# dang.py
import scrapy
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com/cp01.01.02.00.00.00.html']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
# pipelines 下載數據
# items 定義數據結構
# src = '//ul[@id="component_59"]/li//img/@src'
# title = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()'
# 所有的seletor對象都可以再次調用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 網站有懶加載機制,故圖片路徑不是src采用data-original;
# 同時第一張圖片沒有data-original,要用src
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
title = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
print(src,title,price)
# items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 圖片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 價格
price = scrapy.Fiele()

import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['category.dangdang.com/cp01.01.02.00.00.00.html']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
# pipelines 下載數據
# items 定義數據結構
# src = '//ul[@id="component_59"]/li//img/@src'
# title = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()'
# 所有的seletor對象都可以再次調用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 網站有懶加載機制,故圖片路徑不是src采用data-original;
# 同時第一張圖片沒有data-original,要用src
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
title = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdangItem(src=src,title=title,price=price)
# 獲取一個book,就將book交給pipelines
yield book
from itemadapter import ItemAdapter
# 如果想要使用管道,則必須在settings中開啟管道
class ScrapyDangdangPipeline:
# item是yield後面的book對象
def process_item(self, item, spider):
# 下載數據 這種模式不推薦,每傳遞一個文件對象就打開一次文件,對文件操作過於頻繁
# (1)write方法必須要寫一個字符串,而不能是其他對象
# (2)w模式,會每一次對象都打開一次文件,覆蓋掉之前的文件內容
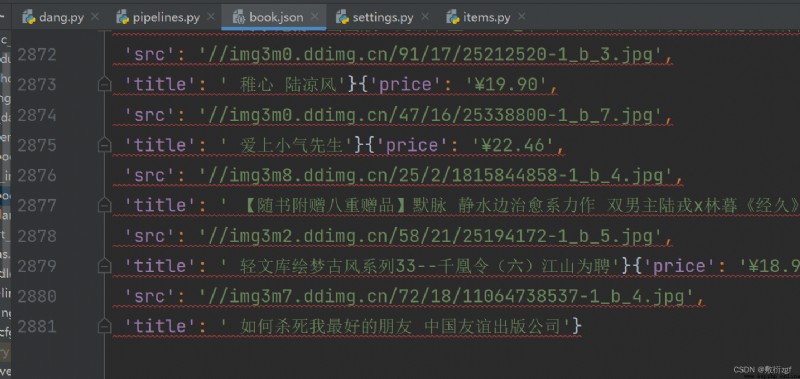
with open('book.json','a',encoding='utf-8')as fp:
fp.write(str(item))
return item
上述這種模式不推薦,每傳遞一個文件對象就打開一次文件,對文件操作過於頻繁。
案例改進:
from itemadapter import ItemAdapter
# 如果想要使用管道,則必須在settings中開啟管道
class ScrapyDangdangPipeline:
# 在爬蟲文件執行前執行
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item是yield後面的book對象
def process_item(self, item, spider):
# 下載數據 這種模式不推薦,每傳遞一個文件對象就打開一次文件,對文件操作過於頻繁
# (1)write方法必須要寫一個字符串,而不能是其他對象
# (2)w模式,會每一次對象都打開一次文件,覆蓋掉之前的文件內容
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# 在爬蟲文件執行完之後執行
def close_spider(self,spider):
self.fp.close()
import urllib.request
# 多條管道開啟
# (1) 定義管道類
# (2) 在settings中開啟多條管道 : 'scrapy_dangdang.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
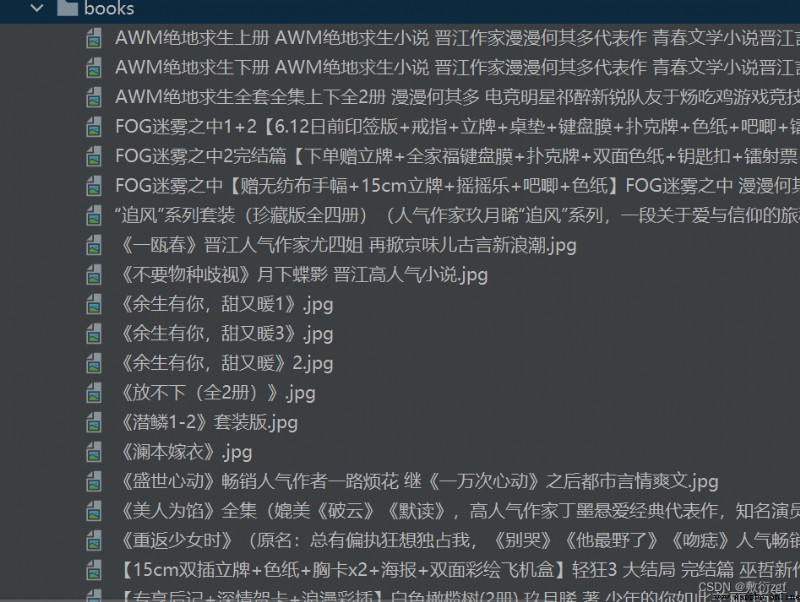
url = 'http:' + item.get('src')
filename = './books/'+ item.get('title') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item
1.dang.py
import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
#如果是多頁下載,必須要調整allowed_domains的范圍,一般情況下只寫域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# pipelines 下載數據
# items 定義數據結構
# src = '//ul[@id="component_59"]/li//img/@src'
# title = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()'
# 所有的seletor對象都可以再次調用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 網站有懶加載機制,故圖片路徑不是src采用data-original;
# 同時第一張圖片沒有data-original,要用src
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
title = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdangItem(src=src,title=title,price=price)
# 獲取一個book,就將book交給pipelines
yield book
# 每一頁爬取的業務邏輯全都是一樣的,只需要將執行的請求再次調用parse方法
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
if self.page < 100 :
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# 如何調用parse方法
# scrapy.Request就是scrapy的get請求; url就是請求地址; callback是需要執行的函數,不需要加()
yield scrapy.Request(url=url,callback=self.parse)
2.items.py
import scrapy
class ScrapyDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 圖片
src = scrapy.Field()
# 名字
title = scrapy.Field()
# 價格
price = scrapy.Field()
3.settings.py
ITEM_PIPELINES = {
# 管道可以有很多,而管道具有優先級,優先級的范圍是1~1000,值越小,優先級越高
'scrapy_dangdang.pipelines.ScrapyDangdangPipeline': 300,
# DangDangDownloadPipeline
'scrapy_dangdang.pipelines.DangDangDownloadPipeline':301
}
4.Pipelines.py
from itemadapter import ItemAdapter
# 如果想要使用管道,則必須在settings中開啟管道
class ScrapyDangdangPipeline:
# 在爬蟲文件執行前執行
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item是yield後面的book對象
def process_item(self, item, spider):
# 下載數據 這種模式不推薦,每傳遞一個文件對象就打開一次文件,對文件操作過於頻繁
# (1)write方法必須要寫一個字符串,而不能是其他對象
# (2)w模式,會每一次對象都打開一次文件,覆蓋掉之前的文件內容
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# 在爬蟲文件執行完之後執行
def close_spider(self,spider):
self.fp.close()
import urllib.request
# 多條管道開啟
# (1) 定義管道類
# (2) 在settings中開啟多條管道 : 'scrapy_dangdang.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
filename = './books/'+ item.get('title') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item