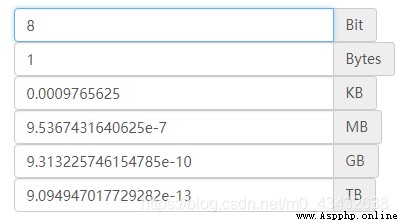
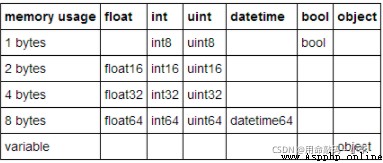
float64 Occupied memory is float32 Twice as many , yes float16 Of 4 times ; For example, for CIFAR10 Data sets , If the float64 To express , need 60000*32*32*3*8/1024**3=1.4G, Just putting data sets into memory requires 1.4G; If the float32, It only needs 0.7G, If the float16, It only needs 0.35G about ; How much memory does it take , It will have a serious impact on the operation efficiency of the system ;( Therefore, the data set files adopt uint8 To store data , Keep files to a minimum )
import numpy as np
data = np.array([1,2,3,4,5,6,7,8,9],dtype='float32')pandas The reason why the data processing speed is fast is that it loads the data into the memory for processing , Use pandas Load data to test different data types , Memory occupied by the same data ~
import pandas as pd
data = pd.DataFrame([1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9], dtype="float64")
data1 = pd.DataFrame([1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9], dtype="float32")
print(data.info(memory_usage=True))
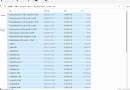
print(data1.info(memory_usage=True))The results are as follows , We just need to check the memory size ,float64 Data occupancy 192bytes,float32 Data occupancy 160bytes
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8 entries, 0 to 7
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 8 non-null float64
dtypes: float64(1)
memory usage: 192.0 bytes -----------------> Memory usage
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8 entries, 0 to 7
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 8 non-null float32
dtypes: float32(1)
memory usage: 160.0 bytes -----------------> Memory usage
None