You may perform many repetitive tasks every day , For example, reading news 、 email 、 Check the weather 、 Clean up folders, etc , Using automated scripts , You don't have to do these tasks again and again manually , Very convenient . And to some extent ,Python Is synonymous with automation .
Share today 8 A very useful Python Automation script . Like to remember to collect 、 Focus on 、 give the thumbs-up .
This script can grab text from web pages , Then automatic voice reading , When you want to hear the news , It's a good choice .
The code is divided into two parts , First, grab the web text through the crawler , Second, read the text through reading tools .
Third party libraries needed :
Beautiful Soup - classical HTML/XML Text parser , Used to extract the information of the web page climbing down
requests - Good to use against the sky HTTP Tools , Used to send requests to web pages to get data
Pyttsx3 - Convert text to speech , And control the rate 、 Frequency and voice
import pyttsx3
import requests
from bs4 import BeautifulSoup
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
newVoiceRate = 130 ## Reduce The Speech Rate
engine.setProperty('rate',newVoiceRate)
engine.setProperty('voice', voices[1].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
text = str(input("Paste article\n"))
res = requests.get(text)
soup = BeautifulSoup(res.text,'html.parser')
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
text = " ".join(articles)
speak(text)
# engine.save_to_file(text, 'test.mp3') ## If you want to save the speech as a audio file
engine.runAndWait()
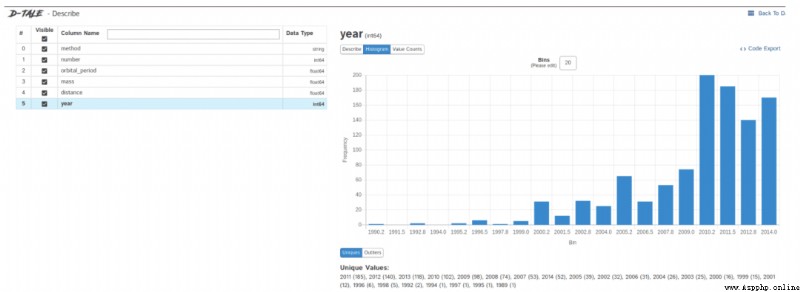
Data exploration is the first step of the data science project , You need to understand the basic information of the data to further analyze the deeper value .
We usually use pandas、matplotlib And other tools to explore data , But you need to write a lot of code yourself , If you want to be more efficient ,Dtale It's a good choice .
Dtale The feature is to generate automatic analysis report with one line of code , It is a combination of Flask Back end and React front end , It provides us with a way to view and analyze Pandas A simple method of data structure .
We can do it in Jupyter Practical Dtale.
Third party libraries needed :
Dtale - Automatically generate analysis report
### Importing Seaborn Library For Some Datasets
import seaborn as sns
### Printing Inbuilt Datasets of Seaborn Library
print(sns.get_dataset_names())
### Loading Titanic Dataset
df=sns.load_dataset('titanic')
### Importing The Library
import dtale
#### Generating Quick Summary
dtale.show(df)
This script can help us send emails in batches and on a regular basis , Email content 、 Attachments can also be customized , Very practical .
Compared with the mail client ,Python The advantage of scripts is that they can intelligently 、 Batch 、 Highly customized deployment of mail services .
Third party libraries needed :
Email - Used to manage email messages
Smtlib - towards SMTP The server sends email , It defines a SMTP Client session object , This object can send mail to any on the Internet SMTP or ESMTP The computer listening to the program
Pandas - Tools for data analysis and cleaning
import smtplib
from email.message import EmailMessage
import pandas as pd
def send_email(remail, rsubject, rcontent):
email = EmailMessage() ## Creating a object for EmailMessage
email['from'] = 'The Pythoneer Here' ## Person who is sending
email['to'] = remail ## Whom we are sending
email['subject'] = rsubject ## Subject of email
email.set_content(rcontent) ## content of email
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("[email protected]","[email protected]") ## login id and password of gmail
smtp.send_message(email) ## Sending email
print("email send to ",remail) ## Printing success message
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]
send_email(email,subject,content)
Scripts can pdf Convert to audio file , The principle is also simple , First use PyPDF extract pdf The text in the , And then use Pyttsx3 Convert text to voice .
import pyttsx3,PyPDF2
pdfreader = PyPDF2.PdfFileReader(open('story.pdf','rb'))
speaker = pyttsx3.init()
for page_num in range(pdfreader.numPages):
text = pdfreader.getPage(page_num).extractText() ## extracting text from the PDF
cleaned_text = text.strip().replace('\n',' ') ## Removes unnecessary spaces and break lines
print(cleaned_text) ## Print the text from PDF
#speaker.say(cleaned_text) ## Let The Speaker Speak The Text
speaker.save_to_file(cleaned_text,'story.mp3') ## Saving Text In a audio file 'story.mp3'
speaker.runAndWait()
speaker.stop()
This script will randomly select a song from the song folder to play , It should be noted that os.startfile Support only Windows System .
import random, os
music_dir = 'G:\\new english songs'
songs = os.listdir(music_dir)
song = random.randint(0,len(songs))
print(songs[song]) ## Prints The Song Name
os.startfile(os.path.join(music_dir, songs[0]))
The website of the National Meteorological Administration provides access to weather forecasts API, Go straight back to json Weather data in format . So just start with json Just take out the corresponding field from the .
Here are the designated cities ( county 、 District ) Weather website , Go straight to the website , The weather data of the corresponding city will be returned . such as :
http://www.weather.com.cn/data/cityinfo/101021200.html Corresponding weather website of Xuhui District, Shanghai .
The specific code is as follows :
mport requests
import json
import logging as log
def get_weather_wind(url):
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
info = json.loads(r.content.decode())
# get wind data
data = info['weatherinfo']
WD = data['WD']
WS = data['WS']
return "{}({})".format(WD, WS)
def get_weather_city(url):
# open url and get return data
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
# convert string to json
info = json.loads(r.content.decode())
# get useful data
data = info['weatherinfo']
city = data['city']
temp1 = data['temp1']
temp2 = data['temp2']
weather = data['weather']
return "{} {} {}~{}".format(city, weather, temp1, temp2)
if __name__ == '__main__':
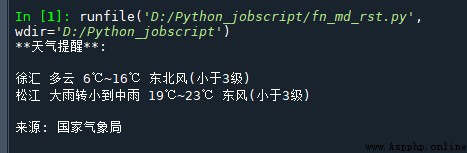
msg = """** Weather alert **:
{} {}
{} {}
source : National Meteorological Administration
""".format(
get_weather_city('http://www.weather.com.cn/data/cityinfo/101021200.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101021200.html'),
get_weather_city('http://www.weather.com.cn/data/cityinfo/101020900.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101020900.html')
)
print(msg)
The running results are as follows :
Sometimes , Those big ones URL Become very angry , It's hard to read and share , This foot can change the long URL into a short URL .
import contextlib
from urllib.parse import urlencode
from urllib.request import urlopen
import sys
def make_tiny(url):
request_url = ('http://tinyurl.com/api-create.php?' +
urlencode({'url':url}))
with contextlib.closing(urlopen(request_url)) as response:
return response.read().decode('utf-8')
def main():
for tinyurl in map(make_tiny, sys.argv[1:]):
print(tinyurl)
if __name__ == '__main__':
main()
This script is very practical , For example, some content platforms block official account articles , Then you can change the link from official account to short link. , Then insert it , You can bypass
One of the most confusing things in the world is the developer's download folder , There are a lot of disorderly documents in it , This script will clean up your download folder based on the size limit , Limited cleanup of older files :
import os
import threading
import time
def get_file_list(file_path):
# Files are sorted by last modification time
dir_list = os.listdir(file_path)
if not dir_list:
return
else:
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)))
return dir_list
def get_size(file_path):
"""[summary]
Args:
file_path ([type]): [ Catalog ]
Returns:
[type]: Return directory size ,MB
"""
totalsize=0
for filename in os.listdir(file_path):
totalsize=totalsize+os.path.getsize(os.path.join(file_path, filename))
#print(totalsize / 1024 / 1024)
return totalsize / 1024 / 1024
def detect_file_size(file_path, size_Max, size_Del):
"""[summary]
Args:
file_path ([type]): [ File directory ]
size_Max ([type]): [ Maximum folder size ]
size_Del ([type]): [ exceed size_Max Size to delete when ]
"""
print(get_size(file_path))
if get_size(file_path) > size_Max:
fileList = get_file_list(file_path)
for i in range(len(fileList)):
if get_size(file_path) > (size_Max - size_Del):
print ("del :%d %s" % (i + 1, fileList[i]))
#os.remove(file_path + fileList[i])
Finally, thank everyone who reads my article carefully , Watching the rise and attention of fans all the way , Reciprocity is always necessary , Although it's not very valuable , If you can use it, you can take it
These materials , For thinking 【 Advanced automated testing 】 For our friends, it should be the most comprehensive and complete war preparation warehouse , This warehouse also accompanied me through the most difficult journey , I hope it can help you ! Everything should be done as soon as possible , Especially in the technology industry , We must improve our technical skills . I hope that's helpful …….