1、概括
本文主要使用python編程,使用requests庫獲取網頁內容,利用BeautifulSoup實現html文本解析查找我們想要得數據信息,使用pandas最終將我們獲取得數據持久化存儲到txt文本文件中。
3、預習
在開始案例之前,我們來掌握一下主要使用到的api接口:
# url:網址
# headers:請求頭數據字典
# return:返回網頁信息
requests.get(url=url, headers=headers)
# dl:標簽名稱
# attrs:標簽的屬性及屬性值字典
# return:返回其全部的查到符合要求的數據節點
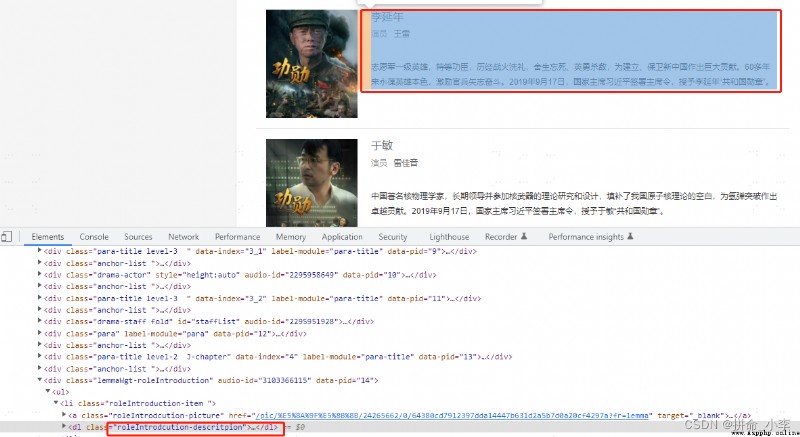
bs1.find_all('dl',attrs={'class':'roleIntrodcution-descritpion'})
注意:find_all使用前是需要使用BeautifulSoup轉化requests的文本內容
4、分析
我們需要對其網址的html進行分析,F12查看其中角色名、演員名、介紹、圖片的節點標簽名和節點的class屬性值或者id值 ,從而獲取其所在位置數據。通過F12查看元素可看到除了圖片網址其他信息都在其節點內部dl標簽,class為roleIntrodcution-descritpion的父節點下。同樣的方式我們分別查看一下角色名稱、演員名稱、介紹信息的對應節點。
# 角色名
find_all('div',attrs={'class':'role-name'})
# 演員名
find_all('div',attrs={'class':'role-actor'})
# 描述
find_all('dd',attrs={'class':'role-description'})
# 圖片信息
find_all('a',attrs={'class':'roleIntrodcution-picture'})
5、案例實現
#導包
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
url = 'https://baike.baidu.com/item/%E5%8A%9F%E5%8B%8B/24265662?fr=aladdin#8'
response = requests.get(url=url, headers=headers)
#step_3:獲取響應數據:通過調用響應對象的text屬性
page_text = response.text
from bs4 import BeautifulSoup
bs1 = BeautifulSoup(page_text, 'html.parser')
# 名稱
name = []
# 演員名稱
real_name = []
# 介紹
instruct=[]
for i in bs1.find_all('dl',attrs={'class':'roleIntrodcution-descritpion'}):
for j in i.find_all('div',attrs={'class':'role-name'}):
name.append(j.text.replace('\n',''))
for j in i.find_all('div',attrs={'class':'role-actor'}):
real_name.append(j.text.replace('\n','').replace('演員',''))
for i in bs1.find_all('dd',attrs={'class':'role-description'}):
instruct.append(i.text.replace('\n',''))
# 照片下載路徑
pic = []
for i in bs1.find_all('a',attrs={'class':'roleIntrodcution-picture'}):
pic.append(i.find('img').get('src'))
data={'角色姓名':name,'演員':real_name,'角色簡介':instruct,'角色劇照':pic}
import pandas as pd
df = pd.DataFrame(data,columns=['角色姓名', '演員','角色簡介','角色劇照'])
df.to_csv('data.txt', sep=' ',index=False)6、結果
# data.txt 文件名
# sep列分格
# index是否顯示索引
df.to_csv('data.txt', sep=' ',index=False)