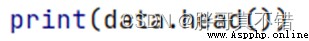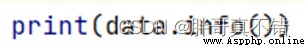explain : This is a practical project of machine learning ( Incidental data + Code + file + Video Explanation ), If you need data + Code + file + Video Explanation You can get it directly at the end of the article .
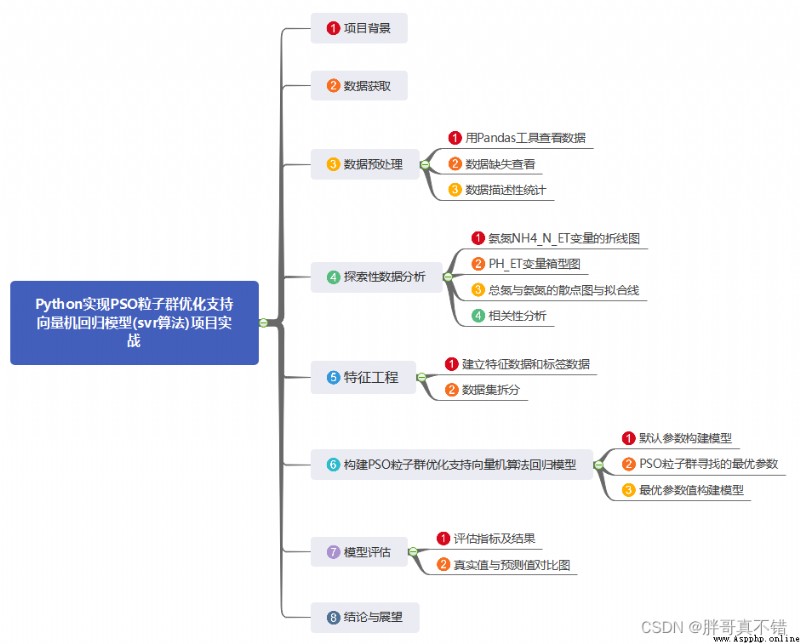
1. Project background
In the whole process of sewage treatment , In order to better make the treated water meet the environmental protection standards , In every link of sewage treatment, water quality testing machines and equipment will be used to measure the water body , According to the data and information measured by water quality testing machines and equipment , Choose the corresponding disposal method , Make the water quality index of this link meet the requirements , Move on to the next solution .
The project passed PSO Particle swarm optimization support vector machine regression model , Conduct water quality inspection .
2. Data acquisition
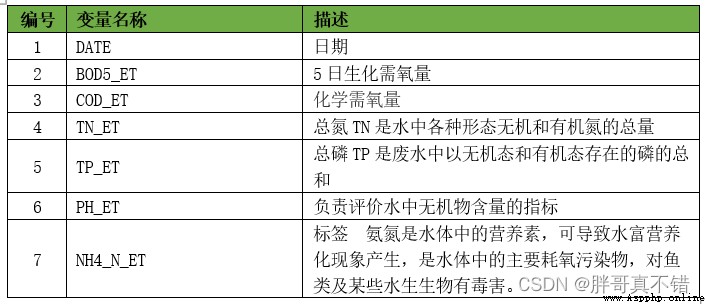
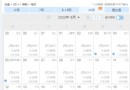
The modeling data comes from the network ( Compiled by the author of this project ), The statistics of data items are as follows :
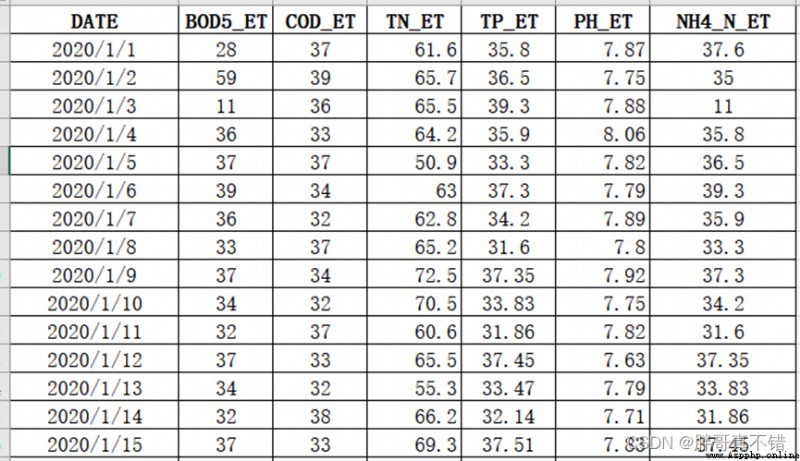
The details of the data are as follows ( Part of the show ):
3. Data preprocessing
3.1 use Pandas Tool view data
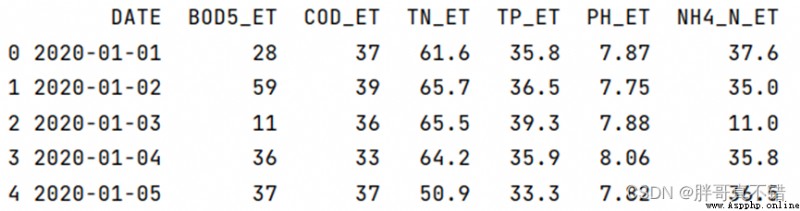
Use Pandas The tool head() Method to view the first five rows of data :
Key code :
3.2 Missing data view
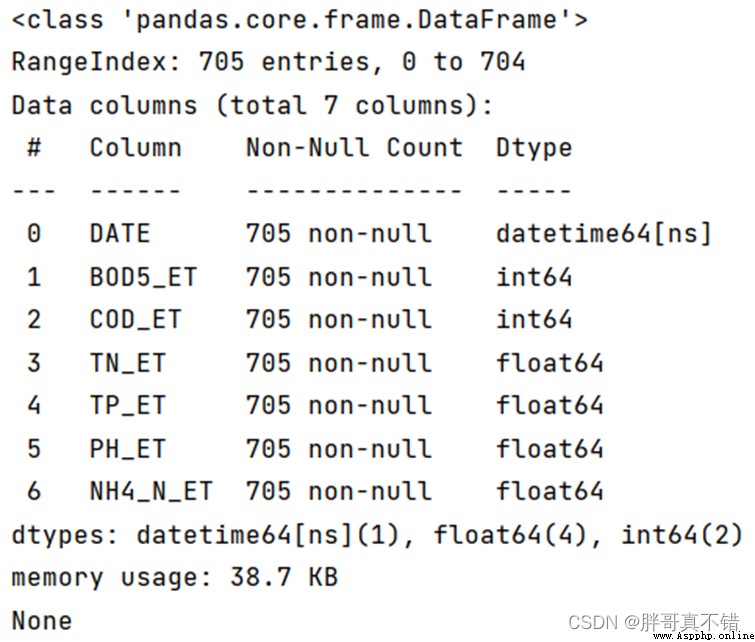
Use Pandas The tool info() Method to view data information :
You can see from the above picture that , All in all 7 A variable , There are no missing values in the data , common 705 Data .
Key code :
3.3 Descriptive statistics
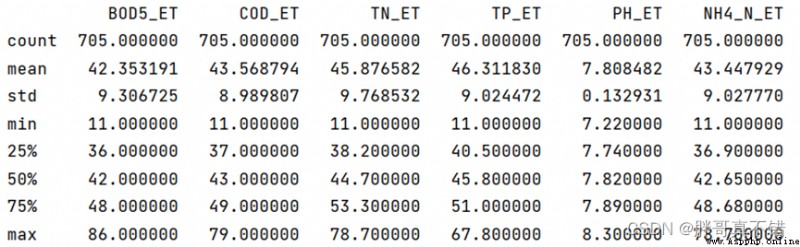
adopt Pandas The tool describe() Method to see the average of the data 、 Standard deviation 、 minimum value 、 quantile 、 Maximum .
The key codes are as follows :
4. Exploratory data analysis
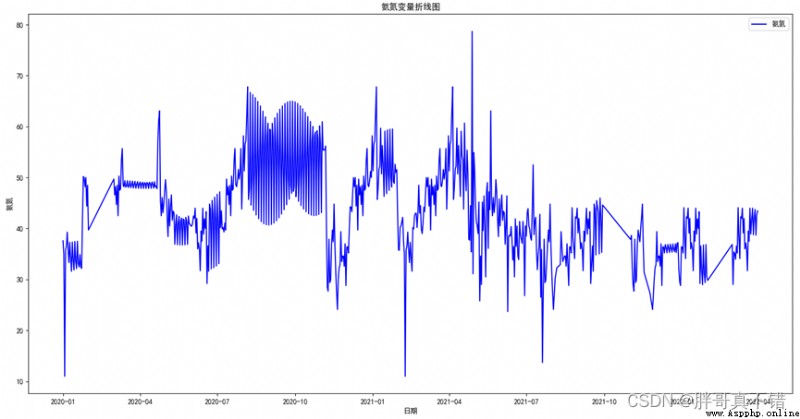
4.1 Ammonia nitrogen NH4_N_ET Line chart of variables
use Matplotlib The tool plot() Methods draw a line chart :
4.2 PH_ET Variable box diagram
use Pandas The tool plot(kind=‘box) Methods draw a histogram :
As can be seen from the above figure ,PH The mean value is 7.8 about .
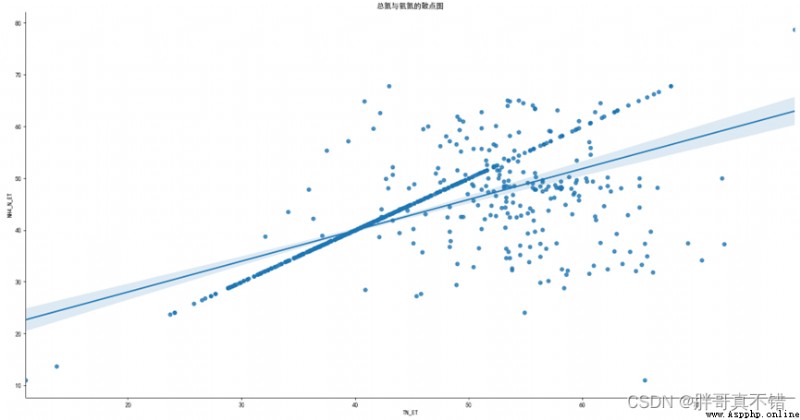
4.3 Scatter plot and fitting line of total nitrogen and ammonia nitrogen
use seaborn The tool lmplot () Methods draw the scatter diagram and fitting line :
As can be seen from the above figure , There is a certain linear relationship between total nitrogen and ammonia nitrogen .
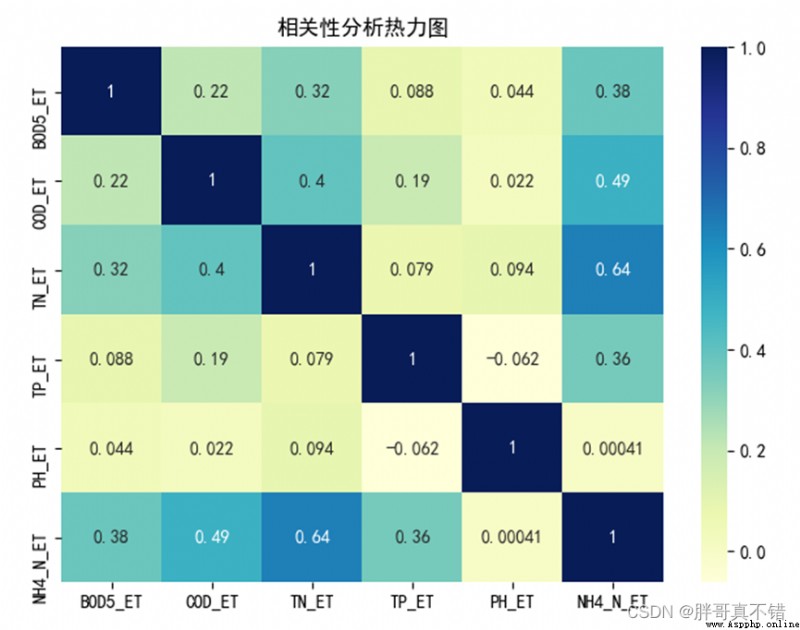
4.4 correlation analysis
As you can see from the above figure , The larger the value, the stronger the correlation , A positive value is a positive correlation 、 A negative value is a negative correlation .PH_ET And labels NH4_N_ET The correlation is very weak , In the subsequent feature engineering, we can consider removing this feature variable .
5. Feature Engineering
5.1 Establish characteristic data and label data
The key codes are as follows :
5.2 Data set splitting
adopt train_test_split() Method according to 80% Training set 、20% Divide the test set , The key codes are as follows :
6. structure PSO Particle swarm optimization support vector machine regression model
Particle swarm optimization algorithm (PSO:Particle swarm optimization) It's an evolutionary computing technology (evolutionary computation). From the study of birds' predation behavior . The basic idea of particle swarm optimization : It is to find the optimal solution through the cooperation and information sharing among individuals in the group .
The main use of PSO Particle swarm optimization SVR Algorithm , For target regression .
6.1 Build the model with default parameters
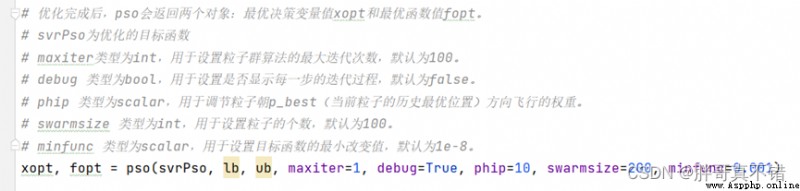
6.2 PSO The optimal parameters for particle swarm optimization
Key code :
Optimal parameters :
6.3 The optimal parameter value constructs the model
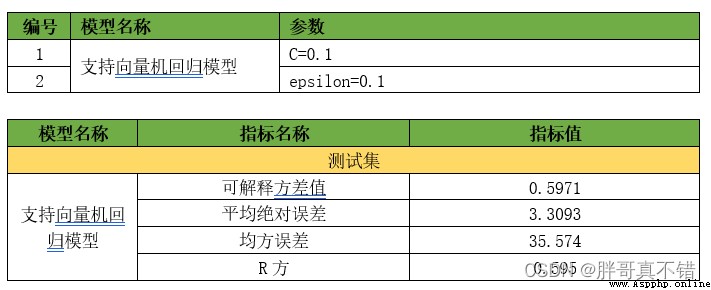
7. Model to evaluate
7.1 Evaluation indicators and results
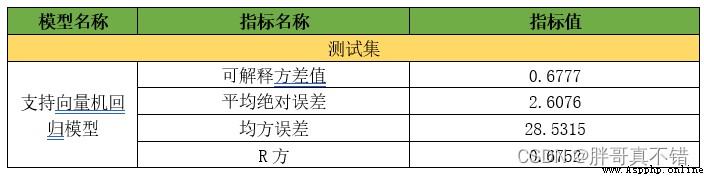
The evaluation index mainly includes the interpretable variance value 、 Mean absolute error 、 Mean square error 、R Square value, etc .
As can be seen from the table above ,R Party for 0.6752 Better than the default parameters ; The interpretable variance is 0.6777 Better than the default parameters , The optimized regression model has good effect , On this basis, you can increase the number of particle swarm iterations for tuning , The model evaluation value here is iteration 1 Evaluation value of times , Generally, we have to iterate 100 Time to 1000 Time , Therefore, you can modify the parameter value as needed in practical application .
The key codes are as follows :
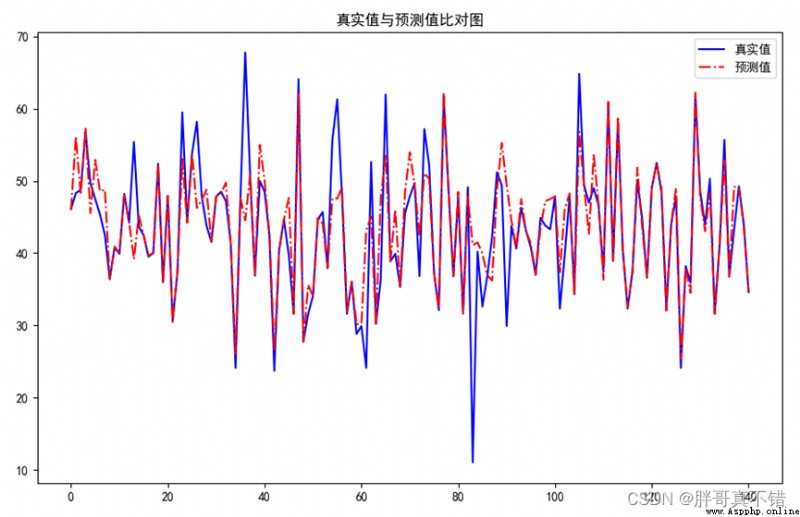
7.2 Comparison between real value and predicted value
It can be seen from the above figure that the fluctuations of the real value and the predicted value are basically the same , The fitting effect of the model is good .
8. Conclusion and Prospect
in summary , This paper adopts PSO Particle swarm optimization algorithm to find support vector machine SVR The optimal parameter value of the algorithm is used to build the regression model , Finally, it is proved that the model we proposed is effective . This model can be used to predict daily products .
The materials needed for the actual combat of this machine learning project , The project resources are as follows :
Project description :
link :https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
Extraction code :bcbpIf the network disk fails , You can add blogger wechat :zy10178083