@ Founded in :2022.07.01
@ Modified to :2022.07.01
import pandas as pd
import numpy as np
df = pd.DataFrame({
'books':['book_1', 'book_2', 'book_2', 'book_1', 'book_2', 'book_3'],
'price':[10, 20, 30, 30, 20, 10],
'num':[4, 6, 2, 4, 2, 8]})
df
books price num
0 book_1 10 4
1 book_2 20 6
2 book_2 30 2
3 book_1 30 4
4 book_2 20 2
5 book_3 10 8

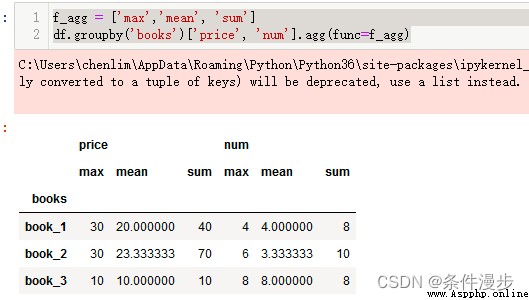
f_agg = ['max','mean', 'sum']
df.groupby('books')['price', 'num'].agg(func=f_agg)
# Anonymous aggregate functions can be used
# have access to as_index=False Yes, grouping fields are not used as row indexes
df.groupby('books', as_index=False)['price', 'num'].agg(lambda x: x.eq(10).sum())
books price num
0 book_1 1 0
1 book_2 0 0
2 book_3 1 0
# When agg There are more aggregate functions in 1 When it's time ,as_index invalid
df.groupby('books', as_index=False)['price'].agg([lambda x: x.eq(10).sum(), 'mean']).rename({
'<lambda_0>':'eq10'}, axis=1)
eq10 mean
books
book_1 1 20.000000
book_2 0 23.333333
book_3 1 10.000000
f_agg = ['max', lambda x: x.eq(10).sum(), 'mean', lambda x: x.isna().sum()]
df.groupby('books')['price'].agg(func=f_agg).rename({
'<lambda_0>':'eq10'}, axis=1)
max eq10 mean <lambda_1>
books
book_1 30 1 20.000000 0
book_2 30 0 23.333333 0
book_3 10 1 10.000000 0
# Filter according to the number of quotes
df.groupby('books').filter(lambda x: len(x)>1)
books price num
0 book_1 10 4
1 book_2 20 6
2 book_2 30 2
3 book_1 30 4
4 book_2 20 2
# Filter according to the number of quotes
df.groupby('books').filter(lambda x: x['num'].sum()>8)
books price num
1 book_2 20 6
2 book_2 30 2
4 book_2 20 2
df2.groupby(‘books’).apply(lambda x: x[‘num’]/x[‘num’].max()).reset_index()
df2n = df2.groupby(‘books’)[‘num’].apply(lambda x: x/x.max())
df2n
Pandas course | Super easy to use Groupby Usage details
DataFrame Perform data grouping operations and filter the specified conditions group