該模塊作用是完成Python數值和C語言結構體的Python字符串形式間的轉換。這可以用於處理存儲在文件中或從網絡連接中存儲的二進制數據,以及其他數據源。
用途: 在Python基本數據類型和二進制數據之間進行轉換
struct模塊提供了用於在字節字符串和Python原生數據類型之間轉換函數,比如數字和字符串。
它除了提供一個Struct類之外,還有許多模塊級的函數用於處理結構化的值。這裡有個格式符(Format specifiers)的概念,是指從字符串格式轉換為已編譯的表示形式,類似於正則表達式的處理方式。通常實例化Struct類,調用類方法來完成轉換,比直接調用模塊函數有效的多。下面的例子都是使用Struct類。
Struct支持將數據packing(打包)成字符串,並能從字符串中逆向unpacking(解壓)出數據。
在本例中,格式指定器(specifier)需要一個整型或長整型,一個兩個字節的string,和一個浮點數。格式符中的空格用於分隔各個指示器(indicators),在編譯格式時會被忽略。
import struct
import binascii
values = (1, 'ab'.encode('utf-8'), 2.7)
s = struct.Struct('I 2s f')
packed_data = s.pack(*values)
print('原始值:', values)
print('格式符:', s.format)
print('占用字節:', s.size)
print('打包結果:', binascii.hexlify(packed_data))
# output
原始值: (1, b'ab', 2.7)
格式符: b'I 2s f'
占用字節: 12
打包結果: b'0100000061620000cdcc2c40'
這個示例將打包的值轉換為十六進制字節序列,用binascii.hexlify()方法打印出來。
使用unpack()方法解包。
import struct
import binascii
packed_data = binascii.unhexlify(b'0100000061620000cdcc2c40')
s = struct.Struct('I 2s f')
unpacked_data = s.unpack(packed_data)
print('解包結果:', unpacked_data)
# output
解包結果: (1, b'ab', 2.700000047683716)
將打包的值傳給unpack(),基本上返回相同的值(浮點數會有差異)。
默認情況下,pack是使用本地C庫的字節順序來編碼的。格式化字符串的第一個字符可以用來表示填充數據的字節順序、大小和對齊方式,如下表所描述的: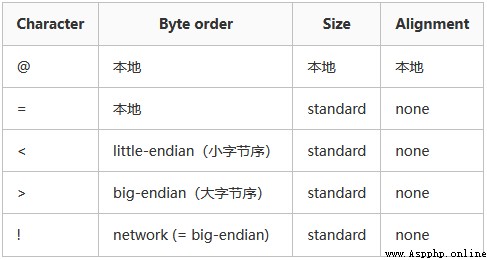
如果格式符中沒有設置這些,那麼默認將使用 @。
本地字節順序是指字節順序是由當前主機系統決定。比如:Intel x86和AMD64(x86-64)使用小字節序; Motorola 68000和 PowerPC G5使用大字節序。ARM和Intel安騰支持切換字節序。可以使用sys.byteorder查看當前系統的字節順序。
本地大小(Size)和對齊(Alignment)是由c編譯器的sizeof表達式確定的。它與本地字節順序對應。
標准大小由格式符確定,下面會講各個格式的標准大小。
示例:
''' 學習中遇到問題沒人解答?小編創建了一個Python學習交流QQ群:711312441 尋找有志同道合的小伙伴,互幫互助,群裡還有不錯的視頻學習教程和PDF電子書! '''
import struct
import binascii
values = (1, 'ab'.encode('utf-8'), 2.7)
print('原始值 : ', values)
endianness = [
('@', 'native, native'),
('=', 'native, standard'),
('<', 'little-endian'),
('>', 'big-endian'),
('!', 'network'),
]
for code, name in endianness:
s = struct.Struct(code + ' I 2s f')
packed_data = s.pack(*values)
print()
print('格式符 : ', s.format, 'for', name)
print('占用字節: ', s.size)
print('打包結果: ', binascii.hexlify(packed_data))
print('解包結果: ', s.unpack(packed_data))
# output
原始值 : (1, b'ab', 2.7)
格式符 : b'@ I 2s f' for native, native
占用字節: 12
打包結果: b'0100000061620000cdcc2c40'
解包結果: (1, b'ab', 2.700000047683716)
格式符 : b'= I 2s f' for native, standard
占用字節: 10
打包結果: b'010000006162cdcc2c40'
解包結果: (1, b'ab', 2.700000047683716)
格式符 : b'< I 2s f' for little-endian
占用字節: 10
打包結果: b'010000006162cdcc2c40'
解包結果: (1, b'ab', 2.700000047683716)
格式符 : b'> I 2s f' for big-endian
占用字節: 10
打包結果: b'000000016162402ccccd'
解包結果: (1, b'ab', 2.700000047683716)
格式符 : b'! I 2s f' for network
占用字節: 10
打包結果: b'000000016162402ccccd'
解包結果: (1, b'ab', 2.700000047683716)
格式符對照表如下: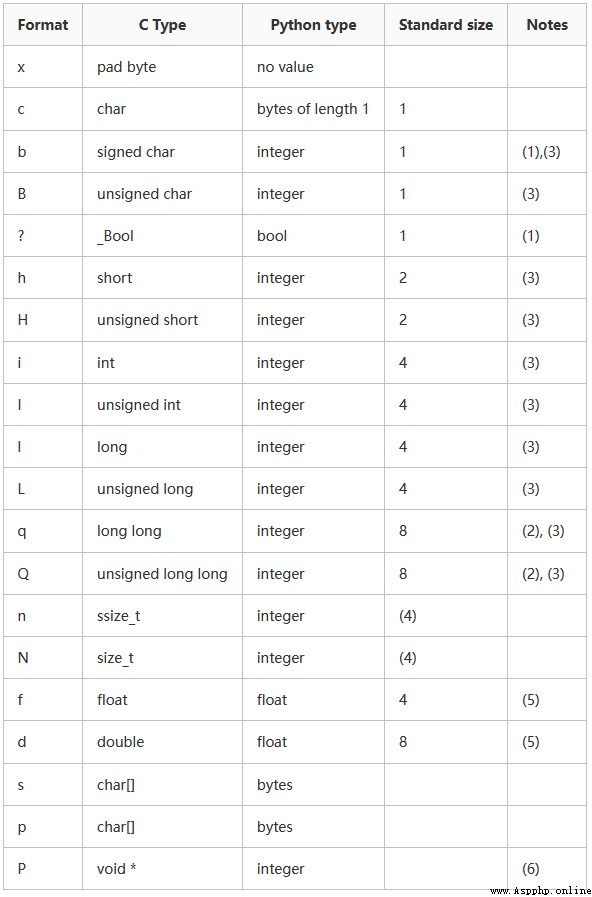
將數據打包成二進制通常是用在對性能要求很高的場景。
在這類場景中可以通過避免為每個打包結構分配新緩沖區的開銷來優化。
pack_into()和unpack_from()方法支持直接寫入預先分配的緩沖區。
import array
import binascii
import ctypes
import struct
s = struct.Struct('I 2s f')
values = (1, 'ab'.encode('utf-8'), 2.7)
print('原始值:', values)
print()
print('使用ctypes模塊string buffer')
b = ctypes.create_string_buffer(s.size)
print('原始buffer :', binascii.hexlify(b.raw))
s.pack_into(b, 0, *values)
print('打包結果寫入 :', binascii.hexlify(b.raw))
print('解包 :', s.unpack_from(b, 0))
print()
print('使用array模塊')
a = array.array('b', b'\0' * s.size)
print('原始值 :', binascii.hexlify(a))
s.pack_into(a, 0, *values)
print('打包寫入 :', binascii.hexlify(a))
print('解包 :', s.unpack_from(a, 0))
# output
原始值: (1, b'ab', 2.7)
使用ctypes模塊string buffer
原始buffer : b'000000000000000000000000'
打包結果寫入 : b'0100000061620000cdcc2c40'
解包 : (1, b'ab', 2.700000047683716)
使用array模塊
原始值 : b'000000000000000000000000'
打包寫入 : b'0100000061620000cdcc2c40'
解包 : (1, b'ab', 2.700000047683716)