1、 Generalization
This article mainly uses python Programming , Use requests Library to get web page content , utilize BeautifulSoup Realization html Text parsing to find the data we want , Use pandas Finally, the obtained data will be persisted and stored in txt In the text file .
3、 preview
Before starting the case , Let's take a look at the main api Interface :
# url: website
# headers: Request header data dictionary
# return: Return Web Information
requests.get(url=url, headers=headers)
# dl: Tag name
# attrs: Attribute and attribute value Dictionary of tag
# return: Return all the data nodes that meet the requirements
bs1.find_all('dl',attrs={'class':'roleIntrodcution-descritpion'})
Be careful :find_all Before use, it is necessary to use BeautifulSoup conversion requests Text content of
4、 analysis
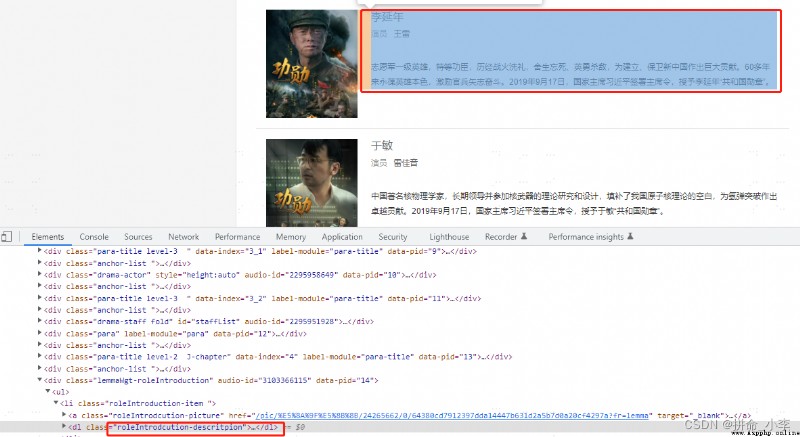
We need to check the website html Analyze ,F12 View the role name 、 Actor name 、 Introduce 、 Node tag name of the picture and node class Attribute value or id value , So as to obtain the location data . adopt F12 When you view the element, you can see that except for the image URL, other information is inside its node dl label ,class by roleIntrodcution-descritpion Under the parent node of . In the same way, let's look at the role names 、 Actor name 、 Introduce the corresponding nodes of the information .
# The role of
find_all('div',attrs={'class':'role-name'})
# Actor name
find_all('div',attrs={'class':'role-actor'})
# describe
find_all('dd',attrs={'class':'role-description'})
# Image information
find_all('a',attrs={'class':'roleIntrodcution-picture'})
5、 Case realization
# Guide pack
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
url = 'https://baike.baidu.com/item/%E5%8A%9F%E5%8B%8B/24265662?fr=aladdin#8'
response = requests.get(url=url, headers=headers)
#step_3: Get response data : By calling the... Of the response object text attribute
page_text = response.text
from bs4 import BeautifulSoup
bs1 = BeautifulSoup(page_text, 'html.parser')
# name
name = []
# Actor name
real_name = []
# Introduce
instruct=[]
for i in bs1.find_all('dl',attrs={'class':'roleIntrodcution-descritpion'}):
for j in i.find_all('div',attrs={'class':'role-name'}):
name.append(j.text.replace('\n',''))
for j in i.find_all('div',attrs={'class':'role-actor'}):
real_name.append(j.text.replace('\n','').replace(' actor ',''))
for i in bs1.find_all('dd',attrs={'class':'role-description'}):
instruct.append(i.text.replace('\n',''))
# Photo download path
pic = []
for i in bs1.find_all('a',attrs={'class':'roleIntrodcution-picture'}):
pic.append(i.find('img').get('src'))
data={' Role name ':name,' actor ':real_name,' Role profile ':instruct,' Still photos of the characters ':pic}
import pandas as pd
df = pd.DataFrame(data,columns=[' Role name ', ' actor ',' Role profile ',' Still photos of the characters '])
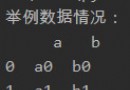
df.to_csv('data.txt', sep=' ',index=False)6、 result
# data.txt file name
# sep Column lattice
# index Show index or not
df.to_csv('data.txt', sep=' ',index=False)