It's for crawling website data , Application framework for extracting structural data , It can be applied in data mining 、 In a series of programs such as information processing or storing historical data
( One ) install
pip install scrapy -i https://pypi.douban.com/simple
Report errors :
WARNING: You are using pip version 21.3.1; however, version 22.1.2 is available.
You should consider upgrading via the 'D:\PythonCode\venv\Scripts\python.exe -m pip install --upgrade pip' command.
terms of settlement : function python -m pip install --upgrade pip
( Two ) Basic use
scrapy startproject scrapy_baidu_01D:\P ythonCode\venv\ScriptsD:\PythonCode\venv\Scripts\scrapy_baidu_01\scrapy_baidu_01\spiders>scrapy genspider Crawler file name Page to crawl scrapy crawl The name of the reptile The name is [name = ‘baidu’] import scrapy
class BaiduSpider(scrapy.Spider):
# The name of the reptile , Value used
name = 'baidu'
# Allowed access to the domain name
allowed_domains = ['www.baidu.com']
# Initial url Address The domain name visited for the first time
# start_urls really allowed_domains Add a http://, Added after /
start_urls = ['http://www.baidu.com/']
# Yes start_urls The method of execution after , Methods response Is the returned object , amount to
# response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('ssssss')
1. scrapy Project structure 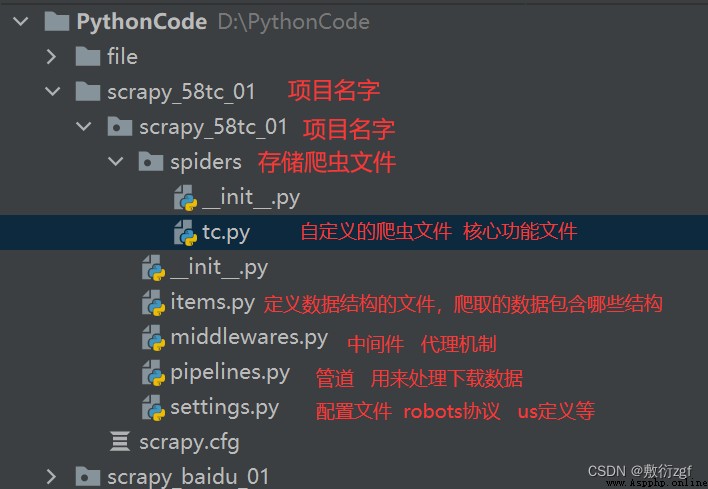
2. response Properties and methods of
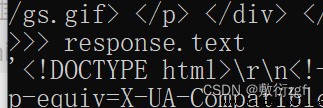
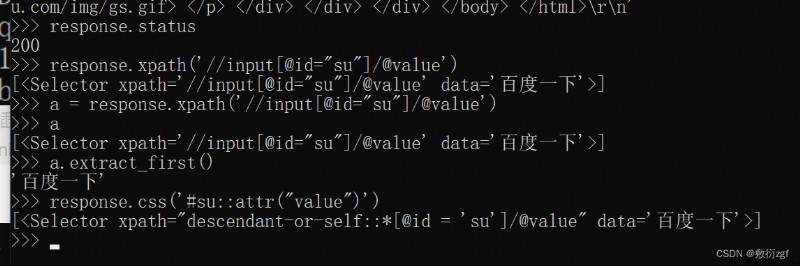
response.text Get the response string
response.body Get binary data
response.xpath You can use it directly xpath Method to parse response The content in
response.extract() For extraction seletor Object data Property value
response.extract_first() extract seletor The first data in the list
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['car.autohome.com.cn/price/brand-15.html']
start_urls = ['https://car.autohome.com.cn/price/brand-15.html']
def parse(self, response):
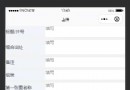
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
price(name,price)
scrapy working principle 【 Ash often matters !!】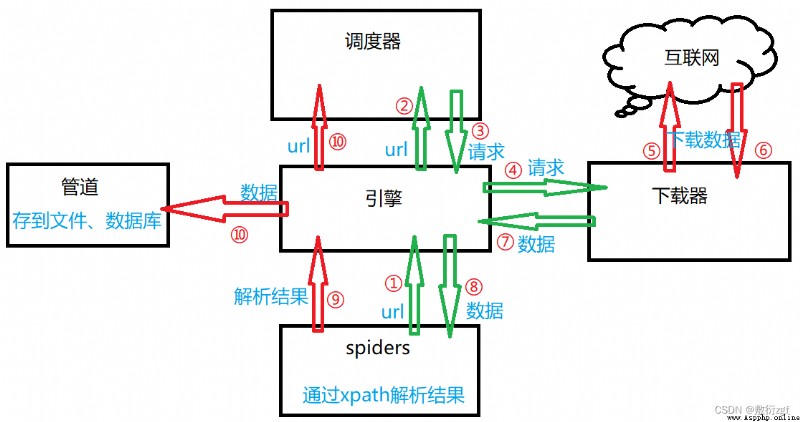
Direct input instructions :scrapy shell www.baidu.com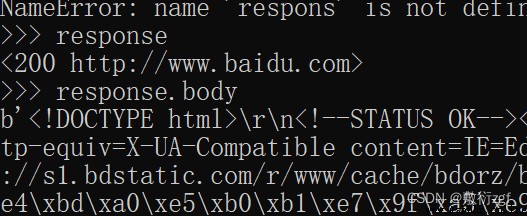
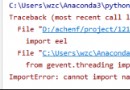
 When using pip to install modules in Python, the following message appears: fatal error in launcher solution
When using pip to install modules in Python, the following message appears: fatal error in launcher solution
python Use in pip When install