Suppose the mean value of a certain data is u, Actual sampling time u The closer it is, the more reasonable the assumed mean , The farther , The more unreasonable it is .
Here's another one p-value The concept of , It represents the difference between the actual sampling results and assumptions . A larger value means that there is no difference . In practice, we will set a threshold by ourselves , Such as 0.05, When calculated p-value Greater than this 0.05 when , Just meet our needs , This 0.05 It's called significance level .
Single sample T test : Test whether the average value of a single sample is equal to the target value ;
Here's the scene , A string of data , Whether his growth rate is 0.1, The significance level is 0.5, That is to say p-value Greater than 0.5 Explain that the average value of a single sample is equal to the target value ;
The following code :
import statsmodels.api as sm
valueList = [0.169747191462884, 0.165484359308337, 0.141358295556684, 0.0631967134074211, 0.101527686160212]
if __name__ == '__main__':
d = sm.stats.DescrStatsW(valueList)
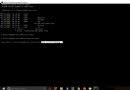
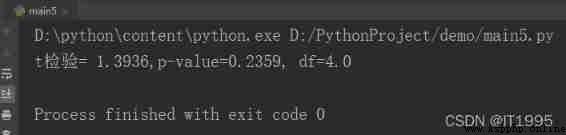
print('t test = %6.4f,p-value=%6.4f, df=%s' % d.ttest_mean(0.10))
pass
The running screenshot is as follows :
Among them, let's take a look ttest_mean This function
def ttest_mean(self, value=0, alternative="two-sided"):
"""ttest of Null hypothesis that mean is equal to value.
The alternative hypothesis H1 is defined by the following
- 'two-sided': H1: mean not equal to value
- 'larger' : H1: mean larger than value
- 'smaller' : H1: mean smaller than value
Parameters
----------
value : float or array
the hypothesized value for the mean
alternative : str
The alternative hypothesis, H1, has to be one of the following:
- 'two-sided': H1: mean not equal to value (default)
- 'larger' : H1: mean larger than value
- 'smaller' : H1: mean smaller than value
Returns
-------
tstat : float
test statistic
pvalue : float
pvalue of the t-test
df : int or float
"""
# TODO: check direction with R, smaller=less, larger=greater
tstat = (self.mean - value) / self.std_mean
dof = self.sum_weights - 1
# TODO: use outsourced
if alternative == "two-sided":
pvalue = stats.t.sf(np.abs(tstat), dof) * 2
elif alternative == "larger":
pvalue = stats.t.sf(tstat, dof)
elif alternative == "smaller":
pvalue = stats.t.cdf(tstat, dof)
return tstat, pvalue, dofThe following points need to be noted :
①ttest_mean Yes 2 Parameters , One is value, General biography array go in , The second parameter is 3 It's worth , Namely :
"two-sided": Not equal to value;( Default )
"larger": Greater than value;
"smaller": Less than value;② The return value is 3 Parameters :
tstat : float :t Test value , The larger the description, the more reasonable
pvalue : float :p-value value , Compare with the set significance level , Prove this passed in parameter value Is it reasonable? ;
df : int or float : What is the data type above float still int, Keep a few decimal places ;