大家經常會遇到一些需要預測的場景,比如預測品牌銷售額,預測產品銷量。
今天給大家分享一波使用 LSTM 進行端到端時間序列預測的完整代碼和詳細解釋。
我們先來了解兩個主題:
什麼是時間序列分析?
什麼是 LSTM?
時間序列分析:時間序列表示基於時間順序的一系列數據。它可以是秒、分鐘、小時、天、周、月、年。未來的數據將取決於它以前的值。
在現實世界的案例中,我們主要有兩種類型的時間序列分析:
單變量時間序列
多元時間序列
對於單變量時間序列數據,我們將使用單列進行預測。
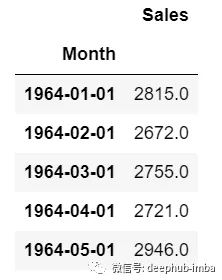
正如我們所見,只有一列,因此即將到來的未來值將僅取決於它之前的值。
但是在多元時間序列數據的情況下,將有不同類型的特征值並且目標數據將依賴於這些特征。
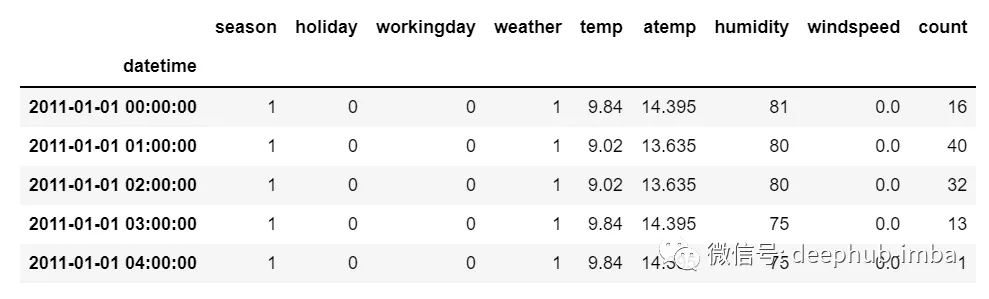
正如在圖片中看到的,在多元變量中將有多個列來對目標值進行預測。(上圖中“count”為目標值)
在上面的數據中,count不僅取決於它以前的值,還取決於其他特征。因此,要預測即將到來的count值,我們必須考慮包括目標列在內的所有列來對目標值進行預測。
在執行多元時間序列分析時必須記住一件事,我們需要使用多個特征預測當前的目標,讓我們通過一個例子來理解:
在訓練時,如果我們使用 5 列 [feature1, feature2, feature3, feature4, target] 來訓練模型,我們需要為即將到來的預測日提供 4 列 [feature1, feature2, feature3, feature4]。
LSTM
本文中不打算詳細討論LSTM。所以只提供一些簡單的描述,如果你對LSTM沒有太多的了解,可以參考我們以前發布的文章。
LSTM基本上是一個循環神經網絡,能夠處理長期依賴關系。
假設你在看一部電影。所以當電影中發生任何情況時,你都已經知道之前發生了什麼,並且可以理解因為過去發生的事情所以才會有新的情況發生。RNN也是以同樣的方式工作,它們記住過去的信息並使用它來處理當前的輸入。RNN的問題是,由於漸變消失,它們不能記住長期依賴關系。因此為了避免長期依賴問題設計了lstm。
現在我們討論了時間序列預測和LSTM理論部分。讓我們開始編碼。
讓我們首先導入進行預測所需的庫:
import numpy as npimport pandas as pdfrom matplotlib import pyplot as pltfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTMfrom tensorflow.keras.layers import Dense, Dropoutfrom sklearn.preprocessing import MinMaxScalerfrom keras.wrappers.scikit_learn import KerasRegressorfrom sklearn.model_selection import GridSearchCV加載數據,並檢查輸出:
df=pd.read_csv("train.csv",parse_dates=["Date"],index_col=[0])df.head()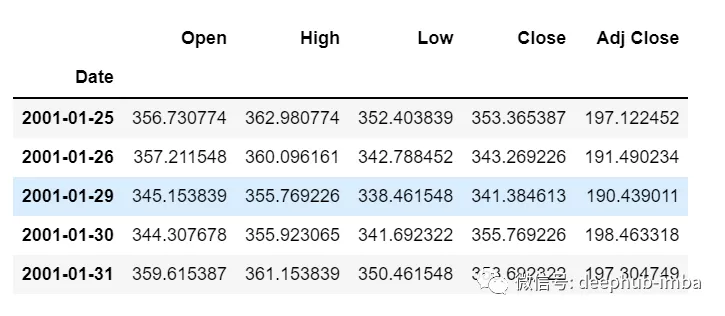
df.tail()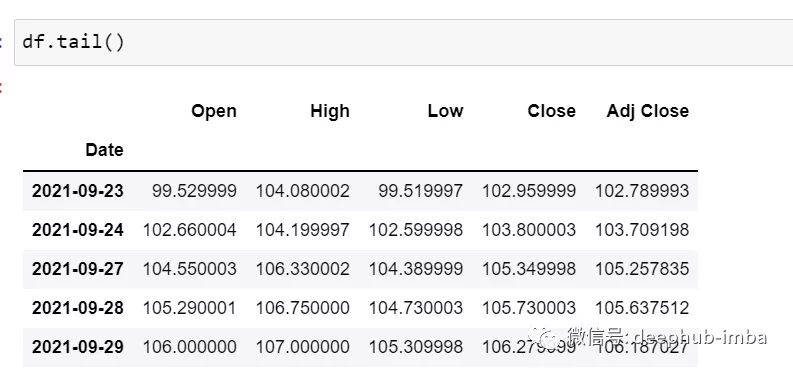
現在讓我們花點時間看看數據:csv文件中包含了谷歌從2001-01-25到2021-09-29的股票數據,數據是按照天數頻率的。
[如果您願意,您可以將頻率轉換為“B”[工作日]或“D”,因為我們不會使用日期,我只是保持它的現狀。]
這裡我們試圖預測“Open”列的未來值,因此“Open”是這裡的目標列。
讓我們看一下數據的形狀:
df.shape(5203,5)現在讓我們進行訓練測試拆分。這裡我們不能打亂數據,因為在時間序列中必須是順序的。
test_split=round(len(df)*0.20)df_for_training=df[:-1041]df_for_testing=df[-1041:]print(df_for_training.shape)print(df_for_testing.shape)(4162, 5)(1041, 5)可以注意到數據范圍非常大,並且它們沒有在相同的范圍內縮放,因此為了避免預測錯誤,讓我們先使用MinMaxScaler縮放數據。(也可以使用StandardScaler)
scaler = MinMaxScaler(feature_range=(0,1))df_for_training_scaled = scaler.fit_transform(df_for_training)df_for_testing_scaled=scaler.transform(df_for_testing)df_for_training_scaled
將數據拆分為X和Y,這是最重要的部分,正確閱讀每一個步驟。
def createXY(dataset,n_past): dataX = [] dataY = [] for i in range(n_past, len(dataset)): dataX.append(dataset[i - n_past:i, 0:dataset.shape[1]]) dataY.append(dataset[i,0]) return np.array(dataX),np.array(dataY)trainX,trainY=createXY(df_for_training_scaled,30)testX,testY=createXY(df_for_testing_scaled,30)讓我們看看上面的代碼中做了什麼:
N_past是我們在預測下一個目標值時將在過去查看的步驟數。
這裡使用30,意味著將使用過去的30個值(包括目標列在內的所有特性)來預測第31個目標值。
因此,在trainX中我們會有所有的特征值,而在trainY中我們只有目標值。
讓我們分解for循環的每一部分:
對於訓練,dataset = df_for_training_scaled, n_past=30
當i= 30:
data_X.addend (df_for_training_scaled[i - n_past:i, 0:df_for_training.shape[1]])從n_past開始的范圍是30,所以第一次數據范圍將是-[30 - 30,30,0:5] 相當於 [0:30,0:5]
因此在dataX列表中,df_for_training_scaled[0:30,0:5]數組將第一次出現。
現在, dataY.append(df_for_training_scaled[i,0])
i = 30,所以它將只取第30行開始的open(因為在預測中,我們只需要open列,所以列范圍僅為0,表示open列)。
第一次在dataY列表中存儲df_for_training_scaled[30,0]值。
所以包含5列的前30行存儲在dataX中,只有open列的第31行存儲在dataY中。然後我們將dataX和dataY列表轉換為數組,它們以數組格式在LSTM中進行訓練。
我們來看看形狀。
print("trainX Shape-- ",trainX.shape)print("trainY Shape-- ",trainY.shape)(4132, 30, 5)(4132,)print("testX Shape-- ",testX.shape)print("testY Shape-- ",testY.shape)(1011, 30, 5)(1011,)4132 是 trainX 中可用的數組總數,每個數組共有 30 行和 5 列, 在每個數組的 trainY 中,我們都有下一個目標值來訓練模型。
讓我們看一下包含來自 trainX 的 (30,5) 數據的數組之一 和 trainX 數組的 trainY 值:
print("trainX[0]-- \n",trainX[0])print("trainY[0]-- ",trainY[0])
如果查看 trainX[1] 值,會發現到它與 trainX[0] 中的數據相同(第一列除外),因為我們將看到前 30 個來預測第 31 列,在第一次預測之後它會自動移動 到第 2 列並取下一個 30 值來預測下一個目標值。
讓我們用一種簡單的格式來解釋這一切:
trainX — — →trainY[0 : 30,0:5] → [30,0][1:31, 0:5] → [31,0][2:32,0:5] →[32,0]像這樣,每個數據都將保存在 trainX 和 trainY 中。
現在讓我們訓練模型,我使用 girdsearchCV 進行一些超參數調整以找到基礎模型。
def build_model(optimizer): grid_model = Sequential() grid_model.add(LSTM(50,return_sequences=True,input_shape=(30,5))) grid_model.add(LSTM(50)) grid_model.add(Dropout(0.2)) grid_model.add(Dense(1))grid_model.compile(loss = 'mse',optimizer = optimizer) return grid_modelgrid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(testX,testY))parameters = {'batch_size' : [16,20], 'epochs' : [8,10], 'optimizer' : ['adam','Adadelta'] }grid_search = GridSearchCV(estimator = grid_model, param_grid = parameters, cv = 2)如果你想為你的模型做更多的超參數調整,也可以添加更多的層。但是如果數據集非常大建議增加 LSTM 模型中的時期和單位。
在第一個 LSTM 層中看到輸入形狀為 (30,5)。它來自 trainX 形狀。
(trainX.shape[1],trainX.shape[2]) → (30,5)現在讓我們將模型擬合到 trainX 和 trainY 數據中。
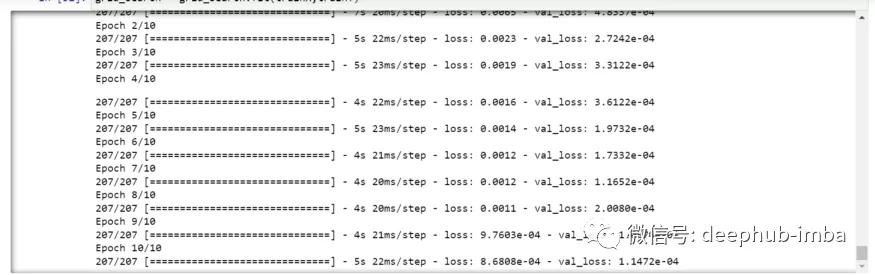
grid_search = grid_search.fit(trainX,trainY)由於進行了超參數搜索,所以這將需要一些時間來運行。
你可以看到損失會像這樣減少:
現在讓我們檢查模型的最佳參數。
grid_search.best_params_{‘batch_size': 20, ‘epochs': 10, ‘optimizer': ‘adam'}將最佳模型保存在 my_model 變量中。
my_model=grid_search.best_estimator_.model現在可以用測試數據集測試模型。
prediction=my_model.predict(testX)print("prediction\n", prediction)print("\nPrediction Shape-",prediction.shape)
testY 和 prediction 的長度是一樣的。現在可以將 testY 與預測進行比較。
但是我們一開始就對數據進行了縮放,所以首先我們必須做一些逆縮放過程。
scaler.inverse_transform(prediction)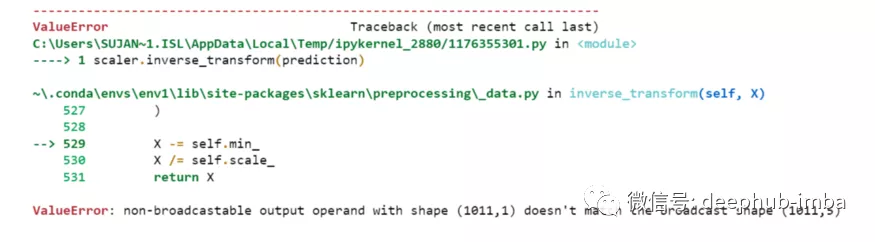
報錯了,這是因為在縮放數據時,我們每行有 5 列,現在我們只有 1 列是目標列。
所以我們必須改變形狀來使用 inverse_transform:
prediction_copies_array = np.repeat(prediction,5, axis=-1)
5 列值是相似的,它只是將單個預測列復制了 4 次。所以現在我們有 5 列相同的值 。
prediction_copies_array.shape(1011,5)這樣就可以使用 inverse_transform 函數。
pred=scaler.inverse_transform(np.reshape(prediction_copies_array,(len(prediction),5)))[:,0]但是逆變換後的第一列是我們需要的,所以我們在最後使用了 → [:,0]。
現在將這個 pred 值與 testY 進行比較,但是 testY 也是按比例縮放的,也需要使用與上述相同的代碼進行逆變換。
original_copies_array = np.repeat(testY,5, axis=-1)original=scaler.inverse_transform(np.reshape(original_copies_array,(len(testY),5)))[:,0]現在讓我們看一下預測值和原始值:
print("Pred Values-- " ,pred)print("\nOriginal Values-- " ,original)
最後繪制一個圖來對比我們的 pred 和原始數據。
plt.plot(original, color = 'red', label = 'Real Stock Price')plt.plot(pred, color = 'blue', label = 'Predicted Stock Price')plt.title('Stock Price Prediction')plt.xlabel('Time')plt.ylabel('Google Stock Price')plt.legend()plt.show()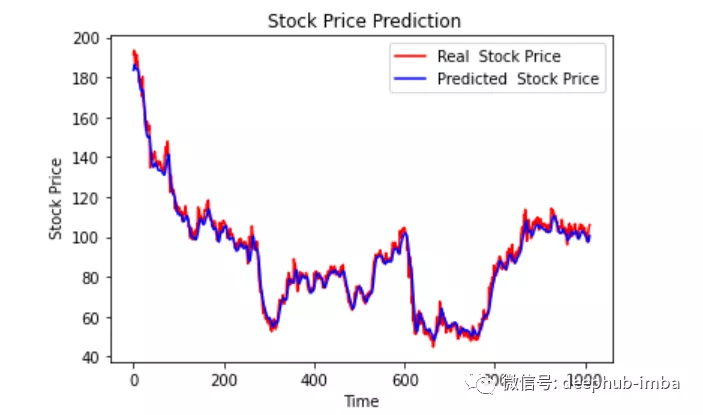
看樣子還不錯,到目前為止,我們訓練了模型並用測試值檢查了該模型。現在讓我們預測一些未來值。
從主 df 數據集中獲取我們在開始時加載的最後 30 個值[為什麼是 30?因為這是我們想要的過去值的數量,來預測第 31 個值]
df_30_days_past=df.iloc[-30:,:]df_30_days_past.tail()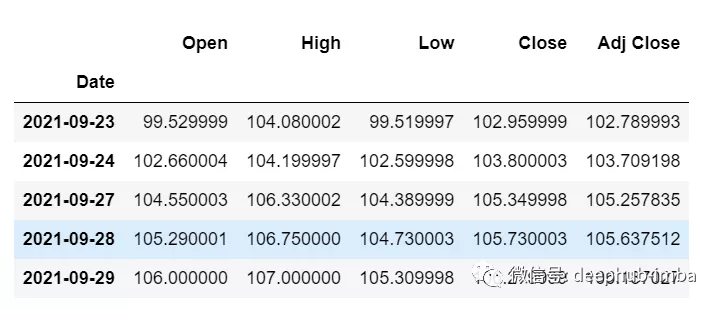
可以看到有包括目標列(“Open”)在內的所有列。現在讓我們預測未來的 30 個值。
在多元時間序列預測中,需要通過使用不同的特征來預測單列,所以在進行預測時我們需要使用特征值(目標列除外)來進行即將到來的預測。
這裡我們需要“High”、“Low”、“Close”、“Adj Close”列的即將到來的 30 個值來對“Open”列進行預測。
df_30_days_future=pd.read_csv("test.csv",parse_dates=["Date"],index_col=[0])df_30_days_future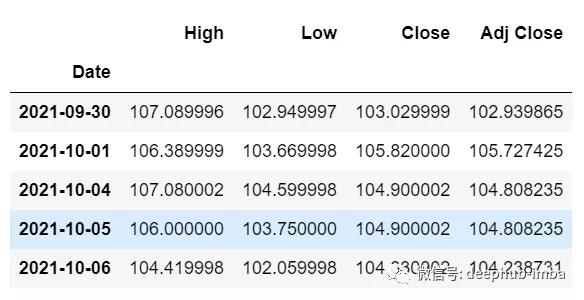
剔除“Open”列後,使用模型進行預測之前還需要做以下的操作:
縮放數據,因為刪除了‘Open’列,在縮放它之前,添加一個所有值都為“0”的Open列。
縮放後,將未來數據中的“Open”列值替換為“nan”
現在附加 30 天舊值和 30 天新值(其中最後 30 個“打開”值是 nan)
df_30_days_future["Open"]=0df_30_days_future=df_30_days_future[["Open","High","Low","Close","Adj Close"]]old_scaled_array=scaler.transform(df_30_days_past)new_scaled_array=scaler.transform(df_30_days_future)new_scaled_df=pd.DataFrame(new_scaled_array)new_scaled_df.iloc[:,0]=np.nanfull_df=pd.concat([pd.DataFrame(old_scaled_array),new_scaled_df]).reset_index().drop(["index"],axis=1)full_df 形狀是 (60,5),最後第一列有 30 個 nan 值。
要進行預測必須再次使用 for 循環,我們在拆分 trainX 和 trainY 中的數據時所做的。但是這次我們只有 X,沒有 Y 值。
full_df_scaled_array=full_df.valuesall_data=[]time_step=30for i in range(time_step,len(full_df_scaled_array)): data_x=[] data_x.append( full_df_scaled_array[i-time_step :i , 0:full_df_scaled_array.shape[1]]) data_x=np.array(data_x) prediction=my_model.predict(data_x) all_data.append(prediction) full_df.iloc[i,0]=prediction對於第一個預測,有之前的 30 個值,當 for 循環第一次運行時它會檢查前 30 個值並預測第 31 個“Open”數據。
當第二個 for 循環將嘗試運行時,它將跳過第一行並嘗試獲取下 30 個值 [1:31] 。這裡會報錯錯誤因為Open列最後一行是 “nan”,所以需要每次都用預測替換“nan”。
最後還需要對預測進行逆變換:
new_array=np.array(all_data)new_array=new_array.reshape(-1,1)prediction_copies_array = np.repeat(new_array,5, axis=-1)y_pred_future_30_days = scaler.inverse_transform(np.reshape(prediction_copies_array,(len(new_array),5)))[:,0]print(y_pred_future_30_days)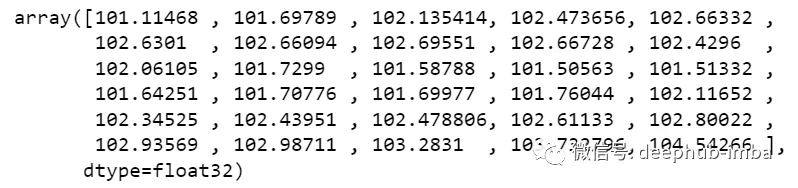
這樣一個完整的流程就已經跑通了。
到此這篇關於Python使用LSTM實現銷售額預測詳解的文章就介紹到這了,更多相關Python LSTM銷售額預測內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!