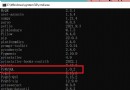
Here are three sets of code :
# The first group :
>>>a=256
>>>b = 256
>>>a is b
# The second group :
>>>a = 257
>>>b = 257
>>>a is b
# The third group :
>>>a = 257; b = 257
>>>a is b
The problem is coming. , What are the results of these three groups of code ?
The answer is True、False and True. The first and third results were True That seems fine , So why is the result of the second group False Well ?
Use it here first id() Let's have a look at a and b What's the address of :(https://jq.qq.com/?_wv=1027&k=aLlhPAxB)
# The first group :
>>>id(a)
>>>1426657040
>>>id(b)
>>>1426657040
# The second group :
>>>id(a)
>>>363389616
>>>id(b)
>>>363392912
# The third group :
>>>id(a)
>>>5722000
>>>id(b)
>>>5722000
You can see the first group and the third group a and b Of id The values are the same , But the second group is different . This is because Python To avoid duplicate creation and recycling , Just cache the commonly used integers , Take it directly from the cache every time you need to use it , Instead of recreating , The range of these integers is [-5, 256], Numbers that are not in this range are going to be recreated .
Then why the third group a and b It's the same ?(https://jq.qq.com/?_wv=1027&k=aLlhPAxB)
This is because Python Internal optimization , For code in the same code block , If two integers with the same value appear , Then they will be reused . Here you can test it with the following code :
a = 257
b = 257
def func():
c = 257
print(a is c) # False
print(a is b) # True
func()
In this code a and b Of id The value is the same , and c Of id Values are different . This is because a and b In the same code block , and c be in func In the function , It's a local variable , and a Not in the same code block . So in creating c It will recreate , But creating b When it's time to reuse a This object .
stay Python On the interactive command line , Each single line is treated as a block of code , So... In group three a and b In the same code block , So the latter reuses the former , therefore , two-variable id It's the same .
We all know... In regular expressions re.sub() It's for string substitution , such as :
import re
def remove_tag(html):
text = re.sub('<.*?>', '', html, re.S)
return text
The function of this code is to html All tags in are replaced with empty , There's nothing to say , You can use a paragraph here html Code to test :
html = """
<!DOCTYPE html><html lang="en">
<head><meta charset="UTF-8">
<title>Document</title>
</head><body></body></html>
"""
print(remove_tag(html))
# Document
The results are the same as we thought , But if html The code is a little longer ? For example, below :
html = """
<!Dtp-equiv="X-UA-Compatible" content="ie=edge"><title>Document</title>
</head><bodOCTYPE html><html lang="en"><head><meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta hty><h1>h1 title </h1><h2>h2 title </h2><h3>h3 title </h3></body></html>
"""
print(remove_tag(html))
The operation results are as follows :
Document
h1 title h2 title h3 title </body></html>
Why will there be more in the end ? Shouldn't these two labels be replaced ? The problem lies in re.sub() The fourth parameter of , Let's take a look here sub() Prototypes of functions :
re.sub(pattern, repl, string, count=0, flags=0)
Then why do we put re.S Put it in count There's no mistake about the location of ? Do I mean re.S It's a number ? Print it out and have a look :
import re
print(re.S)
# 16
original re.S It can also be used as a number ! Now count the upper part html Number of tags in the code , The discovery is the first 17 And the 18 individual , And because re.S Be treated as 16 Pass to count Parameters , So the last two tags are not replaced .

I believe many people have used lstrip(), Useful when dealing with strings , such as :
print("aabbcc".lstrip('aa'))
# bbcc
It's very simple , No problem , But look at the following example :
print("ababacac".lstrip("ab"))
# cac
Why didn't it turn out to be acac Well ?
This is because when lstrip() After passing in a string ,lstrip() Will break this string into characters , Then check it from left to right , Delete if it matches , Until the first different character appears , So finally ababa Has been deleted , The result is cac 了 . To avoid this situation , It can be used replace() Method to replace .
If you want to create a list with three empty lists , What would you do ?
'''
No one answers the problems encountered in learning ? Xiaobian created a Python Exchange of learning QQ Group :660193417###
Looking for small partners who share the same aspiration , Help each other , There are also good video tutorials and PDF e-book !
'''
# Options 1
li =[[] for i in range(3)]
# Options 2
li = [[]*3]
# Options 3
li = [[]]*3
If you run , You'll know the options 1 And options 3 To get the results we want . Now run the following code again :
li = [[]]*3
li[0].append(1)
print(li)
# [[1], [1], [1]]
Why do we add only one... To the first list 1, But the other two lists also add one 1 Well ? This is because [[]]*3 It's not that three different lists have been created , Instead, three objects pointing to the same list are created , therefore , When we operate on the first list , The other two lists also change .