import scrapy
from scrapy_movie.items import ScrapyMovieItem
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt8.net']
start_urls = ['https://www.dytt8.net/html/gndy/china/index.html']
def parse(self, response):
# The name of the first page and the picture of the second page
a_list= response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# Get the first page of name And the link to click
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# The address on the second page is
url = 'https://www.dytt8.net' + href
# Initiate a visit to the link on page 2
yield scrapy.Request(url=url,callback=self.parse_second,meta = {
'name':name})
def parse_second(self,response):
# If you can't get the data , Be sure to check xpath Is the path correct
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# Received the requested meta The value of the parameter
name = response.meta['name']
movie = ScrapyMovieItem(src = src,name = name)
yield movie
pipelines.py
from itemadapter import ItemAdapter
class ScrapyMoviePipeline:
def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
Case study : Shudu.com
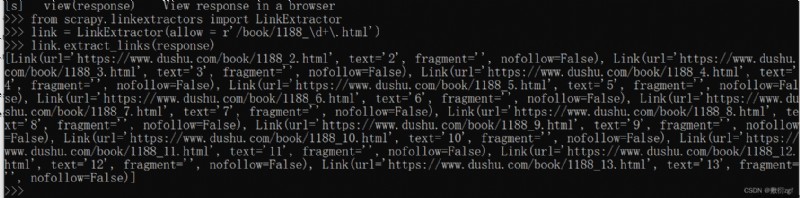
scrapy shell https://www.dushu.com/book/1188.html
from scrapy.linkextractors import LinkExtractor
# allow() # Regular expressions , Extract regular links
link = LinkExtractor(allow = r'/book/1188_\d+\.html')
link.extract_links(response)
# restrict_xpaths() # xpath Extraction coincidence xpath Links to rules
link1 = LinkExtractor(restrict_xpaths = r'//div[@class = "pages"]/a')
link1.extract_links(response)
# restrict_css() # Extract links that conform to selector rules
1. Create project scrapy startproject 【 Project name :scrapy_readbook】
2. Jump to spider Under the directory of the folder
cd D:\PythonCode\scrapy_readbook\scrapy_readbook\spiders
3. Create crawler file
scrapy genspider -t crawl read https://www.dushu.com/book/1188.html
( One ) modify read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook.items import ScrapyReadbookItem
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188_1.html']
rules = (
# Regular expressions + Represent many
Rule(LinkExtractor(allow=r'/book/1188_\d+\.html'),
callback='parse_item',
follow=False),
)
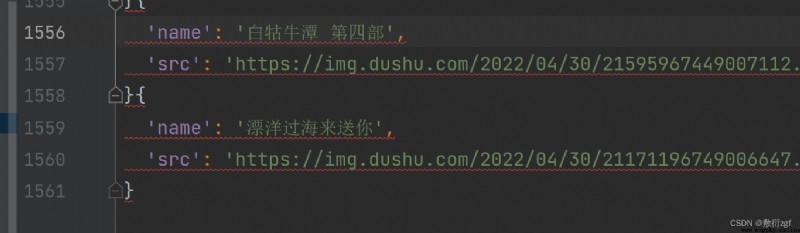
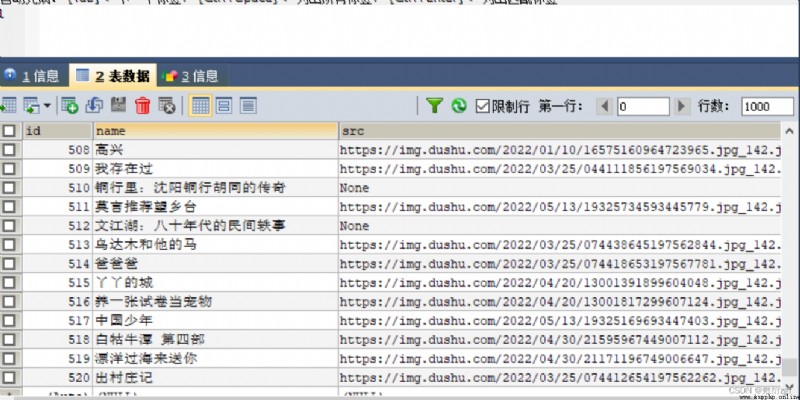
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list :
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = ScrapyReadbookItem(name=name,src=src)
yield book
( Two ) Defining variables items.py
import scrapy
class ScrapyReadbookItem(scrapy.Item):
name = scrapy.Field()
src = scrapy.Field()
( 3、 ... and ) Pipe opening settings.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_readbook.pipelines.ScrapyReadbookPipeline': 300,
}
( Four ) Custom method pipelines.py
from itemadapter import ItemAdapter
class ScrapyReadbookPipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
( One ) Configuration related information settings.py
DB_HOST = '127.0.0.1'
# Port number
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '123456'
DB_NAME = 'book'
# utf-8 No, -
DB_CHARSET = 'utf8'
( Two ) install pymysql
pip install pymysql -i https://pypi.douban.com/simple
( 3、 ... and ) Custom pipe class pipelines.py
from itemadapter import ItemAdapter
class ScrapyReadbookPipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
# load settings file
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self,spider):
settings = get_project_settings()
# DB_HOST = '192.168.97.233'
# # Port number
# DB_PORT = 3306
# DB_USER = 'root'
# DB_PASSWORD = '123456'
# DB_NAME = 'book'
# DB_CHARSET = 'utf-8'
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host = self.host,
port = self.port,
user = self.user,
password = self.password,
db = self.name,
charset = self.charset
)
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
# perform sql sentence
self.cursor.execute(sql)
# Submit
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
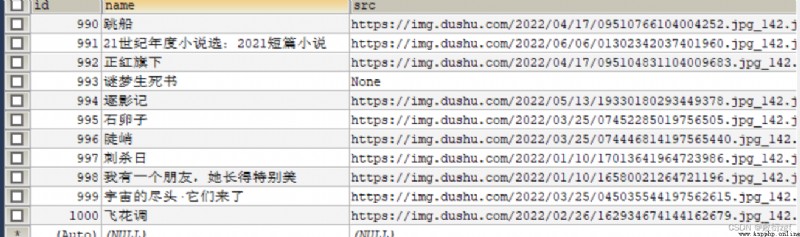
If the read.py Medium follow The property value is set to True, Then crawl all data 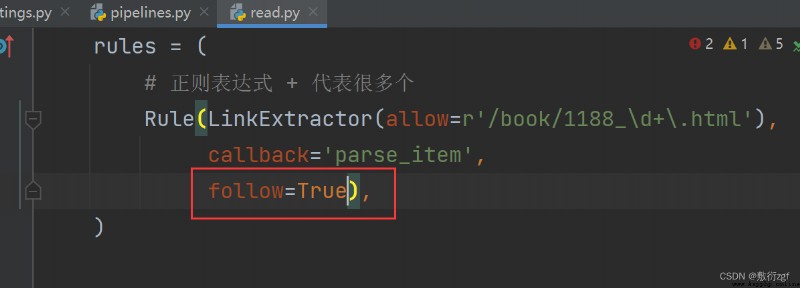
stay settings.py Specify the log level in the file 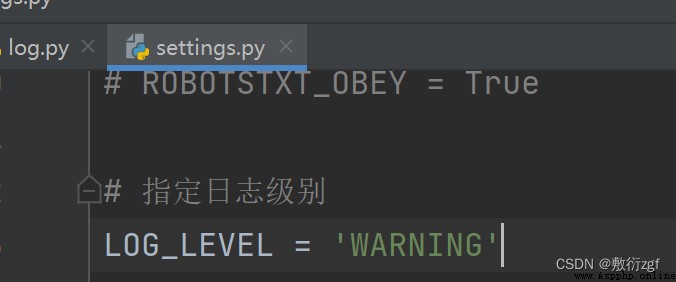

Save the log information as a file 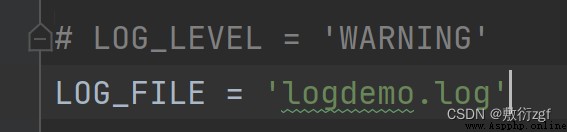
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['fanyi.baidu.com']
# post The request has no parameters , Then the request is meaningless so start_urls It's no use
# start_urls = ['https://fanyi.baidu.com/sug']
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'final'
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
def parse_second(self,response):
content = response.text
obj = json.loads(content)
print(obj)

Scrapy At the end of the series, flowers are scattered ~~