Here we need to know a few concepts !
mean value ( Average ): The average of a set of data , For example, my favorite average score in my student days ;
variance : The degree to which a set of data deviates from the average ;
Standard deviation ( Standard error ): Variance open root sign , Reflect the dispersion of data ;
confidence interval : Statistical data error range , So there is an upper and lower value , For example, it is written on agricultural products 5kg±5%.
Confidence level : Credible probability , For example, the confidence level is 95%, Such as 100 Data , Yes 95 Data is on the above confidence interval .
① Calculating mean ;
② Find standard error ;
③ Look up the table z value , The following table :
Confidence level |z| value 90%1.6495%1.9699%2.58④ Calculate the confidence interval :
a = Sample mean - |z| * Standard deviation
b = Sample mean +|z| * Standard deviation
The following code :
import numpy as np
from scipy import stats
valueList = [95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 200]
if __name__ == '__main__':
averageValue = np.mean(valueList)
print(" The sample mean is :", averageValue)
standardError = stats.sem(valueList)
print(" The sample standard error is :", standardError)
a = averageValue - 1.96 * standardError
b = averageValue + 1.96 * standardError
print(" Interval estimate :[", a, "," ,b, "]")
passThe running screenshot is as follows :
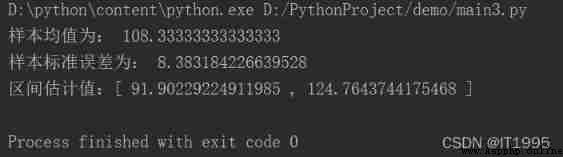
Available information :
① The average value of the sample is 108.33;
② The dispersion degree of the sample is 8.38;
③ The confidence level here is 95%, Corresponding |z| The value is 1.96;
④ Yes 95% Probability , The overall sample will fall to 91.90~124.76 In this range .