Source code address
import torch
from d2l import torch as d2l
from torch import nn
from torch.utils import data
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
def load_array(data_arrays, batch_size, is_train=True): # @save
""" Construct a PyTorch Data iterators """
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# Use the predefined layers of the framework
net = nn.Sequential(nn.Linear(2, 1)) # The input is 2D , The output is one-dimensional
# Initialize model parameters
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
# The mean square error is calculated using MELoss class , Also known as L_2 norm
loss = nn.MSELoss()
# Instantiation SGD( Stochastic gradient descent ) example
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
# Training
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {
epoch + 1},loss {
l:f}')
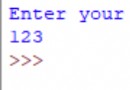
Output :
epoch 1,loss 0.000229
epoch 2,loss 0.000091
epoch 3,loss 0.000091
Because our weight parameters are initialized randomly , So each run will be different loss.