數字
class Person(object):
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
p = Person('zhangsan',18,'female')
print('姓名是{0.name},年齡是{0.age},性別是{0.gender}'.format(p))
print('姓名是{.name}'.format(p)) # 只有一個替換字段時,可以省略數字
用列表傳遞位置參數
用元組傳遞位置參數
用字典傳遞位置參數
# 中括號用法:用列表傳遞位置參數
infos = ['阿星', 9527]
food = ['霸王花', '爆米花']
print('我叫{0[0]},警號{0[1]},愛吃{1[0]}。'.format(
infos, food))
""" 我叫阿星,警號9527,愛吃霸王花。 """
# 中括號用法:用元組傳遞位置參數
food = ('僵屍', '腦子')
print('我叫{0[0]},年齡{1},愛吃{0[1]}。'.format(
food, 66))
""" 我叫僵屍,年齡66,愛吃腦子。 """
# 中括號用法:用字典傳遞位置參數
dic = dict(name='阿星', pid=9527)
print('我是{[name]}!'.format(
dic))
# 多個替換字段,不能省略數字
print('我是{0[name]},警號{0[pid]}。'.format(
dic))
""" 我是阿星! 我是阿星,警號9527。 """
轉換字段 conversion field 的取值有三種,前面要加 !:
s:傳遞參數之前先對參數調用 str()
r:傳遞參數之前先對參數調用 repr()
a:傳遞參數之前先對參數調用 ascii()
ascii() 函數類似 repr() 函數,返回一個可以表示對象的字符串。 但是對於非 ASCII 字符,使用 \x,\u 或者 \U 轉義。
# 轉換字段
print('I am {!s}!'.format('Bruce Lee 李小龍'))
print('I am {!r}!'.format('Bruce Lee 李小龍'))
print('I am {!a}!'.format('Bruce Lee 李小龍'))
""" I am Bruce Lee 李小龍! I am 'Bruce Lee 李小龍'! I am 'Bruce Lee \u674e\u5c0f\u9f99'! """