Alden law ring is about to go on sale !!!
steam, Most friends who play games will know ,Steam The platform is one of the largest comprehensive digital distribution platforms in the world , However, most users only use this platform because they buy Games .
Yes, just used steam Users of , I don't know what game to play ? Often popular goods will make them the most suitable choice .
Of course ,steamdb The above data will be more detailed , What game users are highly active , Whichever regional service game is cheaper, there will be . however steamdb Add a layer Cloudflare Browser authentication :
Some people say to use cloudscraper, however cloudscraper For the commercial version Cloudflare It doesn't seem to work ( probably , If there is a big man who has a better way, please point out in time , thank you ), I will try other methods later steamdb. So this steamdb First press no table , Start getting steam Hot selling information .
Click to enter the popular products page :
https://store.steampowered.com/search/?sort_by=_ASC&force_infinite=1&snr=1_7_7_globaltopsellers_7&filter=globaltopsellers&page=2&os=win
If your hand is fast enough , You'll see

This explains the above link , Only the data on the first page can be obtained , To find the real content and get the link through the developer mode is :
https://store.steampowered.com/search/results/?query&start=0&count=50&sort_by=_ASC&os=win&snr=1_7_7_globaltopsellers_7&filter=globaltopsellers&infinite=1
among start Corresponding to the starting position , Corresponding to page turning .count It corresponds to how much data is obtained at a time .
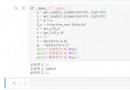
get The request can be , Code up :
def getInfo(self):
url = 'https://store.steampowered.com/search/results/?query&start=0&count=50&sort_by=_ASC&os=win&snr=1_7_7_globaltopsellers_7&filter=globaltopsellers&infinite=1'
res = self.getRes(url,self.headers,'','','GET')# Self encapsulated request method
res = res.json()['results_html']
sel = Selector(text=res)
nodes = sel.css('.search_result_row')
for node in nodes:
gamedata = {}
gamedata['url'] = node.css('a::attr(href)').extract_first()# link
gamedata['name'] = node.css('a .search_name .title::text').extract_first()# Game name
gamedata['sales_date'] = node.css('a .search_released::text').extract_first()# Sale date
discount = node.css('.search_discount span::text').extract_first()# Is there a discount
gamedata['discount'] = discount if discount else 'no discount'
price = node.css('a .search_price::text').extract_first().strip()# Price
discountPrice = node.css('.discounted::text').extract()# The discounted price
discountPrice = discountPrice[-1] if discountPrice else ''
gamedata['price'] = discountPrice if discountPrice else price# The final price
print(gamedata)
pandas Storage Excel Data utilization is pandas Object's to_excel Method , take pandas Of Dataframe Object is inserted directly Excel In the table .
and DataFrame Represents the data table of the matrix , Contains the sorted column set .
First , First, the obtained data , To build a Dataframe object , First, save the data we obtained into the corresponding list in , Acquired url Deposit in url Of list, Save the game name to name Of list:
url = []
name = []
sales_date = []
discount = []
price = []
url = node.css('a::attr(href)').extract_first()
if url not in self.url:
self.url.append(url)
name = node.css('a .search_name .title::text').extract_first()
sales_date = node.css('a .search_released::text').extract_first()
discount = node.css('.search_discount span::text').extract_first()
discount = discount if discount else 'no discount'
price = node.css('a .search_price::text').extract_first().strip()
discountPrice = node.css('.discounted::text').extract()
discountPrice = discountPrice[-1] if discountPrice else ''
price = discountPrice if discountPrice else price
self.name.append(name)
self.sales_date.append(sales_date)
self.discount.append(discount)
self.price.append(price)
else:
print(' Already exists ')take list Form the corresponding dictionary
data = {
'URL':self.url,' Game name ':self.name,' Sale date ':self.sales_date,' Is there a discount ':self.discount,' Price ':self.price
}among dict Medium key The value corresponds to Excel Column name of . After use pandas Of DataFrame() Method to build an object , Then insert Excel file .
data = {
'URL':self.url,' Game name ':self.name,' Sale date ':self.sales_date,' Is there a discount ':self.discount,' Price ':self.price
}
frame = pd.DataFrame(data)
xlsxFrame = pd.read_excel('./steam.xlsx')among pd It's the introduction pandas The object of the package , It's customary to see pd That is to introduce pandas.
import pandas as pdIf you turn the page , Repeat the call to insert Excel Method, you will find Excel The data in the table will not increase , Because every time to_excel() Methods will overwrite the data you wrote last time .
So if you want to keep the data written before , Then read out the data written before , Then compare with the newly generated data DaraFrame Merge of objects , Write the total data again Excel
frame = frame.append(xlsxFrame)The writing method is as follows :
def insert_info(self):
data = {
'URL':self.url,' Game name ':self.name,' Sale date ':self.sales_date,' Is there a discount ':self.discount,' Price ':self.price
}
frame = pd.DataFrame(data)
xlsxFrame = pd.read_excel('./steam.xlsx')
print(xlsxFrame)
if xlsxFrame is not None:
print(' Additional ')
frame = frame.append(xlsxFrame)
frame.to_excel('./steam.xlsx', index=False)
else:
frame.to_excel('./steam.xlsx', index=False)
Logic :
import requests
from scrapy import Selector
import pandas as pd
class getSteamInfo():
headers = {
"Host": "store.steampowered.com",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36",
}
url = []
name = []
sales_date = []
discount = []
price = []
# api obtain ip
def getApiIp(self):
# Get and only get one ip
api_url = 'api Address '
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print(' Acquisition failure ')
except:
print(' Acquisition failure ')
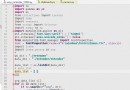
def getInfo(self):
url = 'https://store.steampowered.com/search/results/?query&start=0&count=50&sort_by=_ASC&os=win&snr=1_7_7_globaltopsellers_7&filter=globaltopsellers&infinite=1'
res = self.getRes(url,self.headers,'','','GET')# Self encapsulated request method
res = res.json()['results_html']
sel = Selector(text=res)
nodes = sel.css('.search_result_row')
for node in nodes:
url = node.css('a::attr(href)').extract_first()
if url not in self.url:
self.url.append(url)
name = node.css('a .search_name .title::text').extract_first()
sales_date = node.css('a .search_released::text').extract_first()
discount = node.css('.search_discount span::text').extract_first()
discount = discount if discount else 'no discount'
price = node.css('a .search_price::text').extract_first().strip()
discountPrice = node.css('.discounted::text').extract()
discountPrice = discountPrice[-1] if discountPrice else ''
price = discountPrice if discountPrice else price
self.name.append(name)
self.sales_date.append(sales_date)
self.discount.append(discount)
self.price.append(price)
else:
print(' Already exists ')
# self.insert_info()
def insert_info(self):
data = {
'URL':self.url,' Game name ':self.name,' Sale date ':self.sales_date,' Is there a discount ':self.discount,' Price ':self.price
}
frame = pd.DataFrame(data)
xlsxFrame = pd.read_excel('./steam.xlsx')
print(xlsxFrame)
if xlsxFrame is not None:
print(' Additional ')
frame = frame.append(xlsxFrame)
frame.to_excel('./steam.xlsx', index=False)
else:
frame.to_excel('./steam.xlsx', index=False)
# The method of sending requests specifically , Agent requests three times , Three failures return an error
def getRes(self,url, headers, proxies, post_data, method):
if proxies:
for i in range(3):
try:
# Transmitted to agent post request
if method == 'POST':
res = requests.post(url, headers=headers, data=post_data, proxies=proxies)
# Transmitted to agent get request
else:
res = requests.get(url, headers=headers, proxies=proxies)
if res:
return res
except:
print(f' The first {i+1} Error in request ')
else:
return None
else:
for i in range(3):
proxies = self.getApiIp()
try:
# Requesting proxy post request
if method == 'POST':
res = requests.post(url, headers=headers, data=post_data, proxies=proxies)
# Requesting proxy get request
else:
res = requests.get(url, headers=headers, proxies=proxies)
if res:
return res
except:
print(f" The first {i+1} Error in request ")
else:
return None
if __name__ == '__main__':
getSteamInfo().getInfo()by the way , This data is obtained steam Meifu data . lately steam Domestic visits are unstable , If you want to get data without buying games, it is recommended to use an agent to access . When I use it here ipidea Agent for , New users can whore for nothing .
Address :http://www.ipidea.net/?utm-source=csdn&utm-keyword=?wb
Finally, I would like to advise you : Appropriate games , Rational consumption , Serious life , Support genuine . That's right steam Data crawling and data saving .( Large quantities of data should be stored in the database , Others also support exporting Excel)