import scrapy
from scrapy_movie.items import ScrapyMovieItem
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt8.net']
start_urls = ['https://www.dytt8.net/html/gndy/china/index.html']
def parse(self, response):
# 第一頁的名字和第二頁的圖片
a_list= response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# 獲取第一頁的name和要點擊的鏈接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二頁的地址是
url = 'https://www.dytt8.net' + href
# 對第二頁的鏈接發起訪問
yield scrapy.Request(url=url,callback=self.parse_second,meta = {
'name':name})
def parse_second(self,response):
# 如果拿不到數據,務必檢查xpath的路徑是否正確
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接收到請求的meta參數的值
name = response.meta['name']
movie = ScrapyMovieItem(src = src,name = name)
yield movie
pipelines.py
from itemadapter import ItemAdapter
class ScrapyMoviePipeline:
def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
案例:讀書網
scrapy shell https://www.dushu.com/book/1188.html
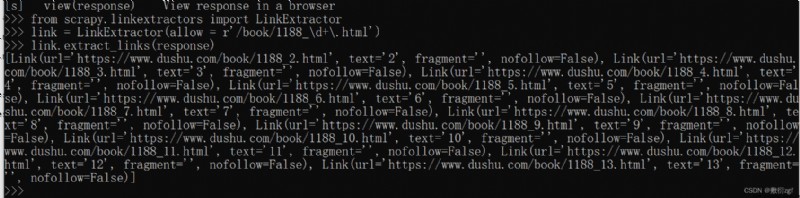
from scrapy.linkextractors import LinkExtractor
# allow() # 正則表達式,提取符合正則的鏈接
link = LinkExtractor(allow = r'/book/1188_\d+\.html')
link.extract_links(response)
# restrict_xpaths() # xpath提取符合xpath規則的鏈接
link1 = LinkExtractor(restrict_xpaths = r'//div[@class = "pages"]/a')
link1.extract_links(response)
# restrict_css() # 提取符合選擇器規則的鏈接
1.創建項目 scrapy startproject 【項目名字:scrapy_readbook】
2.跳轉到spider文件夾的目錄下
cd D:\PythonCode\scrapy_readbook\scrapy_readbook\spiders
3.創建爬蟲文件
scrapy genspider -t crawl read https://www.dushu.com/book/1188.html
(一)修改read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook.items import ScrapyReadbookItem
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188_1.html']
rules = (
# 正則表達式 + 代表很多個
Rule(LinkExtractor(allow=r'/book/1188_\d+\.html'),
callback='parse_item',
follow=False),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list :
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = ScrapyReadbookItem(name=name,src=src)
yield book
(二)定義變量items.py
import scrapy
class ScrapyReadbookItem(scrapy.Item):
name = scrapy.Field()
src = scrapy.Field()
(三)開啟管道settings.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_readbook.pipelines.ScrapyReadbookPipeline': 300,
}
(四)自定義方法pipelines.py
from itemadapter import ItemAdapter
class ScrapyReadbookPipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
(一)配置相關信息settings.py
DB_HOST = '127.0.0.1'
# 端口號
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '123456'
DB_NAME = 'book'
# utf-8沒有-
DB_CHARSET = 'utf8'
(二)安裝pymysql
pip install pymysql -i https://pypi.douban.com/simple
(三)自定義管道類pipelines.py
from itemadapter import ItemAdapter
class ScrapyReadbookPipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
# 加載settings文件
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self,spider):
settings = get_project_settings()
# DB_HOST = '192.168.97.233'
# # 端口號
# DB_PORT = 3306
# DB_USER = 'root'
# DB_PASSWORD = '123456'
# DB_NAME = 'book'
# DB_CHARSET = 'utf-8'
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host = self.host,
port = self.port,
user = self.user,
password = self.password,
db = self.name,
charset = self.charset
)
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
# 執行sql語句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
若把read.py中的follow屬性值設為True,則爬取所有數據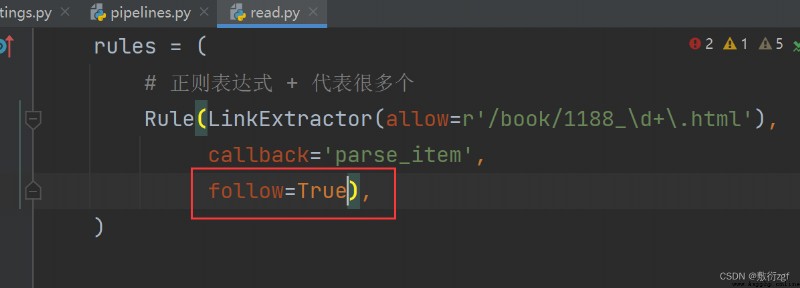
在settings.py文件中指定日志級別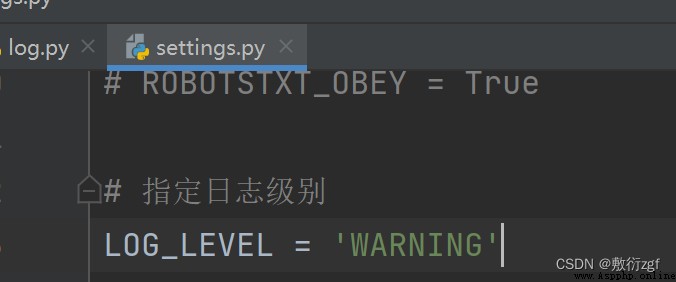

將日志信息保存成文件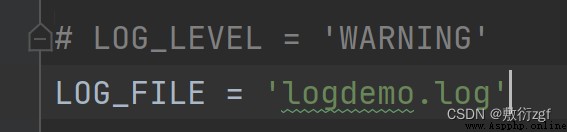
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['fanyi.baidu.com']
# post請求沒有參數,則該請求沒有意義 故start_urls也沒用
# start_urls = ['https://fanyi.baidu.com/sug']
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'final'
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
def parse_second(self,response):
content = response.text
obj = json.loads(content)
print(obj)

Scrapy系列完結撒花啦啦~~