六、使用 BeautifulSoup 解析 HTML 頁面代碼
1,基本介紹
簡單來說, Beautiful Soup 就是 Python 的一個 HTML 或 XML 的解析庫,使用它可以很方便地從網頁中提取數據。
- Beautiful Soup 提供一些簡單的、Python 式的函數來處理導航、搜索、修改分析樹等功能。它是一個工具箱,通過解析文檔為用戶提供需要抓取的數據,因為簡單,所以不需要多少代碼就可以寫出一個完整的應用程序。
- Beautiful Soup 自動將輸入文檔轉換為 Unicode 編碼,輸出文檔轉換為 UTF-8 編碼。你不需要考慮編碼方式,除非文檔沒有指定一個編碼方式,這時你僅僅需要說明一下原始編碼方式就可以了。
- Beautiful Soup 已成為和 lxml、html6lib 一樣出色的 Python 解釋器,為用戶靈活地提供不同的解析策略或強勁的速度。
2,基本用法
(1)通過標簽查找對象
soup.a 和 soup.find('a') #查找第一個a標簽,返回值就是一個tag對象。
soup.find('a', {'class':'title abc'}) #查找第一個css的class為title abc的a標簽,返回值就是一個tag對象。
soup.find_all('a') #查找所有的a標簽,返回一個tag對象集合的list。
soup.find_all('a', class='name') #查找class這個屬性為name的a標簽,返回一個tag對象集合的list。
soup.find_all('a', limit=3) #查找三個a標簽,返回一個tag對象集合的list。
soup.find_all(text="") #查找text為某個字符串的結果,返回一個tag對象集合的list。
soup.find_all(["p", "span"]) # 查找p節點和span節點
soup.find_all(class_=re.compile("^p")) # 正則錶達式(查找class屬性值以p開頭的節點)
#其他find方法
find_parent #查找父節點
find_parents #遞歸查找父節點
find_next_siblings #查找後面的兄弟節點
find_next_sibling #查找後面滿足條件的第一個兄弟節點
find_all_next #查找後面所有節點
find_next #查找後面第一個滿足條件的節點
find_all_previous #查找前面所有滿足條件的節點
find_previous #查找前面第一個滿足條件的節點 (2)通過 CSS 選擇器查找對象
# select 與 select_one
soup.select("a") #查找所有的a標簽,返回一個tag對象集合的list
soup.select_one("a") #查找第一個a標簽,返回一個tag對象
# 通過tag選擇
soup.select("title") # 選擇title節點
soup.select("body a") # 選擇body節點下的所有a節點
soup.select("html head title") # 選擇html節點下的head節點下的title節點
# id與類選擇器
soup.select(".article") # 選擇類名為article的節點
soup.select("a#id1") # 選擇id為id1的a節點
soup.select("#id1") # 選擇id為id1的節點
soup.select("#id1,#id2") # 選擇id為id1、id2的節點
# 屬性選擇器
soup.select('a[href]') # 選擇有href屬性的a節點
soup.select('a[href="http://hangge.com/get"]') # 選擇href屬性為http://hangge.com/get的a節點
soup.select('a[href^="http://hangge.com/"]') # 選擇href以http://hangge.com/開頭的a節點
soup.select('a[href$="png"]') # 選擇href以png結尾的a節點
soup.select('a[href*="china"]') # 選擇href屬性包含china的a節點
soup.select("a[href~=china]") # 選擇href屬性包含china的a節點
#其他選擇器
soup.select("div > p") # 父節點為div節點的p節點
soup.select("div + p") # 節點之前有div節點的p節點
soup.select("p~ul") # p節點之後的ul節點(p和ul有共同父節點)
soup.select("p:nth-of-type(3)") # 父節點中的第3個p節點 (3)獲取對象內容
soup.a['class'] 和 soup.a.get['class'] #獲取第一個a標簽的class屬性值。
soup.a.name #獲取第一個a標簽的名字。
soup.a.string #獲取第一個a標簽內非屬性的字符串,如果是在內的非屬性字符串,則必須是通過soup.a.get_text()獲取
soup.a.strings #獲取a標簽內非屬性的所有的字符串列錶。
soup.a.stripped_strings #獲取a標簽內非屬性的所有的字符串列錶,去除空白和空行。
soup.a.text 和 soup.a.get_text() #獲取第一個a標簽內非屬性的字符串。例如∶ abc_()獲取的是abc。
soup.a.attrs #獲取第一個a標簽的所有屬性。
3,使用樣例
(1)下面樣例我們要抓取 csdn 首頁的頭條熱點條目:
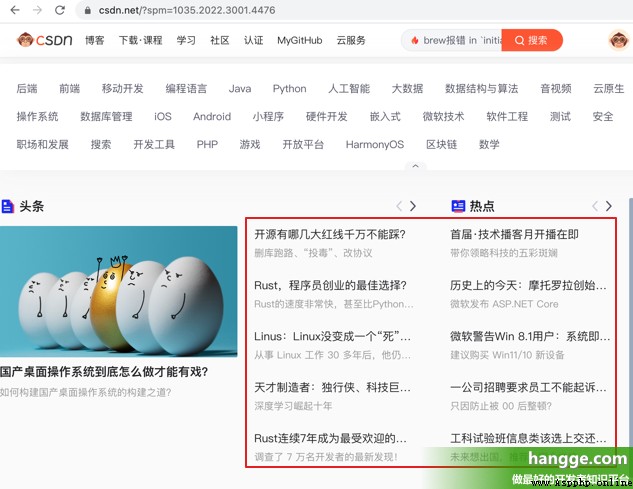
(2)查看頁面源代碼可以發現,各個條目標題都在 class 為 headswiper-item 的 div 下的第 1 個 a 標簽中:
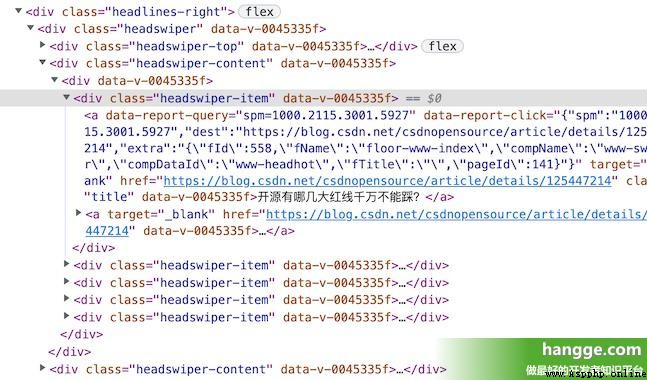
(3)下面是具體的代碼:
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.csdn.net")
soup = BeautifulSoup(response.text, "lxml")
items = soup.select(".headswiper-item")
for item in items:
print(item.a.text)
附:網頁爬蟲
1,准備工作
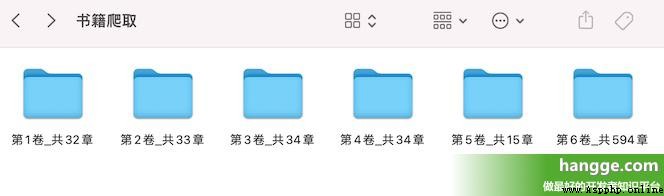
(1)這裏我們已抓取並下載起點小說網上的小說作為演示。首先找一部需要下載的小說,記下該小說的 bookId。
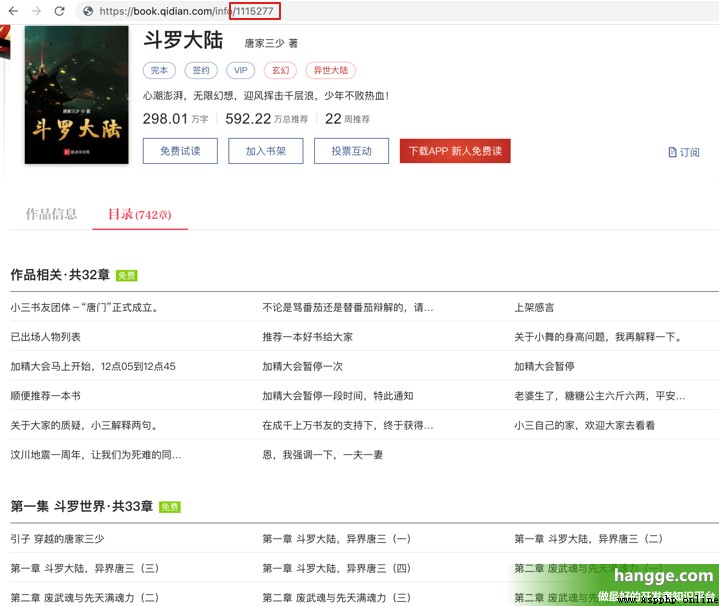
(2)接著 F12 打開瀏覽器控制臺,點擊 Network,再點擊 XHR,刷新頁面可以得到網頁的 csrfToken( bookId 也有):
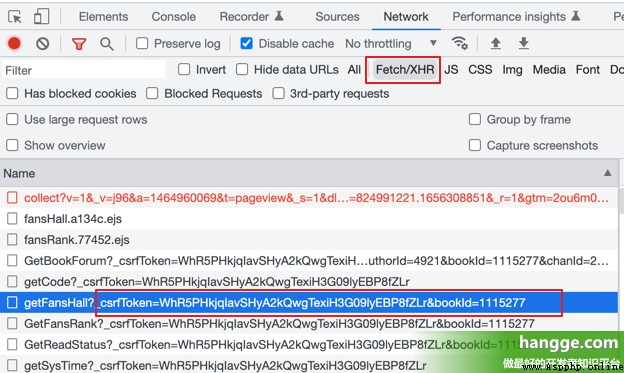
(3)我們訪問如下接口傳入前面獲取的 csrfToken 和 bookId 即可獲取整個小說的目錄。其中 vs 為所有的卷集合,每個卷下的 cs 為該卷所有的章節集合。
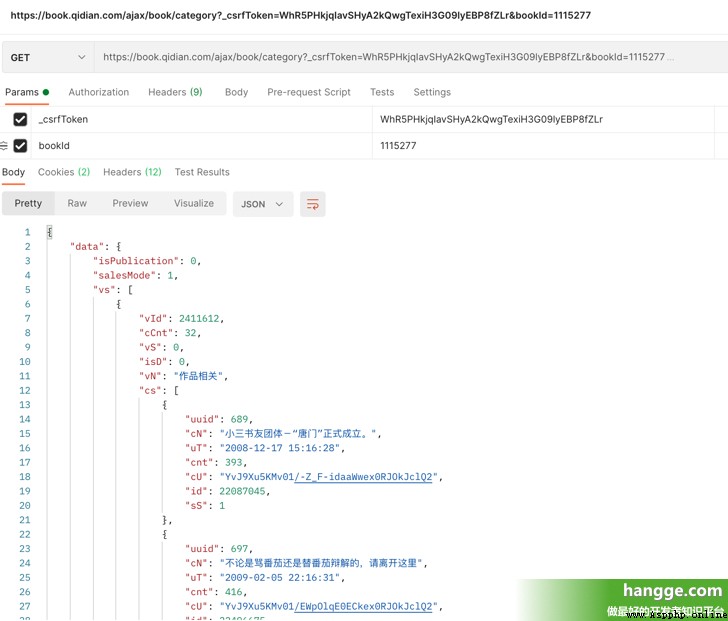
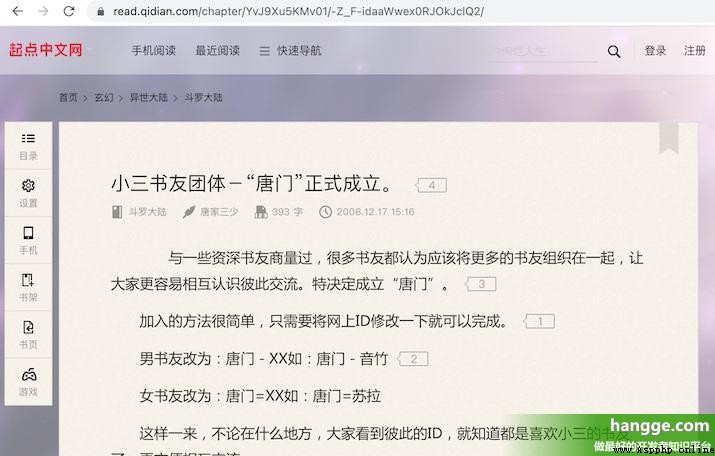
(4)每個章節的 cU 即為該章節頁面的地址,我們拼接上固定的前綴即可訪問該頁面,接下來只要解析該頁面內容,並保存到本地即可。
2,樣例代碼
(1)下面是爬蟲完整代碼,使用時只需要根據情況修改下 bookId、 csrfToken 以及下載文件保存地址即可:
import requests
import re
from bs4 import BeautifulSoup
from requests.exceptions import *
import random
import json
import time
import os
import sys
# 隨機返回list中的某個User Agent設置值,防止被禁
def get_user_agent():
list = ['Mozilla/5.0(Windows NT 10.0;Win64; x64)AppleWebKit/537.36(KHTML,like Gecko) Chrome/87.0.4280.66 Safari/537.36',
'Mozilla/5.0(Windows NT 6.3;Win64;x64)AppleWebKit/537.36 (KHTML,like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.2; Win64;x64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.1;Win64;x64AppleWebKit/537.36 (KHTML,like GeckoChrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0(Windows NT 6.3;WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0(Windows NT 6.2; WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0(Windows NT6.1; WOW64)AppleWebKit/537.36(KHTML, like Gecko)Chrome/41.0.2225.0 Safari/537.36']
return list[random.randint(0, len(list)-1)]
# 返回url網址上書籍的卷章(Page)id,每個卷章(Page)對應的章節(Chap)數目,以及章節頁面地址
def getPageAndChapUrl(bookId, csrfToken):
url ='https://book.qidian.com/ajax/book/category?_csrfToken=' + csrfToken + '&bookId=' + bookId
headers ={
'User-Agent': get_user_agent(),
'Referer':'https://book.qidian.com/info/' + bookId
}
try:
response = requests.get(url=url, params=headers)
if response.status_code == 200:
json_str = response.text
list = json.loads(json_str)['data']['vs']
volume ={
'VolumeId_List':[],
'VolumeNum_List':[],
'ChapterUrl_List':[]
}
for i in range(len(list)):
json_str = json.dumps(list[i]).replace(" ","")
volume_id =re.search('.*?"vId":(.*?),',json_str,re.S).group(1)
volume_num=re.search('.*?"cCnt":(.*?),',json_str,re.S).group(1)
volume['VolumeId_List'].append(volume_id)
volume['VolumeNum_List'].append(volume_num)
volume['ChapterUrl_List'].append([])
for j in range(len(list[i]['cs'])):
volume['ChapterUrl_List'][i].append(list[i]['cs'][j]['cU'])
print(volume)
return volume
else:
print('No response')
return None
except Exception as e:
print("請求頁面出錯!", e)
return None
#通過每個章節的頁面地址找到要爬取的頁面,並返回頁面html信息。
def getPage(savePath, volume, bookId):
for i in range(len(volume['VolumeId_List'])):
path = savePath + '/第'+ str(i + 1) + '卷_共'+ volume['VolumeNum_List'][i] +'章'
mkdir(path)
print('--- 第' + str(i+1) +'卷已開始爬取 ---')
for j in range(int(volume['VolumeNum_List'][i])):
url ='https://read.qidian.com/chapter/' + volume['ChapterUrl_List'][i][j]
print('正在爬取第' + str(i+1) + '卷第' + str(j+1) + '章路徑:'+url)
headers ={
'User-Agent': get_user_agent(),
'Referer':'https://book.qidian.com/info/' + bookId
}
try:
response = requests.get(url=url, params=headers)
if(response.status_code==200):
getChapAndSavetxt(response.text, url, path, j)
else:
print ('No response')
return None
except ReadTimeout:
print("ReadTimeout!")
return None
except RequestException:
print("請求頁面出錯!")
return None
time.sleep(5)
print('--- 第' + str(i+1) +'卷爬取結束 ---')
#解析小說內容頁面,將每章節(Chap)內容寫入txt文件,並存儲到相應的卷章(Page)目錄下。
# 其中,html為小說內容頁面;url為訪問路徑;path為卷章存儲路徑;chapNum為每個卷章Page對應的章節Chap數目
def getChapAndSavetxt(html, url, path, chapNum):
if html == None:
print('訪問路徑為'+url+'的頁面為空')
return
soup = BeautifulSoup(html,'lxml')
ChapName = soup.find('h3',attrs={'class':'j_chapterName'}).span.string
ChapName = re.sub('[\/:*?"<>]','',ChapName)
filename = path+'//'+'第'+ str(chapNum+1) +'章.' + ChapName + '.txt'
readContent = soup.find('div', attrs={'class':'read-content j_readContent'}).find_all('p')
paragraph = []
for item in readContent:
paragraph.append(re.search('.*?<p>(.*?)</p>',str(item),re.S).group(1))
save2file(filename, '\n'.join(paragraph))
# 將內容寫入文件。
# 其中,filename為存儲的文件路徑,content為要寫入的內容
def save2file(filename, content):
with open(r''+filename, 'w', encoding='utf-8') as f:
f.write(content)
# 創建卷章目錄文件夾。
# 其中,path為要創建的路徑
def mkdir(path):
folder = os.path.exists(path)
if(not folder):
os.makedirs(path)
else:
print('路徑“' + path + '”已存在')
# 主函數
def main(savePath, bookId, csrfToken):
volume = getPageAndChapUrl(bookId, csrfToken)
if (volume != None):
getPage(savePath, volume, bookId)
else:
print('無法爬取該小說!')
print("小說爬取完畢!")
# 調用主函數
savePath = '/Volumes/BOOTCAMP/書籍爬取' #文件保存路徑
bookId = '1115277' #小說id
csrfToken = 'WhR5PHkjqIavSHyA2kQwgTexiH3G09lyEBP8fZLr' #csrfToken
main(savePath, bookId, csrfToken)
(2)程序運行後控制臺信息如下,可以看到首先會獲取小說的目錄信息並進行解析,然後開始依次下載各章節頁面。


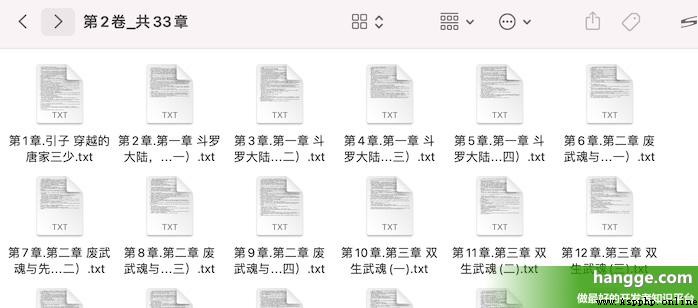
(3)查看下載目錄,可以看到各章節內容均以 txt 文檔的形式保存在各卷文件夾下了。