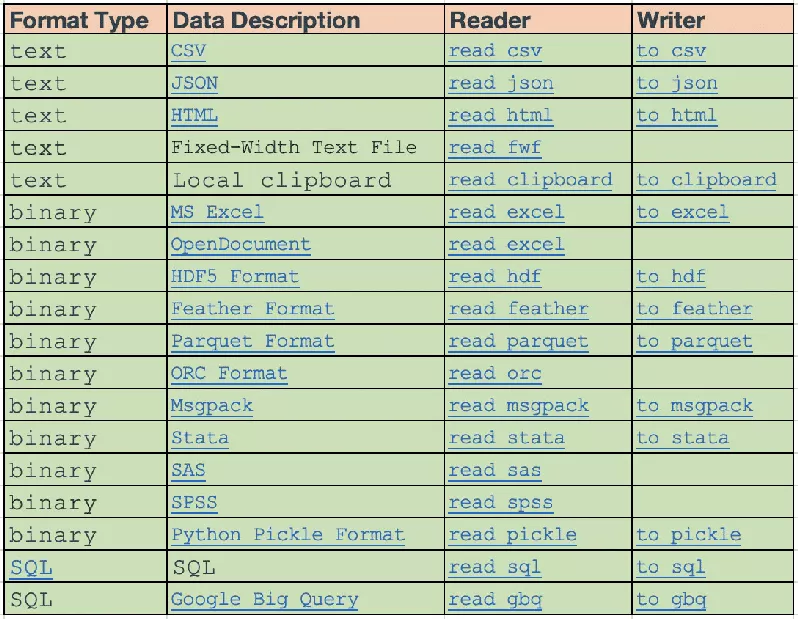
mean value if a = [5, 6, 16, 9], be np.mean(a)=9.0np.average(list_a) Calculation list list_a Of mean value if a = [5, 6, 16, 9], be np.average(a)=9.0np.average(list_a, weights = [1, 2, 1, 1]) Calculation list list_a Of Weighted average if a = [5, 6, 16, 9], be np.average(a, weights = [1, 2, 1, 1])=8.4np.var(list_a) Calculation list list_a Of Total variance if a = [5, 6, 16, 9], be np.var(a) =18.5np.var(list_a, ddof = 1) Calculation list list_a Of Sample variance if a = [5, 6, 16, 9], be np.var(a, ddof = 1) =24.67np.std(list_a) Calculation list list_a Of Overall standard deviation if a = [5, 6, 16, 9], be np.std(a) =4.3np.std(list_a, ddof = 1) Calculation list list_a Of Sample standard deviation if a = [5, 6, 16, 9], be np.std(a, ddof = 1) =4.96np.median(list_a) Calculation list list_a Of Median if a = [5, 6, 16, 9], be np.median(a)=7.5np.mode(list_a) Calculation list list_a Of The number of if a = [5, 6, 16, 9], be np.mode(a)=7.5np.percentile(list_a, (25)) Calculation list list_a Of The first 1 Four percentile if a = [1,2,3,4,5,6,7,8,9,10,11,12] , be np.mode(a)=3.75np.percentile(list_a, (50)) Calculation list list_a Of The first 2 Four percentile if a = [1,2,3,4,5,6,7,8,9,10,11,12] , be np.mode(a)=6.5np.percentile(list_a, (75)) Calculation list list_a Of The first 3 Four percentile if a = [1,2,3,4,5,6,7,8,9,10,11,12] , be np.mode(a)=9.25np.percentile(list_a, (25)) - np.percentile(list_a, (75)) Calculation list list_a Of The quartile difference np.max(list_a) - np.min(list_a)) Calculation list list_a Of range np.std(list_a)/np.mean(list_a)) Calculation list list_a Of Discrete coefficient Reference link : Measure the dispersion of data : range 、 The quartile difference 、 Average difference 、 variance 、 Standard deviation 、 The ratio of different people 、 Discrete coefficient
mean value :
mean Method Get :import numpy as np
a = [5, 6, 16, 9]
np.mean(a)
>>>
9.0
average Method You can also get a simple average . Besides , It can also find Weighted average .(average There can be one in it weights Parameters , Inside is an array of weights ) for example :import numpy as np
a = [5, 6, 16, 9]
np.average(a)
>>>
9.0
# Weighted average calculation :average There can be one in it weights Parameters , Inside is an array of weights
np.average(a, weights = [1, 2, 1, 1])
>>>
8.4
variance :
var function , Set the default parameter to null ;var function , But we need to follow Parameters ddof= 1.A typical instance :
Example 1( A one-dimensional ):
import pnumpy as np
a = [5, 6, 16, 9]
# Calculate the total variance
np.var(a)
>>>
18.5
# Calculate the sample variance
np.var(a, ddof = 1)
24.666666666666668
Example 2( Multidimensional ):
b = [[4, 5], [6, 7]]
print(b)
>>>
[[4, 5], [6, 7]]
# Calculate the variance of all elements of the matrix
np.var(b)
>>>
1.25
# Calculate the variance of each column of the matrix
np.var(b, axis = 0)
>>>
array([1., 1.])
# Calculate the variance of each row of the matrix
np.var(b, axis = 1)
>>>
array([0.25, 0.25])
Standard deviation :
std function , Set the default parameter to null ;std function , But we need to follow Parameters ddof= 1.A typical instance :
Example 1( A one-dimensional ):
import numpy as np
a = [5, 6, 16, 9]
# Calculate the overall standard deviation
np.std(a)
>>>
4.301162633521313
# Calculate the standard deviation of the sample
np.std(a, ddof = 1 )
>>>
4.96655480858378
Example 2( Multidimensional ):
b = [[4, 5], [6, 7]]
# Calculate the standard deviation of all elements of the matrix
np.std(b)
>>>
1.118033988749895
# Calculate the standard deviation of each column of the matrix
np.std(b, axis = 0)
>>>
array([1., 1.])
# Calculate the standard deviation of each column of the matrix
np.std(b, axis = 1)
>>>
array([0.5, 0.5])
about pandas , You can also use the inside mean Function can find the average of all rows or columns , for example :
import pandas as pd
df = pd.DataFrame(np.array([[85, 68, 90], [82, 63, 88], [84, 90, 78]]), columns=[' statistical ', ' Advanced Mathematics ', ' English '], index=[' Zhang San ', ' Li Si ', ' Wang Wu '])
df
>>>
statistical Advanced Mathematics English
Zhang San 85 68 90
Li Si 82 63 88
Wang Wu 84 90 78
df.mean() # Display the average of each column
>>>
statistical 83.666667
Advanced Mathematics 73.666667
English 85.333333
dtype: float64
df.mean(axis = 1) # Display the average of each line
>>>
Zhang San 81.000000
Li Si 77.666667
Wang Wu 84.000000
dtype: float64
If we calculate The average value of a row or column , You can use df.iloc Select the row or column of data , Followed by mean function You can get , for example :
df
>>>
statistical Advanced Mathematics English
Zhang San 85 68 90
Li Si 82 63 88
Wang Wu 84 90 78
df.iloc[0, :].mean() # Get the first 1 The average of rows
>>>
81.0
df.iloc[:, 2].mean() # Get the first 3 The average of the columns
>>>
85.33333333333333
pandas Medium var function You can calculate Sample variance ( Notice that it's not Total variance ),std function You can get Sample standard deviation .
To get the variance of a row or a column , Is also available df.iloc Select a row or column , Follow me var function or std function that will do , for example :
df.var() # Show the variance of each column
>>>
statistical 2.333333
Advanced Mathematics 206.333333
English 41.333333
dtype: float64
df.var(axis = 1) # Show the variance of each row
>>>
Zhang San 133.000000
Li Si 170.333333
Wang Wu 36.000000
dtype: float64
df.std() # Show the standard deviation of each column
>>>
statistical 1.527525
Advanced Mathematics 14.364308
English 6.429101
dtype: float64
df.std(axis = 1) # Show the standard deviation of each line
>>>
Zhang San 11.532563
Li Si 13.051181
Wang Wu 6.000000
dtype: float64
df.iloc[0, :].std() # According to the first 1 The standard deviation of the line
>>>
11.532562594670797
df.iloc[:, 2].std() # According to the first 3 The standard deviation of the column
>>>
6.429100507328636