import gurobipy
import pandas as pd
# Display data in pages , Set to False Paging is not allowed
pd.set_option('display.expand_frame_repr', False)
# Maximum number of columns to display , Set to None Show all columns
pd.set_option('display.max_columns', None)
# Maximum number of rows to display , Set to None Show all rows
pd.set_option('display.max_rows', None)
class DEA(object):
def __init__(self, DMUs_Name, X, Y, AP=False):
self.m1, self.m1_name, self.m2, self.m2_name, self.AP = X.shape[1], X.columns.tolist(), Y.shape[
1], Y.columns.tolist(), AP # shape Row number columns.tolist Name
self.DMUs, self.X, self.Y = gurobipy.multidict(
{DMU: [X.loc[DMU].tolist(), Y.loc[DMU].tolist()] for DMU in DMUs_Name})
print(f'DEA(AP={AP}) MODEL RUNING...')
def __CCR(self):
for k in self.DMUs:
MODEL = gurobipy.Model()
OE, lambdas, s_negitive, s_positive = MODEL.addVar(), MODEL.addVars(self.DMUs), MODEL.addVars(
self.m1), MODEL.addVars(self.m2)
MODEL.update()
MODEL.setObjectiveN(OE, index=0, priority=1)
MODEL.setObjectiveN(-(sum(s_negitive) + sum(s_positive)), index=1, priority=0)
MODEL.addConstrs(
gurobipy.quicksum(lambdas[i] * self.X[i][j] for i in self.DMUs if i != k or not self.AP) + s_negitive[
j] == OE * self.X[k][j] for j in range(self.m1))
MODEL.addConstrs(
gurobipy.quicksum(lambdas[i] * self.Y[i][j] for i in self.DMUs if i != k or not self.AP) - s_positive[
j] == self.Y[k][j] for j in range(self.m2))
MODEL.setParam('OutputFlag', 0)
MODEL.optimize()
self.Result.at[k, (' Benefit analysis ', ' Comprehensive technical benefits (CCR)')] = MODEL.objVal
self.Result.at[k, (' Return to scale analysis ',
' effectiveness ')] = ' Not DEA It works ' if MODEL.objVal < 1 else 'DEA Weak effective ' if s_negitive.sum().getValue() + s_positive.sum().getValue() else 'DEA Strongly effective '
self.Result.at[k, (' Return to scale analysis ',
' type ')] = ' The return to scale is fixed ' if lambdas.sum().getValue() == 1 else ' Increasing returns to scale ' if lambdas.sum().getValue() < 1 else ' Diminishing returns to scale '
for m in range(self.m1):
self.Result.at[k, (' Variance analysis ', f'{self.m1_name[m]}')] = s_negitive[m].X
self.Result.at[k, (' Input redundancy rate ', f'{self.m1_name[m]}')] = 'N/A' if self.X[k][m] == 0 else s_negitive[m].X / \
self.X[k][m]
for m in range(self.m2):
self.Result.at[k, (' Variance analysis ', f'{self.m2_name[m]}')] = s_positive[m].X
self.Result.at[k, (' Under output rate ', f'{self.m2_name[m]}')] = 'N/A' if self.Y[k][m] == 0 else s_positive[m].X / \
self.Y[k][m]
return self.Result
def __BCC(self):
for k in self.DMUs:
MODEL = gurobipy.Model()
TE, lambdas = MODEL.addVar(), MODEL.addVars(self.DMUs)
MODEL.update()
MODEL.setObjective(TE, sense=gurobipy.GRB.MINIMIZE)
MODEL.addConstrs(
gurobipy.quicksum(lambdas[i] * self.X[i][j] for i in self.DMUs if i != k or not self.AP) <= TE *
self.X[k][j] for j in range(self.m1))
MODEL.addConstrs(
gurobipy.quicksum(lambdas[i] * self.Y[i][j] for i in self.DMUs if i != k or not self.AP) >= self.Y[k][j]
for j in range(self.m2))
MODEL.addConstr(gurobipy.quicksum(lambdas[i] for i in self.DMUs if i != k or not self.AP) == 1)
MODEL.setParam('OutputFlag', 0)
MODEL.optimize()
self.Result.at[
k, (' Benefit analysis ', ' Technical benefits (BCC)')] = MODEL.objVal if MODEL.status == gurobipy.GRB.Status.OPTIMAL else 'N/A'
return self.Result
def dea(self):
columns_Page = [' Benefit analysis '] * 3 + [' Return to scale analysis '] * 2 + [' Variance analysis '] * (self.m1 + self.m2) + [' Input redundancy rate '] * self.m1 + [
' Under output rate '] * self.m2
columns_Group = [' Technical benefits (BCC)', ' Scale benefits (CCR/BCC)', ' Comprehensive technical benefits (CCR)', ' effectiveness ', ' type '] + (self.m1_name + self.m2_name) * 2
self.Result = pd.DataFrame(index=self.DMUs, columns=[columns_Page, columns_Group])
self.__CCR()
self.__BCC()
self.Result.loc[:, (' Benefit analysis ', ' Scale benefits (CCR/BCC)')] = self.Result.loc[:, (' Benefit analysis ', ' Comprehensive technical benefits (CCR)')] / self.Result.loc[:,
(' Benefit analysis ',
' Technical benefits (BCC)')]
return self.Result
def analysis(self, file_name=None):
Result = self.dea()
file_name = r'C:\Users\ Misty rain \Desktop\ mathematical modeling \2021_MCM-ICM_Problems\F topic \ Indicator data \DEA Data envelopment analysis report .xlsx'
Result.to_excel(file_name, 'DEA Data envelopment analysis report ')
if __name__ == '__main__':
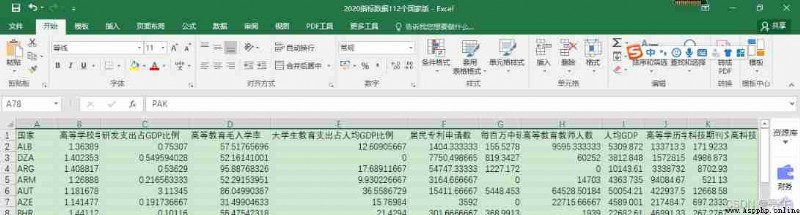
io = r"C:\Users\ Misty rain \Desktop\ mathematical modeling \2021_MCM-ICM_Problems\F topic \ Indicator data \2020 Indicator data 112 National edition .xlsx"
x = pd.read_excel(io, sheet_name = 0, usecols = [2, 4, 7]) # Import input data
y = pd.read_excel(io, sheet_name = 0, usecols = [5, 6, 9, 10, 11]) # Import output data
country = pd.read_excel(io, sheet_name = 0, usecols = [0])
data = DEA(DMUs_Name= range(0,112), X=x, Y=y)
# data.analysis()
print(data.dea())Result display :
 evaluation :
evaluation :
To use !
Source code : Data envelopment analysis (DEA) Detailed explanation ( Take the eighth Ningxia provincial competition as an example )_ A blog about raising apes -CSDN Blog _dea Data analysis