# dang.py
import scrapy
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com/cp01.01.02.00.00.00.html']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
# pipelines Download data
# items Define the data structure
# src = '//ul[@id="component_59"]/li//img/@src'
# title = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()'
# be-all seletor Objects can be called again xpath Method
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# The website has a lazy loading mechanism , So the image path is not src use data-original;
# At the same time, the first picture does not data-original, Use src
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
title = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
print(src,title,price)
# items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# picture
src = scrapy.Field()
# name
name = scrapy.Field()
# Price
price = scrapy.Fiele()

import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com/cp01.01.02.00.00.00.html']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
# pipelines Download data
# items Define the data structure
# src = '//ul[@id="component_59"]/li//img/@src'
# title = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()'
# be-all seletor Objects can be called again xpath Method
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# The website has a lazy loading mechanism , So the image path is not src use data-original;
# At the same time, the first picture does not data-original, Use src
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
title = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
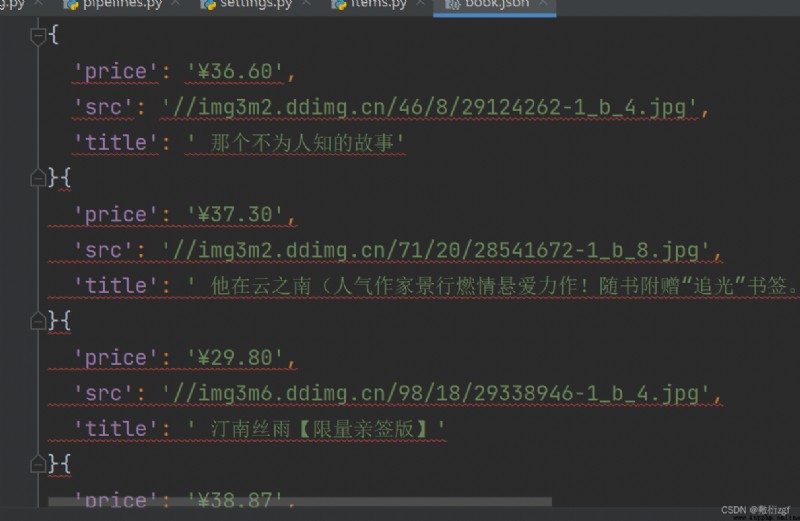
book = ScrapyDangdangItem(src=src,title=title,price=price)
# Get one book, will book hand pipelines
yield book
from itemadapter import ItemAdapter
# If you want to use pipes , Must be in settings Open the pipe in
class ScrapyDangdangPipeline:
# item yes yield hinder book object
def process_item(self, item, spider):
# Download data This mode is not recommended , Open the file every time you pass a file object , Operate on files too often
# (1)write Method must write a string , It cannot be any other object
# (2)w Pattern , The file will be opened once for each object , Overwrite the contents of the previous file
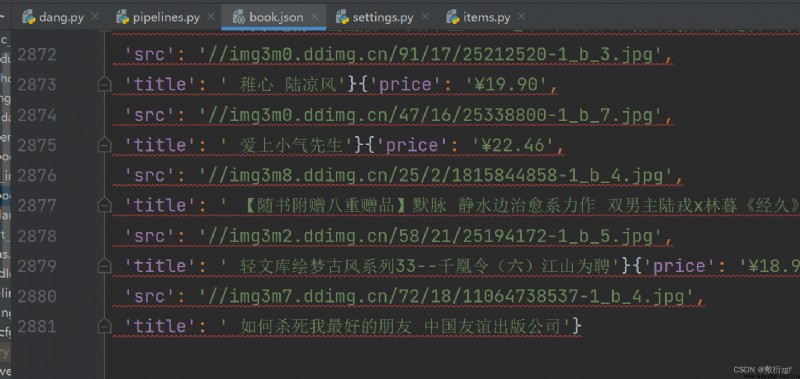
with open('book.json','a',encoding='utf-8')as fp:
fp.write(str(item))
return item
This mode is not recommended , Open the file every time you pass a file object , Operate on files too often .
Case improvement :
from itemadapter import ItemAdapter
# If you want to use pipes , Must be in settings Open the pipe in
class ScrapyDangdangPipeline:
# Execute before the crawler file is executed
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item yes yield hinder book object
def process_item(self, item, spider):
# Download data This mode is not recommended , Open the file every time you pass a file object , Operate on files too often
# (1)write Method must write a string , It cannot be any other object
# (2)w Pattern , The file will be opened once for each object , Overwrite the contents of the previous file
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# Execute after the crawler file is executed
def close_spider(self,spider):
self.fp.close()
import urllib.request
# Multiple pipes open
# (1) Define pipe class
# (2) stay settings Open multiple pipelines in : 'scrapy_dangdang.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
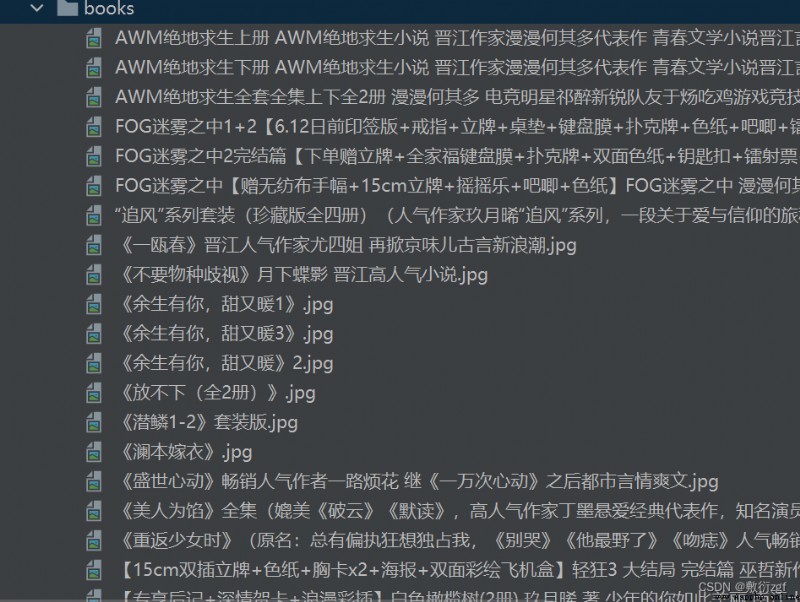
filename = './books/'+ item.get('title') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item
1.dang.py
import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
# If it is multi page download , It has to be adjusted allowed_domains The scope of the , Generally, only the domain name is written
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# pipelines Download data
# items Define the data structure
# src = '//ul[@id="component_59"]/li//img/@src'
# title = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()'
# be-all seletor Objects can be called again xpath Method
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# The website has a lazy loading mechanism , So the image path is not src use data-original;
# At the same time, the first picture does not data-original, Use src
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
title = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdangItem(src=src,title=title,price=price)
# Get one book, will book hand pipelines
yield book
# The business logic of each page is the same , Just call the executed request again parse Method
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
if self.page < 100 :
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# How to call parse Method
# scrapy.Request Namely scrapy Of get request ; url Is the request address ; callback Is the function that needs to be executed , No need to add ()
yield scrapy.Request(url=url,callback=self.parse)
2.items.py
import scrapy
class ScrapyDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# picture
src = scrapy.Field()
# name
title = scrapy.Field()
# Price
price = scrapy.Field()
3.settings.py
ITEM_PIPELINES = {
# There can be many pipes , Pipelines have priority , The priority range is 1~1000, The smaller the value. , The higher the priority
'scrapy_dangdang.pipelines.ScrapyDangdangPipeline': 300,
# DangDangDownloadPipeline
'scrapy_dangdang.pipelines.DangDangDownloadPipeline':301
}
4.Pipelines.py
from itemadapter import ItemAdapter
# If you want to use pipes , Must be in settings Open the pipe in
class ScrapyDangdangPipeline:
# Execute before the crawler file is executed
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item yes yield hinder book object
def process_item(self, item, spider):
# Download data This mode is not recommended , Open the file every time you pass a file object , Operate on files too often
# (1)write Method must write a string , It cannot be any other object
# (2)w Pattern , The file will be opened once for each object , Overwrite the contents of the previous file
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# Execute after the crawler file is executed
def close_spider(self,spider):
self.fp.close()
import urllib.request
# Multiple pipes open
# (1) Define pipe class
# (2) stay settings Open multiple pipelines in : 'scrapy_dangdang.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
filename = './books/'+ item.get('title') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item