該方法是一個比較麻煩的方法,但是它不需要浏覽器的配合,適合爬蟲之類。
而另一種,使用webdriver的,使用比這個簡單,可以用來做每日簽到、打卡之類,使用python + 相關浏覽器的webdriver驅動浏覽器進行操作。
本次開發在Windos和Linux上均成功,運行環境為:
Linux:python 3.7.2
Windows:python 3.7.1
注意,在Linux下make install時候,一定要提前安裝好ssl、zlib等,前者使得python支持https,後者保證能順利安裝。別忘了gcc也要提前安裝。
以上兩個問題可能的解決方案:
yum install openssl-devel
yum install zlib*
本次模擬網站:https://www.bbaaz.com
其登錄界面網址為:https://www.bbaaz.com/member.php?mod=logging&action=login
先使用浏覽器打開,輸入用戶名、密碼,然後F12打開Dev Tools,選擇Network選項卡,注意勾選Preserve log,不然可能的情況是,你點了登錄,由於package太多的原因,或者跳轉新頁面,關鍵的包已經捨棄掉了。
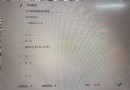
找到關鍵包,如下圖,可以看到很多信息。
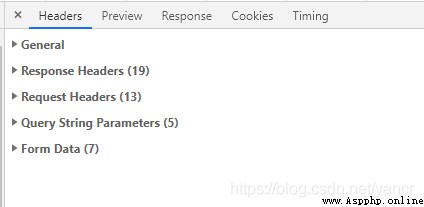
從package中可以獲取到:
Request URL: https://www.bbaaz.com/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=Lm0Hi&inajax=1
Set-Cookie:xxxxx
Form Data
formhash: xxxxx
referer: https://www.bbaaz.com/
loginfield: username
username: xxxxx
password: xxxxx
questionid: 0
answer:
仔細觀察,發現了什麼,首先,Request URL帶有了一個loginhash,再Form Data中帶有了formhash,這些應該是防止非法登錄的,那麼這些數據哪裡來的呢?經過注銷,重新打開登陸界面,分析登錄界面,可以得知這些信息,都是原登錄界面的隱藏信息。
那麼我們的思路就是,首先,打開登錄界面,從登錄界面獲取兩個Hash值,再打開一個能存放Cookie的Request,給登錄URL發送表單,記錄返回的Cookie,再打開別的頁面的時候,就可以通過Cookie進行訪問。
import urllib.request
import http.cookiejar
form = {'formhash': '',
'referer': 'https://www.bbaaz.com/',
'loginfield': 'username',
'username': 'xxxxx',
'password': 'xxxxx',
'questionid': '0',
'answer': ''}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3562.0 Safari/537.36'}
loginURL = "https://www.bbaaz.com/member.php?mod=logging&action=login"
query = "&loginsubmit=yes&frommessage&loginhash=xxx&inajax=1"
"""為什麼剛開始就直接使用帶Cookie的opener呢,經過測試,在打開登錄界面的時候,服務器就會向客戶端發送3個Cookie,這些Cookie同樣有驗證作用,如果不帶上,那麼登錄的時候,服務器會返回,含有非法字符,無法登錄"""
cookie = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
req = urllib.request.Request(loginURL, headers = headers)
resp = opener.open(req)
s = resp.read().decode('utf-8')
#獲取登錄界面的Hash值
s = s.split('<form method=\"post\"', 1)[1].split('name=\"formhash\" value=\"', 1)
suffix = s[0].split("loginform_", 1)[1].split("\"", 1)[0]
formhash = s[1].split("\" />", 1)[0]
query = query.replace('xxx', suffix)
form['formhash'] = formhash
post_form = urllib.parse.urlencode(form).encode('UTF-8')
req = urllib.request.Request(loginURL + query, headers = headers, data = post_form)
opener.open(req)
#你要訪問的網頁
req = urllib.request.Request(form['referer'], headers = headers)
resp = opener.open(req)
s = resp.read().decode('UTF-8')
經測試,使用該方法,成功模擬登錄。
https://blog.csdn.net/yancr/article/details/88762380