說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔+視頻講解),如需數據+代碼+文檔+視頻講解可以直接到文章最後獲取。
1.項目背景
房價問題已經成為中國社會關注的焦點問題。現階段中國房價為什麼上漲過快並始終成為社會關注的焦點等問題;認為未來一段時間內中國房價仍然會總體上漲,房價上漲壓力會向二線城市特別是中西部地區的二線城市轉移.為此,房地產調控應針對房價地區分化現象,實施差異化的住房政策;針對住房需求結構變化,優化住房供給結構;針對住房市場交易結構變化,調整房地產調控的重點領域。
本項目通過貝葉斯嶺回歸模型綜合各種因素建模房價預測模型,並通過K折交叉驗證進行房價模型的評估。
2.數據獲取
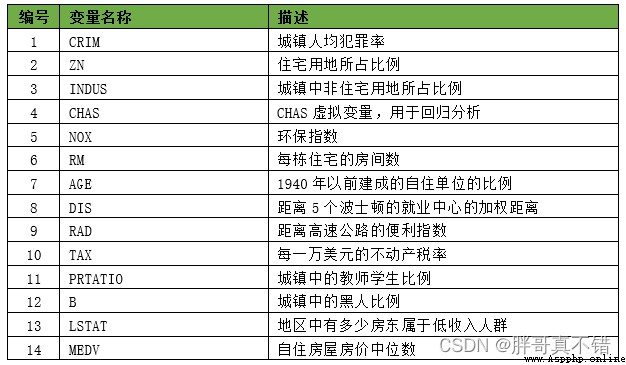
本次建模數據來源於網絡(本項目撰寫人整理而成),數據項統計如下:
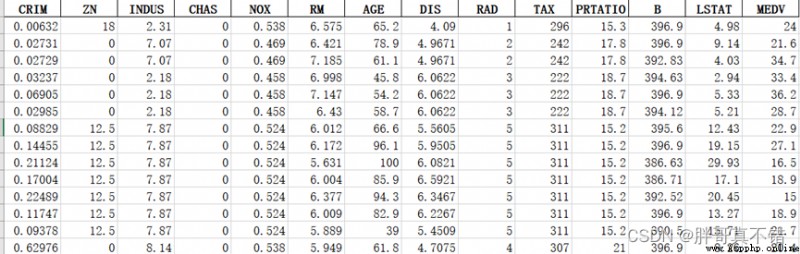
數據詳情如下(部分展示):
3.數據預處理
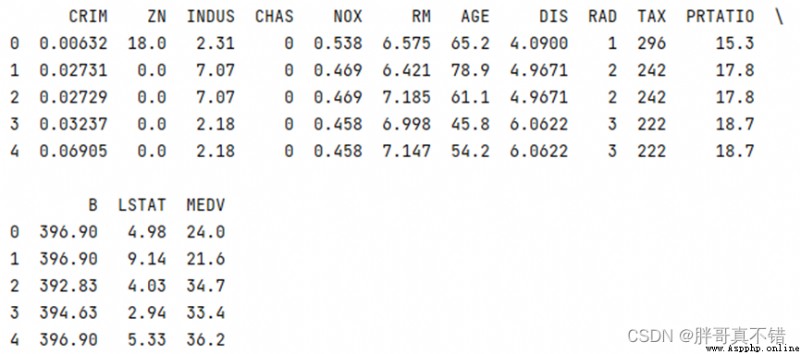
3.1 用Pandas工具查看數據
使用Pandas工具的head()方法查看前五行數據:
關鍵代碼:
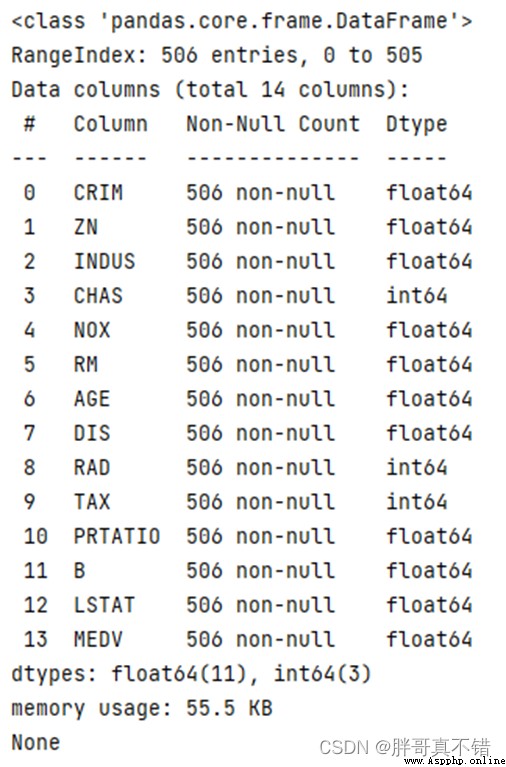
3.2數據缺失查看
使用Pandas工具的info()方法查看數據信息:
從上圖可以看到,總共有14個變量,數據中無缺失值,共506條數據。
關鍵代碼:
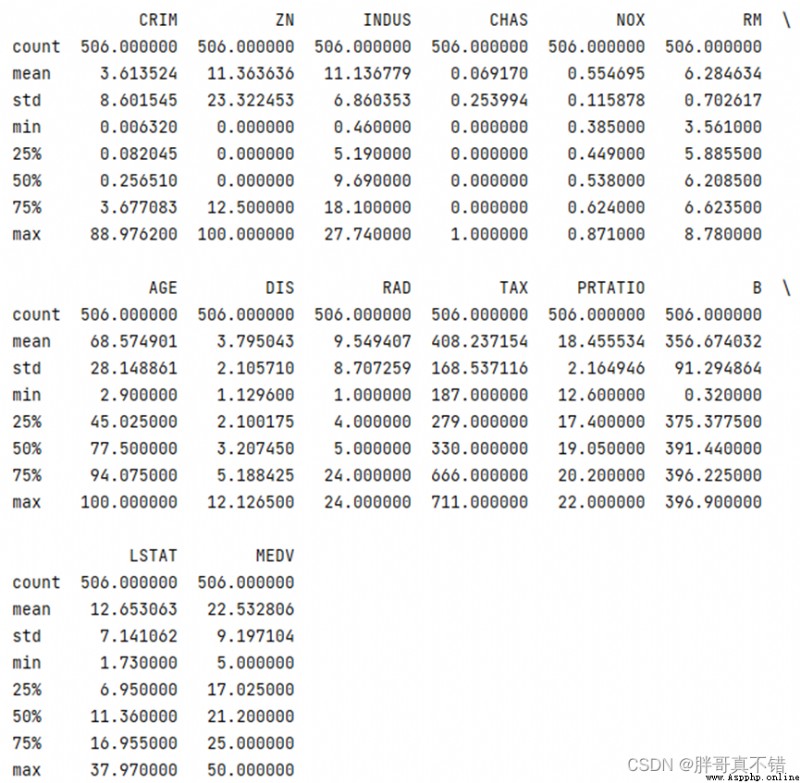
3.3數據描述性統計
通過Pandas工具的describe()方法來查看數據的平均值、標准差、最小值、分位數、最大值。
關鍵代碼如下:
4.探索性數據分析
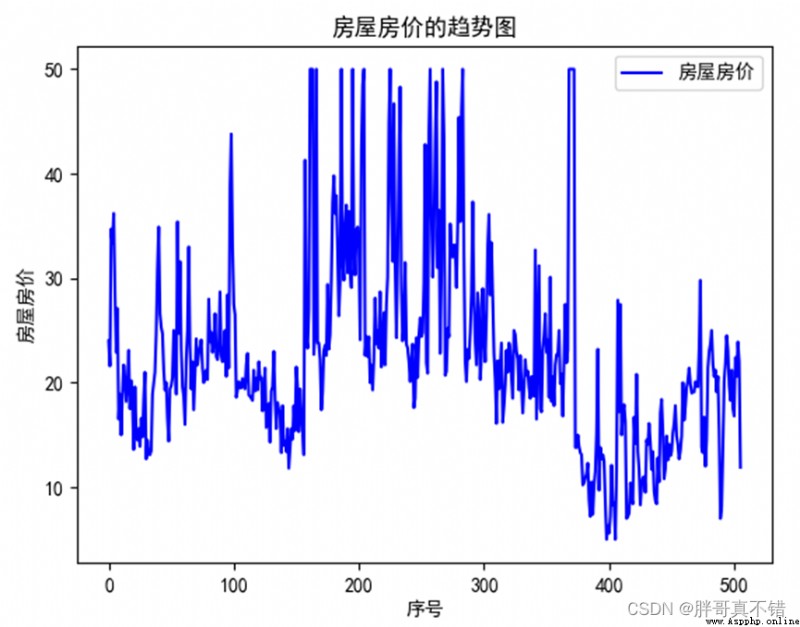
4.1 房屋房價的趨勢圖
用Matplotlib工具的plot()方法繪制折線圖:
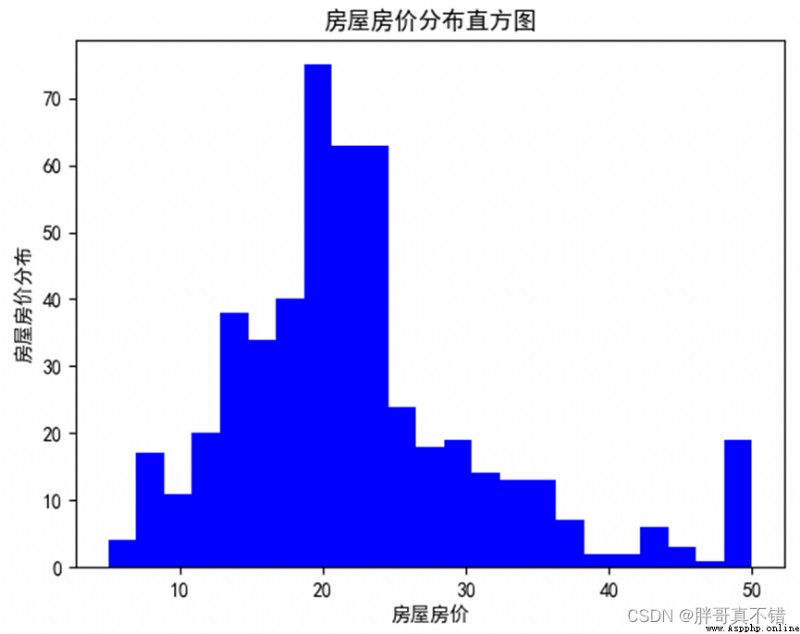
4.2 房屋房價分布直方圖
用Matplotlib工具的hist()方法繪制直方圖:
從上圖可以看出,房屋房價主要分布在115~25之間。
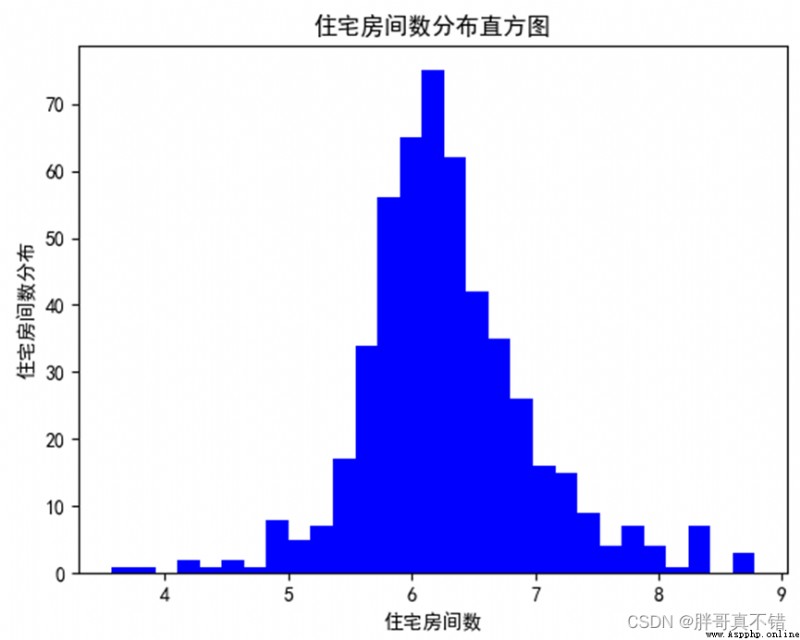
4.3 住宅房間數分布直方圖
用Matplotlib工具的hist()方法繪制直方圖:
從上圖可以看出,住宅房間數主要分布在5.5~7。
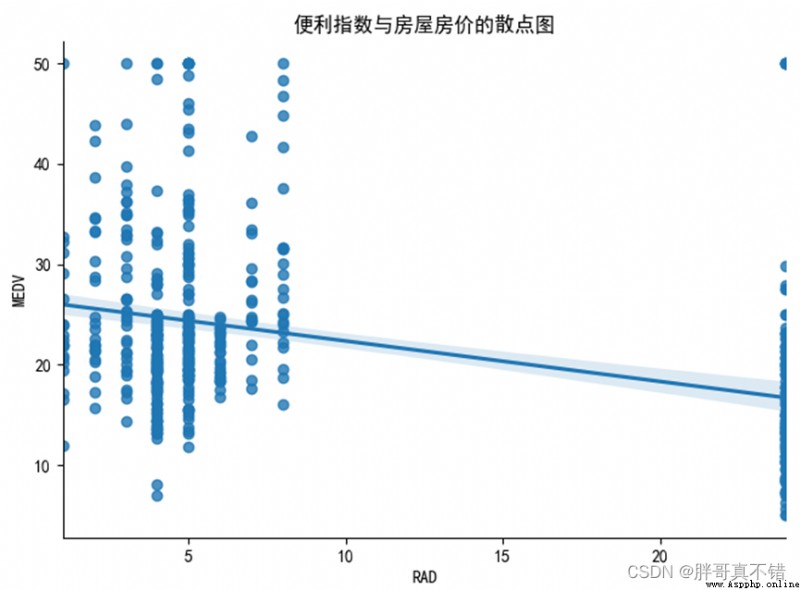
4.4 便利指數與房屋房價的散點圖與擬合線
用seaborn工具的lmplot ()方法繪制散點圖與擬合線:
從上圖可以看出,距離高速公路的便利指數和房屋房價不呈現線性關系。
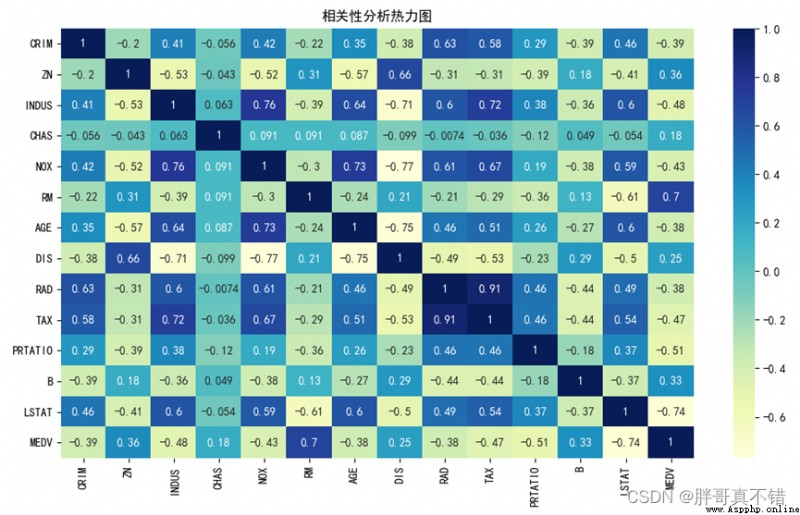
4.5 相關性分析
從上圖中可以看到,數值越大相關性越強,正值是正相關、負值是負相關。
5.特征工程
5.1 建立特征數據和標簽數據
關鍵代碼如下:
5.2 數據集拆分
通過train_test_split()方法按照80%訓練集、20%測試集進行劃分,關鍵代碼如下:
6.構建貝葉斯嶺回歸模型
主要使用BayesianRidge算法、網格搜索優化算法和K折交叉驗證,用於目標回歸。
6.1構建模型
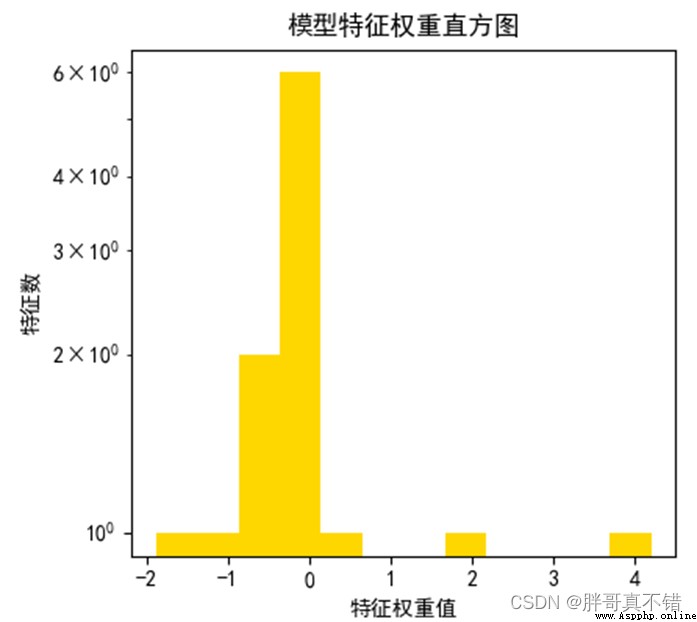
6.2模型特征權重值直方圖
從上圖可以看到,特征的權重值主要集中在-0.5~1之間。
7.模型評估
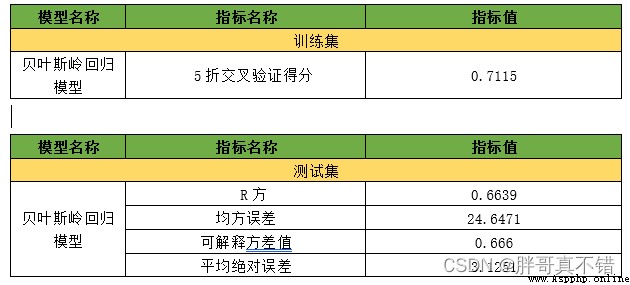
7.1評估指標及結果
評估指標主要包括可解釋方差值、平均絕對誤差、均方誤差、R方值等等。
從上表可以看出,R方為0.6639;可解釋方差值為0.666模型效果一般,可根據需要進行進一步的優化。
關鍵代碼如下:
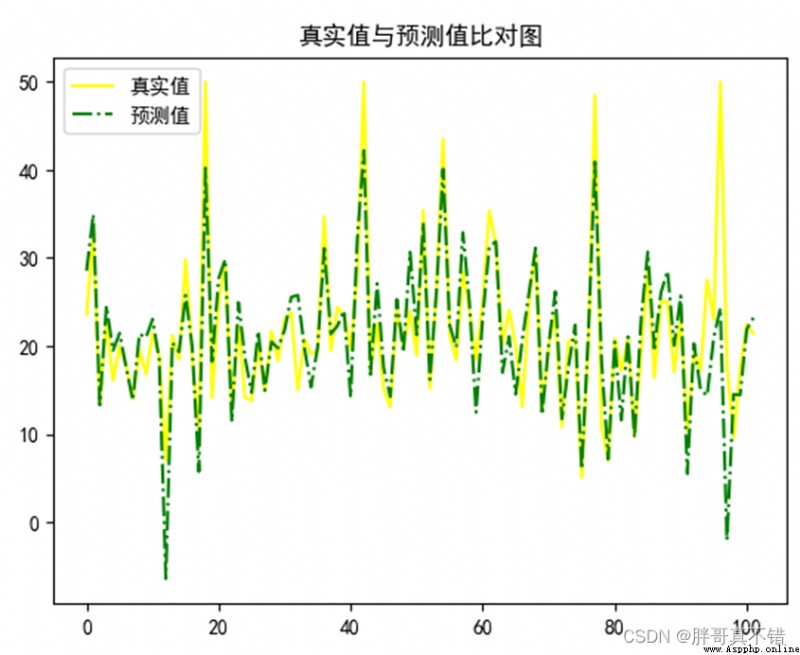
7.2 真實值與預測值對比圖
從上圖可以看出真實值和預測值波動基本一致。
8.結論與展望
綜上所述,本文采用了貝葉斯嶺回歸算法來構建回歸模型,並應用5折交叉驗證進行模型評估,房價影響因素比較多,本項目進行初步的探討、研究。
本次機器學習項目實戰所需的資料,項目資源如下:
項目說明:
鏈接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取碼:bcbp網盤如果失效,可以添加博主微信:zy10178083